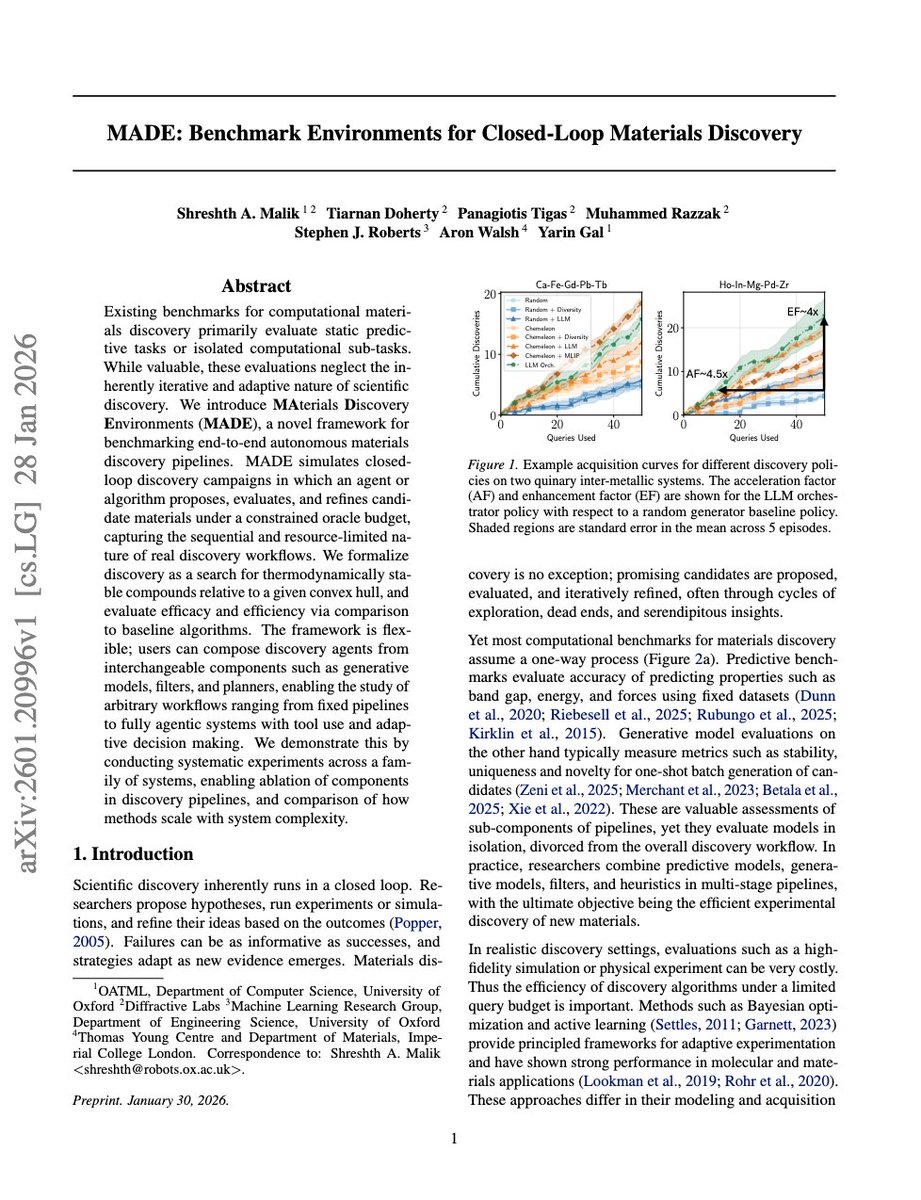
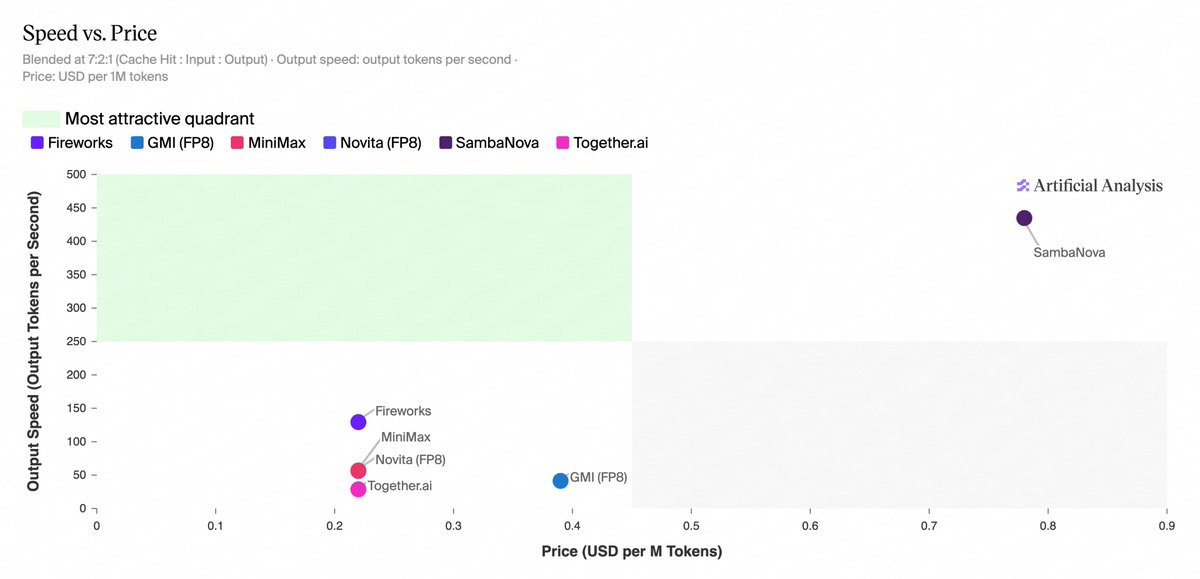
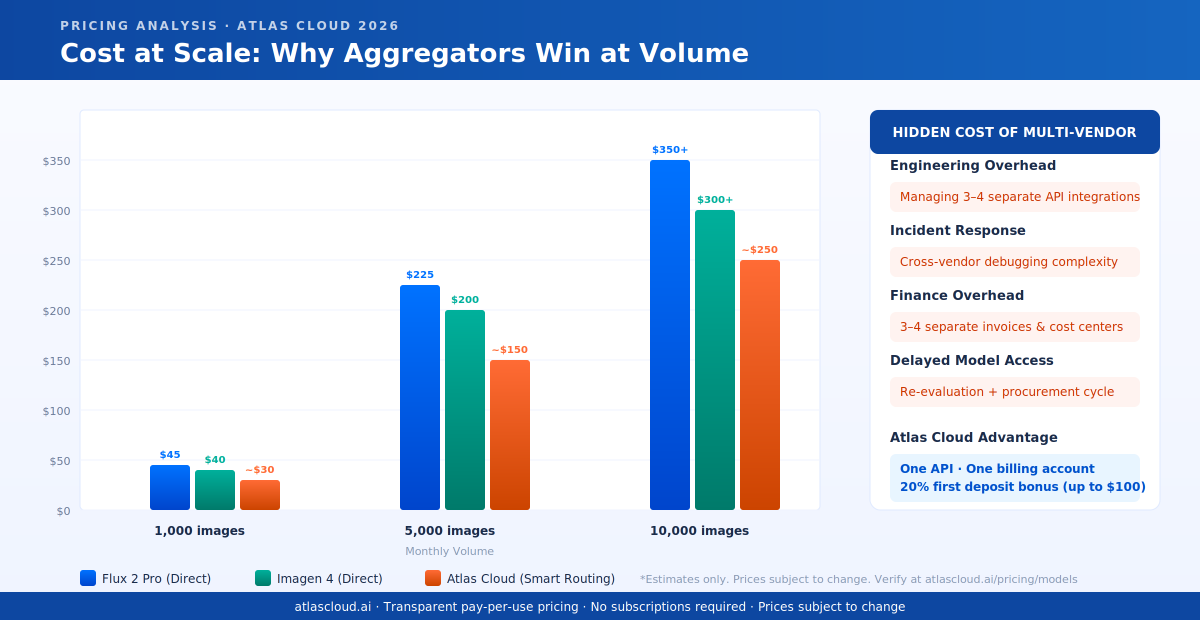
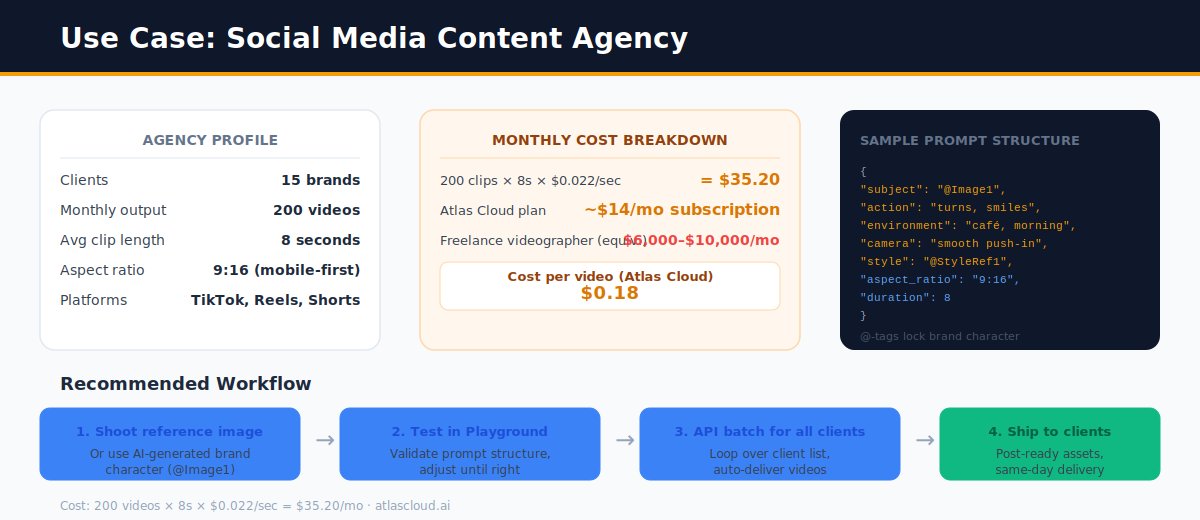
