Sabitlenmiş Tweet

✈️ Landed in San Diego for #NeurIPS2025! ☀️
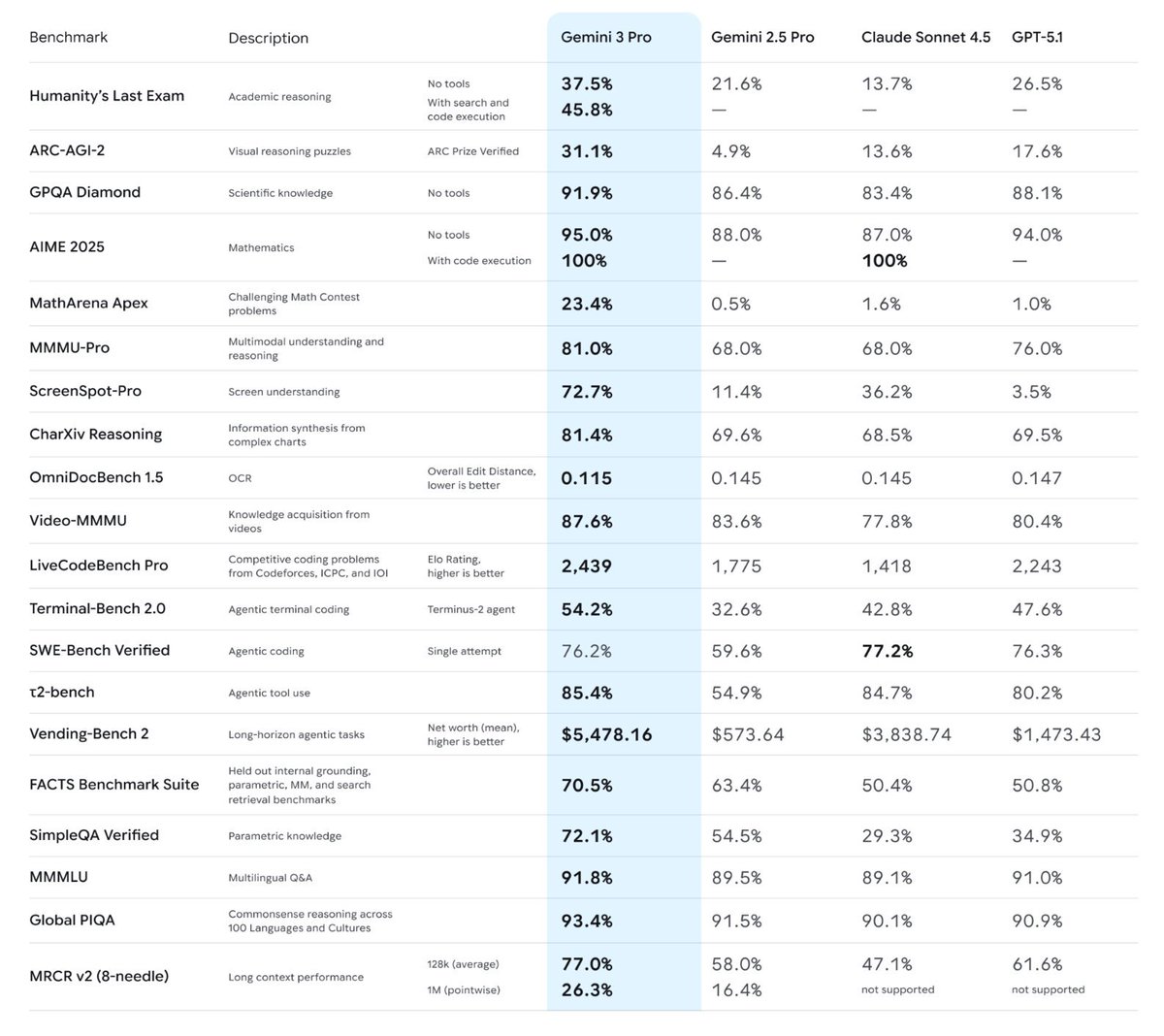
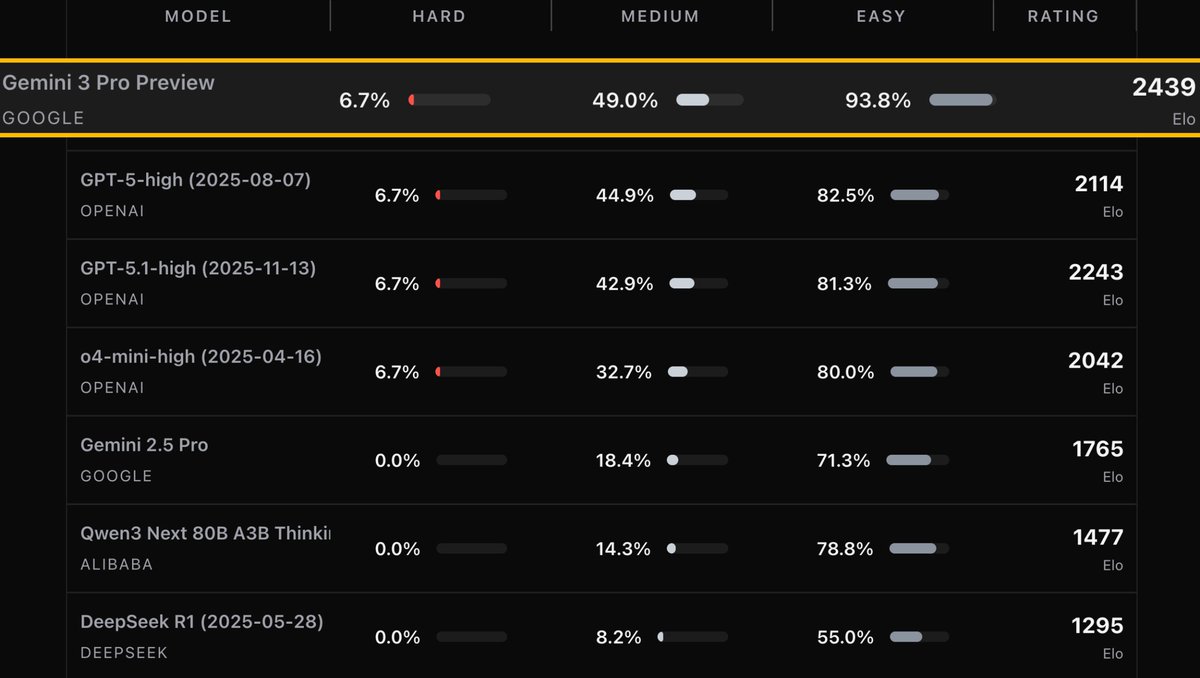
🔹Dec 3: 2 Main Conf Posters (PeerBench & LiveCodeBench Pro) 🔹Dec 4: