Sabitlenmiş Tweet
Alguarito
3.8K posts



La canción “Melo”, presente en el álbum “OMERTA”, será un rock y tendrá referencias de Metallica.


Español

Como consumidora activa de conciertos de reggaetón hace unos 6 años, Maluma jamás se ha aparecido en Bogotá puntualmente siendo invitado, en Medellín mal contadas unas 7 veces ha estado, conclusión: no le gusta venir por acá
Juanjo Guerrero@Juanjo_guerrero
Maluma es invitado por Ryan Castro en su Atanasio Girardot #maluma #ryancastro
Español
@thsottiaux Después de hablar un rato en español, comienza a responder con acento argentino
Español



Lo que está claro es que es un mejor modelo a nivel de benchmarks y por el feedback que he ido viendo durante días de insiders de los que me fío y lo han estado probando. Bienvenido sea.
Eso sí, también es un modelo más caro.
x.com/ArtificialAnly…
Artificial Analysis@ArtificialAnlys
GPT-5.5 takes OpenAI back to the clear number one in AI. OpenAI’s new model tops the Artificial Analysis Intelligence Index by 3 points, breaking a three-way tie with Anthropic and Google OpenAI gave us pre-release access to test all five reasoning effort levels: xhigh, high, medium, low and non-reasoning. ➤ OpenAI topping five headline evaluations: GPT-5.5 (xhigh) leads Terminal-Bench Hard, GDPval-AA and our newly hosted APEX-Agents-AA. The model trails only other OpenAI models in CritPt and AA-LCR, and comes second to Gemini 3.1 Pro Preview on three additional evaluations. The largest gains are on AA-Omniscience (+14 pts), our knowledge and hallucination benchmark, and τ²-Bench Telecom (+7 pts), a customer service agent benchmark. ➤ 20% more expensive to run our Intelligence Index: Per-token pricing has doubled from GPT-5.4 to $5/$30 per 1M input/output tokens. However, a ~40% token use reduction largely absorbs the hike - resulting in a net ~+20% cost to run our Intelligence Index. ➤ Effort a clear ladder for balancing intelligence and cost: GPT-5.5 (medium) scores the same as Claude Opus 4.7 (max) on our Intelligence Index at one quarter of the cost (~$1,200 vs $4,800) - although Gemini 3.1 Pro Preview scores the same at a cost of ~$900. GPT-5.5 (low) approximates Claude Opus 4.7 (Non-reasoning, high) on our Intelligence Index at half the cost to run (~$500 vs ~$1 ,000). ➤ Number one in GDPval-AA with an Elo of 1785: GPT-5.5 (xhigh) leads Claude Opus 4.7 (max) by ~30 pts and Gemini 3.1 Pro Preview by ~470 pts. GDPval-AA is Artificial Analysis’ benchmark that leverages OpenAI’s GDPval dataset to evaluate models on real-world economically valuable tasks. ➤ Top AA-Omniscience accuracy, but trailing the frontier on hallucination: Our private AA-Omniscience benchmark rewards factual knowledge across diverse topics, but punishes hallucination. GPT-5.5 (xhigh) has the highest accuracy at 57% - meaning the model can recall facts in the Omniscience corpus more effectively than any other model. However, it has a hallucination rate of 86% - vs Opus 4.7 (max) at 36%, and Gemini 3.1 Pro Preview at 50%. This makes it more likely to answer a question when it does not ‘know’ the answer. The 14 pt gain in AA-Omniscience from GPT-5.4 (xhigh) was largely driven by knowledge, with a modest improvement in hallucination. Congratulations to the team at @OpenAI and @sama on the launch
Español
🔴 ¡OPENAI ANUNCIA GPT 5.5!
El nuevo modelo insignia de OpenAI ya está aquí, vamos a desgranar poco a poco las novedades.
Dentro hilo 🧵👇
Español
@Miguel_G_1_1 Lo bueno de tener artistas de talla mundial es que poco a poco los colombianos vamos aprendiendo que estos eventos más que conciertos son shows completos y que más allá de la música, vale la pena disfrutar de un gran espectáculo. Por eso es tan valiosa la gira de J Balvin por 🇨🇴
Español

