Sabitlenmiş Tweet

Elle se prostituait et toi au lieu de te prostituer à sa place pour l’aider dans sa galère tu viens tweeter ici 🤦♂️
إسكندر@hustlehard213
Elle se prostituait
Français
on ne blague plus
3.1K posts

@Zhydrvx_
Moi tout qu'est ce que j'sais, c'est que j'cours pas plus vite que les balles. Je hais le Crous.
Elle se prostituait



Redbull a 10 centime qui ça intéresse ? Carrefour et caisse auto obligatoire lol





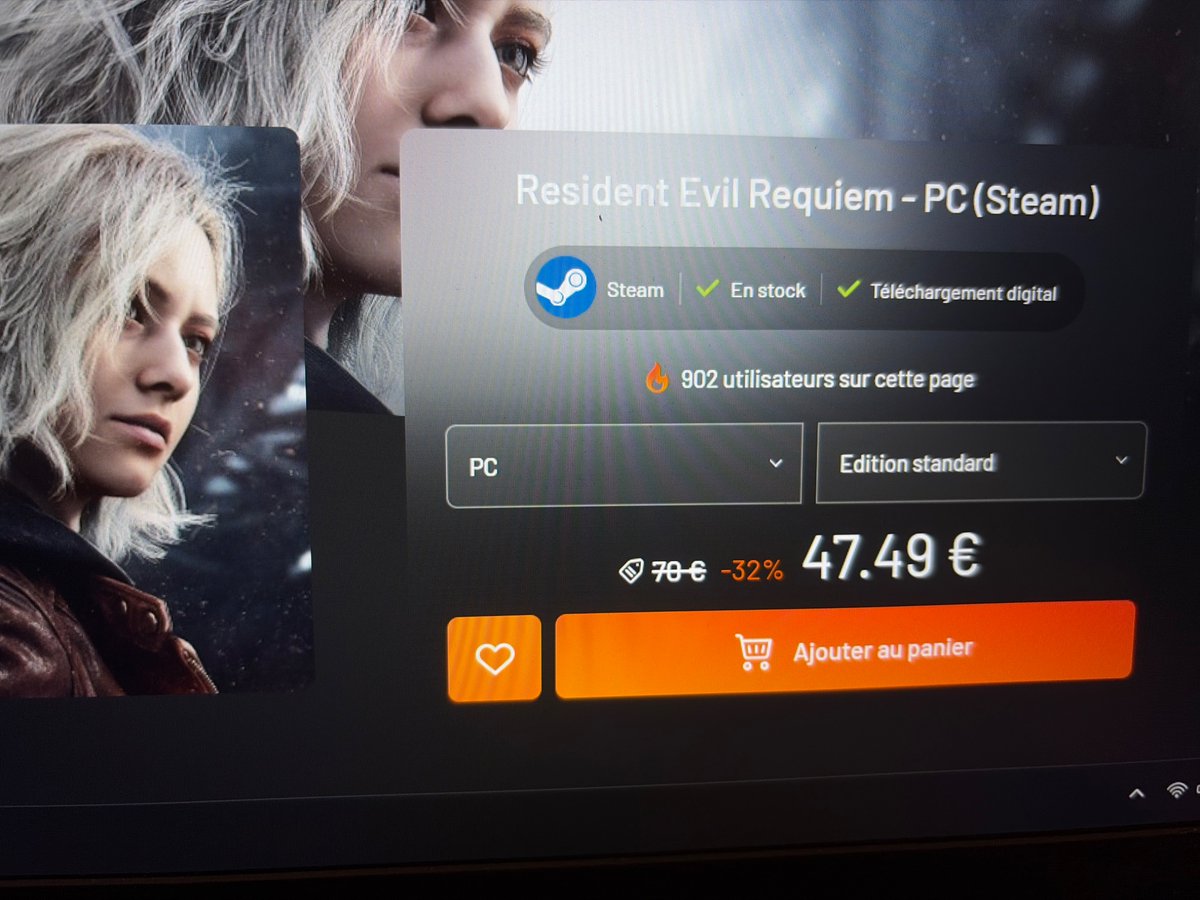
Lol c’est fini, il est temps de passer à de vrais jeux, On va commencer fort.



Netflix -19,99€ MACIF ASSURANCE -88,83€ Free Mobile -19,99€ Claude -22,99€ Basic Fit -24,99€ Apple -9,99€ Spotify -9,99€ Navigo -40,99€

meubler son premier appartement PARDON FALLAIT ME PRÉVENIR

On entend clairement le jeune dire : « On va manger là », car il y a un fast-food dans la rue marchande. Mais au lieu de cela, tout ce qu’il a reçu, ce sont des coups. Jusqu’à quand cela va-t-il continuer ? #NOISIEL #BAVUREPOLICIERE