
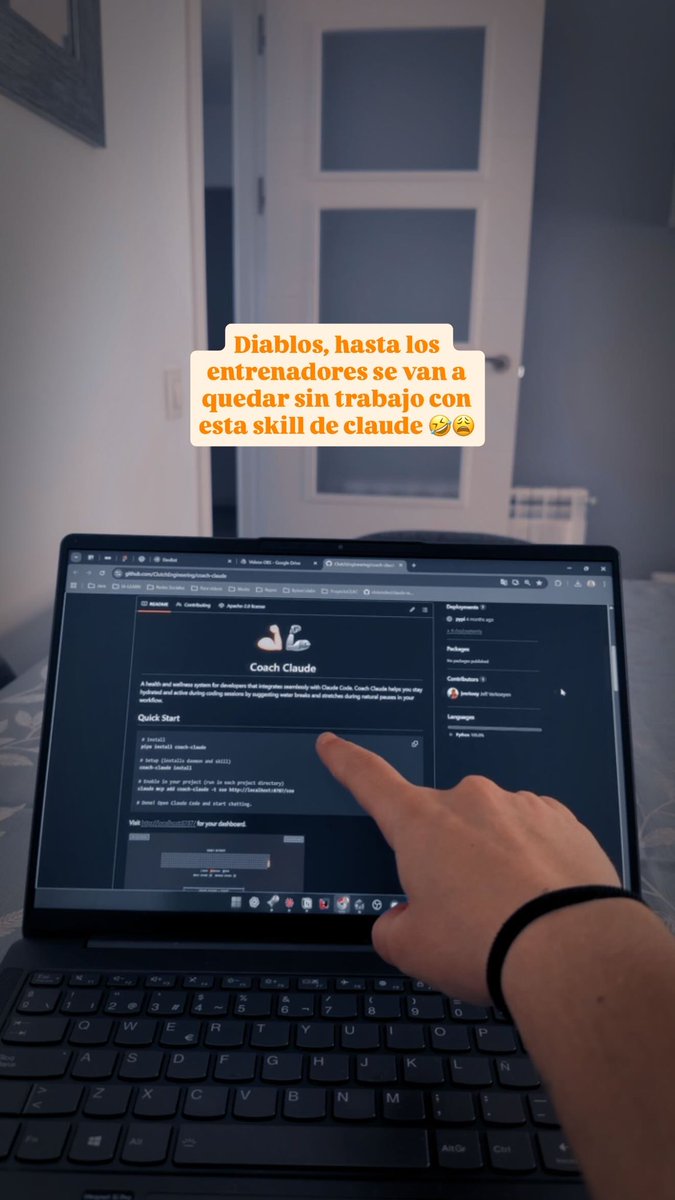
Los entrenadores también se van a quedar sin trabajo con esta skill de claude 😩
Español
chanti.dev
185 posts

@__devch
☕ Java Backend Developer






Introducing Claude Opus 4.7, our most capable Opus model yet. It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back. You can hand off your hardest work with less supervision.





🔴 NECESITO TU ATENCIÓN Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable. Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad). Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte. Aquí va paso a paso el método: 1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto): - ChatGPT Pro + Extended (40min de pensamiento aprox por llamada) - Claude Opus 4.6 MAX Pendientes de probar a fondo: - Perplexity Sonar Pro - Notebook LM 2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante. - Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en: - Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario) - Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho. Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt. 3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez. 👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: dropbox.com/scl/fi/f5luli8… Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas. 4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente. Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo: "Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso". El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas. ¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas. Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc. RESULTADOS Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc. Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto. Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.
🔴 NECESITO TU ATENCIÓN Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable. Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad). Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte. Aquí va paso a paso el método: 1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto): - ChatGPT Pro + Extended (40min de pensamiento aprox por llamada) - Claude Opus 4.6 MAX Pendientes de probar a fondo: - Perplexity Sonar Pro - Notebook LM 2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante. - Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en: - Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario) - Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho. Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt. 3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez. 👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: dropbox.com/scl/fi/f5luli8… Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas. 4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente. Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo: "Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso". El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas. ¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas. Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc. RESULTADOS Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc. Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto. Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.