Pueden odiar mucho a Karol G pero en shows y conciertos nunca falla, hasta los escenarios que crea son únicos y especiales como el de MSB
dinamarca@dinamarcavt
la seguridad que tiene el equipo de esta señora para hacer estadios en sitios donde no la escuchan lo suficiente como para llenar me parece algo tan extraño
Español
Más de 30 mil personas estuvieron ayer en el Estadio General Santander para asistir al show “Ciudad Primavera.”
— Próxima parada: Bucaramanga, 18 de abril.

Español

@_Alguarito @powerhdeleon Me interesa conocer de esto, estoy trabajando en un servicio en .NET precisamente para integrar en con ERP, lo tengo funcionando actualmente solo para facturación electronica.
Español

Tengo un servicio SOAP hecho con Windows Communication Foundation que nunca falla, rara vez he tenido que moverle, y sigue generando dinero, aun así, no se metan en las aguas del SOAP.
Español
@jacomasvirtual @powerhdeleon Por el nivel de encriptacion que maneja la DIAN es mejor que este servicio esté en Python
Español
@jacomasvirtual @powerhdeleon Con Claude hice una integración completa de mi ERP en 6 horas, con Matias API me costaba $3.000.000 al mes
Español
@powerhdeleon Acá en Colombia se usa para enviar facturas a la oficina de impuestos, es la cosa más espantosa que existe.
Español

@masterchima6 Que recuerdos, Bull, Mosty y Sky 🥹 y Bueno pope siempre estará, el de atrás es Tainy?
Español

Balvin ahora está trabajando con O’Neill, Michael brun, Keityn, Jeremy Ayala.
Pero Mi Team siempre será este
#jbalvin

Español

@_Alguarito @Lu_andri_ssj españa es igual o peor en tema de polarización
Español

Ibai no entiende que la razón del éxito del stream de ayer es porque Westcol fue Westcol. Si lo hiciera él, no sería lo mismo, porque no es un hombre polémico, y se dedicaría a leer lo que dice el chat, la pregunta de pq 🇨🇴 es potencia mundial en only fans no la hace ibai nunca.
𝒞𝓇𝒶𝓏𝓎𝓎⁶⁶⁶⚡️@crazymen6666
Ibai vio lo del stream de west con petro.
Español
@JulianA75772065 @ryancastrro @Tuboletaoficial Exacto, yo envié una PQRS la semana pasada porque ya tengo vuelos y estoy preocupado
Español

@ryancastrro Ryan o @Tuboletaoficial cuando cargan las entradas?
Español

Falta 1 mes para el mejor show que todos mis fans van a vivir ❤️ ya casi nos vemos medallo ❤️🥹🙏🏻
Español

@MathiasChu @matnalopez @NLF66323121 En mi negocio familiar llevamos un año con Odoo, esta semana me propuse construir de cero, los módulos que usamos (POS, Ventas, Compras, inventario, etc.). Como sólo usamos 1 usuario en Odoo, el reto es que el nuevo ERP, corra por menos de $10. En una semana tengo el ERP a un 40%
Español

