
MrMofer
54 posts


🚨Delincuentes armados fueron a apretar a un pibe que escracha y denuncia a cacos del Conurbano.
"Te gusta grabar a los guachos que andan robando??"
Ministra @AleMonteoliva haga lo suyo.
Español








@AlertaArgNews Hm mmmm chicos están celebrando la muerte de alguien?
Español

🚨⚠️ Delincuente se descuida y el ciudadano estaba armado
Español




MrMofer retweetledi




🔴 ¡NUEVO MODELO DE IMAGEN de CHATGPT!
Más preciso, más rápido y más controlable a través del prompt. Busca ser la respuesta ante Nano Banana Pro, y aunque mejora claramente al anterior modelo de ChatGPT, con pocas pruebas se ve que no llega a estar a la altura del de Google.
OpenAI@OpenAI
Introducing ChatGPT Images, powered by our flagship new image generation model. - Stronger instruction following - Precise editing - Detail preservation - 4x faster than before Rolling out today in ChatGPT for all users, and in the API as GPT Image 1.5.
Español

🚨🇳🇵 | INSÓLITO: Por primera vez en el mundo, Nepal eligió a su primer ministro interino a través de una votación en Discord, después de que la Generación Z derrocara al régimen comunista por prohibir las redes sociales.

Español


MrMofer retweetledi

TL;DR: We built a transformer-based payments foundation model. It works.
For years, Stripe has been using machine learning models trained on discrete features (BIN, zip, payment method, etc.) to improve our products for users. And these feature-by-feature efforts have worked well: +15% conversion, -30% fraud.
But these models have limitations. We have to select (and therefore constrain) the features considered by the model. And each model requires task-specific training: for authorization, for fraud, for disputes, and so on.
Given the learning power of generalized transformer architectures, we wondered whether an LLM-style approach could work here. It wasn’t obvious that it would—payments is like language in some ways (structural patterns similar to syntax and semantics, temporally sequential) and extremely unlike language in others (fewer distinct ‘tokens’, contextual sparsity, fewer organizing principles akin to grammatical rules).
So we built a payments foundation model—a self-supervised network that learns dense, general-purpose vectors for every transaction, much like a language model embeds words. Trained on tens of billions of transactions, it distills each charge’s key signals into a single, versatile embedding.
You can think of the result as a vast distribution of payments in a high-dimensional vector space. The location of each embedding captures rich data, including how different elements relate to each other. Payments that share similarities naturally cluster together: transactions from the same card issuer are positioned closer together, those from the same bank even closer, and those sharing the same email address are nearly identical.
These rich embeddings make it significantly easier to spot nuanced, adversarial patterns of transactions; and to build more accurate classifiers based on both the features of an individual payment and its relationship to other payments in the sequence.
Take card-testing. Over the past couple of years traditional ML approaches (engineering new features, labeling emerging attack patterns, rapidly retraining our models) have reduced card testing for users on Stripe by 80%. But the most sophisticated card testers hide novel attack patterns in the volumes of the largest companies, so they’re hard to spot with these methods.
We built a classifier that ingests sequences of embeddings from the foundation model, and predicts if the traffic slice is under an attack. It leverages transformer architecture to detect subtle patterns across transaction sequences. And it does this all in real time so we can block attacks before they hit businesses.
This approach improved our detection rate for card-testing attacks on large users from 59% to 97% overnight.
This has an instant impact for our large users. But the real power of the foundation model is that these same embeddings can be applied across other tasks, like disputes or authorizations.
Perhaps even more fundamentally, it suggests that payments have semantic meaning. Just like words in a sentence, transactions possess complex sequential dependencies and latent feature interactions that simply can’t be captured by manual feature engineering.
Turns out attention was all payments needed!
English
MrMofer retweetledi

it’s over
turns out the rl victory lap was premature. new tsinghua paper quietly shows the fancy reward loops just squeeze the same tired reasoning paths the base model already knew. pass@1 goes up, sure, but the model’s world actually shrinks. feels like teaching a kid to ace flash cards and calling it wisdom.
so the grand “self-improving llm” dream? basically crib notes plus a roulette wheel: keep sampling long enough and the base spits the same proofs the rl champ brags about, minus the entropy tax. it’s compression, not discovery.
maybe the endgame isn’t better agents, just sharper funnels. we’ve been coaching silicon parrots to clear increasingly useless olympiad hurdles while mistaking overfit for insight. hard not to wonder if we’re half a decade into the world’s most expensive curve-fitting demo.