Talk @ OpenAGI Symposium (📍Sparks Gallery)
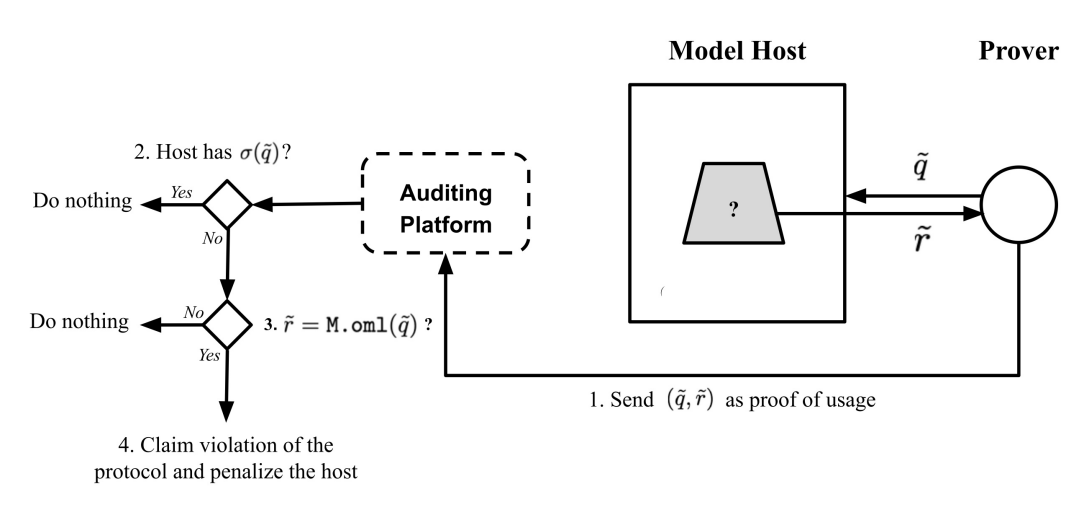
🔹 Dec 6: Poster @ Lock-LLM Workshop (OML)
Feel free to drop by, say hi and exchange insights on AI eval or blockchains!



English