@matnalopez @NLF66323121 voy a probarlo, te cuento el año que viene si me equivoqué o te equivocabas vos jajsjs
Español
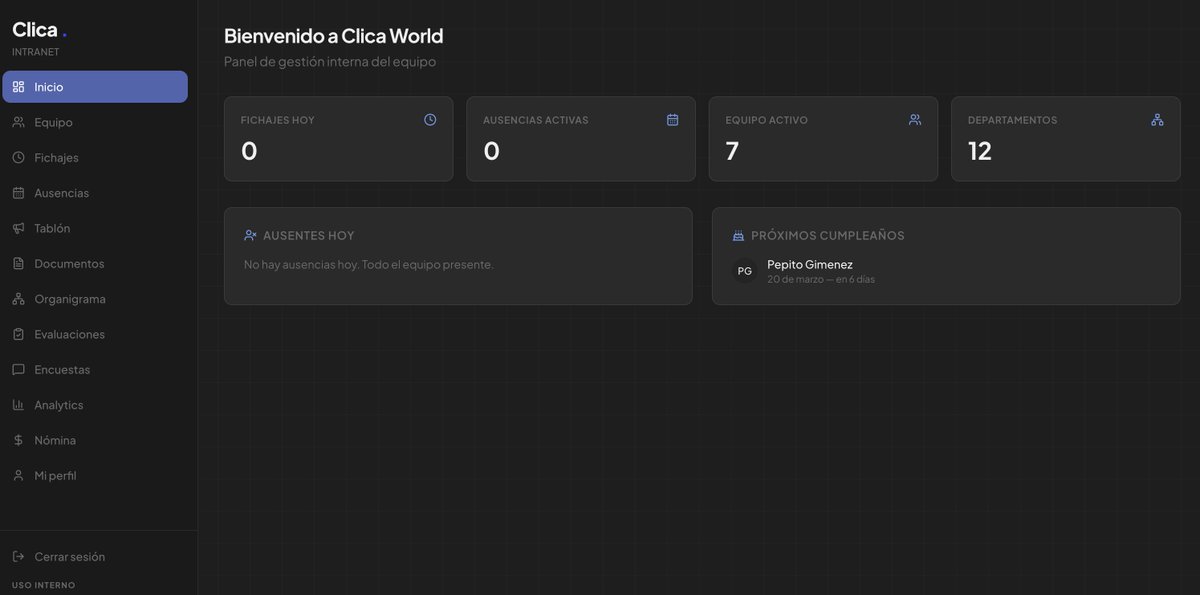
En la agencia tenemos contratado un software de HR con el que organizamos todo lo relacionado al equipo: horas por proyecto, vacaciones, ausencias, evaluaciones de desempeño, nps de cómo se sienten, avisos importantes, etc.
Me pregunté: puedo en poco tiempo armar algo similar, pero 100% enfocado en nuestras necesidades?
Y en unas 6 horas con claude armé una app con más de 10 features que estamos testeando (todavía falta algunas semanas para ponerlo en producción), pero realmente anda muy bien.
El stack: next js, prisma como ORM, supabase, shadcn/ui + tailwind css para UI, resend para emails transaccionales y vercel.
La era del software custom comenzó.
Español

Justo ayer conocí una empresa que usan disque Github Copilot. El más manco de las IAs.
(?)
Serudda (Español)@serudda_es
Deja de pensar que "todos ya están usando IA". No. La burbuja es diminuta. En Latam, microscópica. La mayoría de empresas siguen operando con la misma estructura de 2021. Los mismos equipos. Los mismos procesos. La misma velocidad. Cuando la ola real llegue. Cuando el mercado entero despierte y vea lo que un equipo de tres puede hacer contra uno de cuarenta, la urgencia no va a ser gradual. Va a ser un tsunami colectivo. Y los que hoy dicen "jaja, eso llevará un tiempo" van a ser los primeros en ahogarse.
Español

J Balvin en la previa de su concierto en Houston en el estadio NRG 🇺🇸👀



Español
@BrenCM5 @AlitzTzadkiel Sí claro, si estás en MX es mejor esperar, es como hace muchos años que MX era una versión (bastante) reducida de EDC Las Vegas. El complejo deportivo no llega ni a un 50% del espacio del autódromo.
(Estuve en EDC MX 2015)
Español

@AlitzTzadkiel Ufff, entonces creo que si será una versión muchísimo más reducida que Mx, habrá que esperar a ver cómo sale
Español