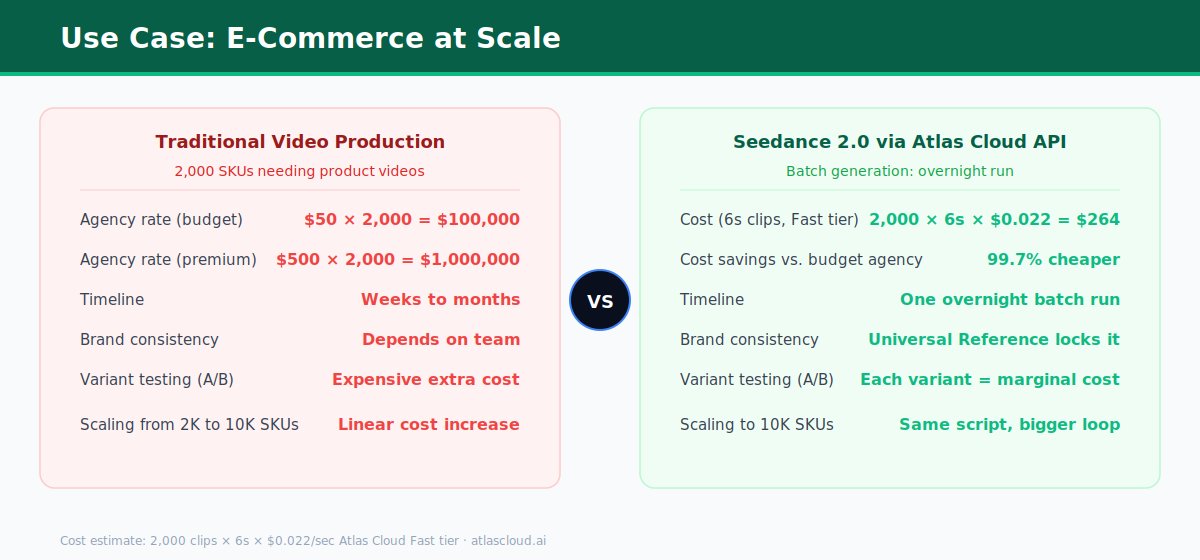
@reach_vb What's the typical lag for inference providers to expose new OpenAI models? GPT-5.5 hit most aggregators within 24-48h, but realtime-2 still feels patchy on the routing layer. Curious where the bottleneck actually is — model weights access, pricing terms, or auth schema drift?
English