English
MrMofer retweetledi


MrMofer retweetledi

BioSerenity-E1: a self-supervised EEG model for medical applications
"In the present paper, we introduce BioSerenity-E1, the first of a family of self-supervised foundation models for clinical EEG applications that combines spectral tokenization with masked prediction to achieve state of-the-art performance across relevant diagnostic tasks."

English
MrMofer retweetledi

This is a great high-level introduction to Hamiltonian Monte Carlo methods that I found very accessible.
It has great visual explanations of a variety of relevant concepts.

English
MrMofer retweetledi

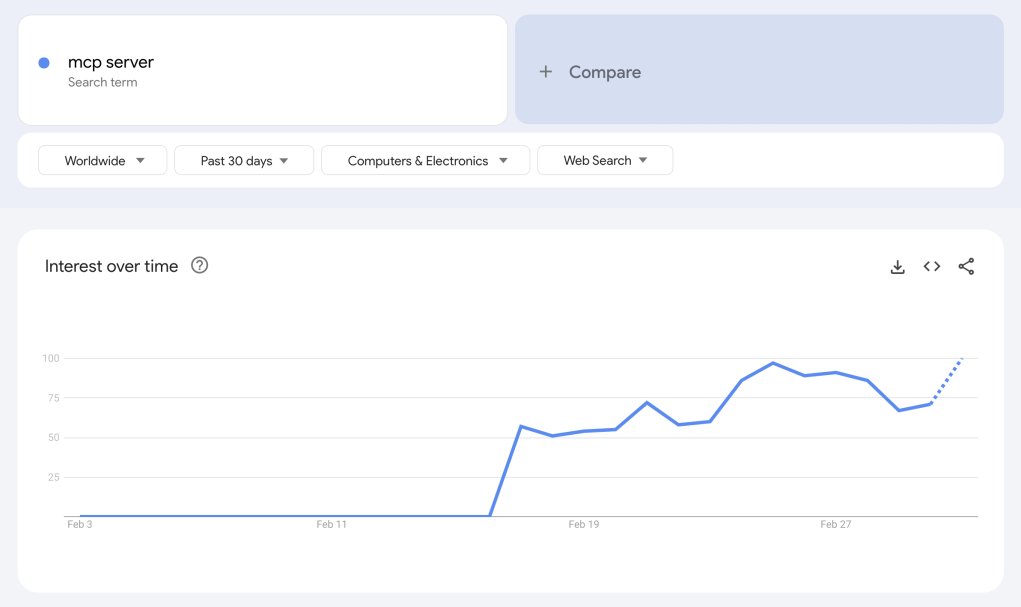
MCP is about to explode. It's the bridge connecting AI agents to real-world data, freeing them from their text boxes.
Learning MCP now will make you highly valuable in 3-6 months.
I've created a protocol that makes building them with Cline super fast. Check it out 👇
English
MrMofer retweetledi


MrMofer retweetledi

Today I was sent the following cool demo:
Two AI agents on a phone call realize they’re both AI and switch to a superior audio signal ggwave
English
MrMofer retweetledi

Excited to introduce flow Q-learning (FQL)!
Flow Q-learning is a *simple* and scalable data-driven RL method that trains an expressive policy with flow matching.
Paper: arxiv.org/abs/2502.02538
Project page: seohong.me/projects/fql/
Thread ↓
English