Sabitlenmiş Tweet
Krishna
394 posts


Krishna
@__krishna_24
CS Undergrad & Photographer. Python, and a phone lens. Based in India
Katılım Kasım 2022
172 Takip Edilen20 Takipçiler


Thriller readers, I need your help 🙂↕️
Looking for psychological thriller recommendations. What's the best book you've read recently?
Enough of this reading break — it's time to get back into it.
#BookTwitter #BookRecommendations
English

23 Feb 2020 → 2 Jun 2026
6 years of LeetCode in one frame 📈
✅ Show up
✅ Solve
✅ Repeat
Thanks @striver_79 for the inspiration. 🙏
#leetcode #coding

English


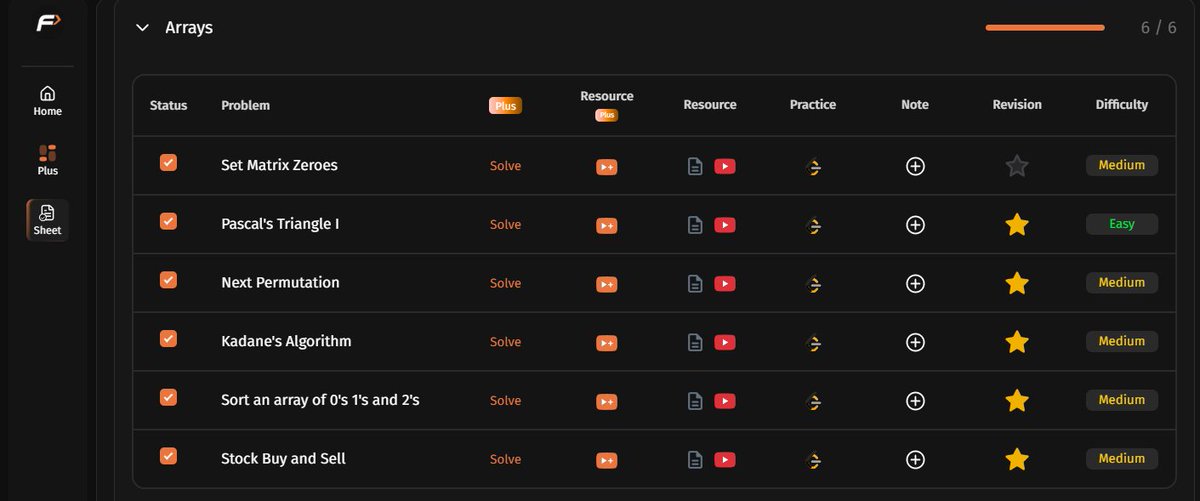
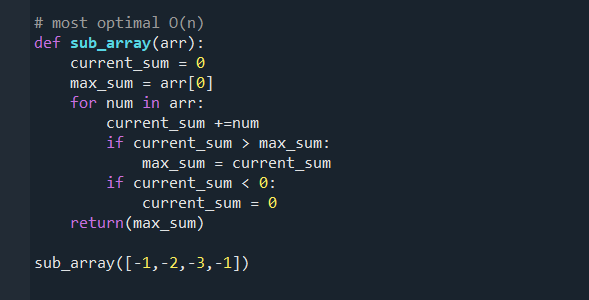
day 2 sorted
Problems solved today :
Maximum Subarray(Kadane's), Dutch Flag(sorting arrays of 0's ,1's and 2's) , and Stock buy and sell
every approach was me going from brute force to better to optimal .
#SDEChallenge @striver_79 @takeUforward_


English
@wordsofteekay @karpathy the stanford videos are great resource , but the book is not for me , i will doze off in middle
English

His playlist is also really good. But the resources I used are not really documentation. One is a course by Stanford, and the other is a book by Sebastian Raschka. The course is a great complement, because it goes beyond LLMs, it talks about resource management, GPUs, tensor optimization, parallel computation. Fun stuff.
English
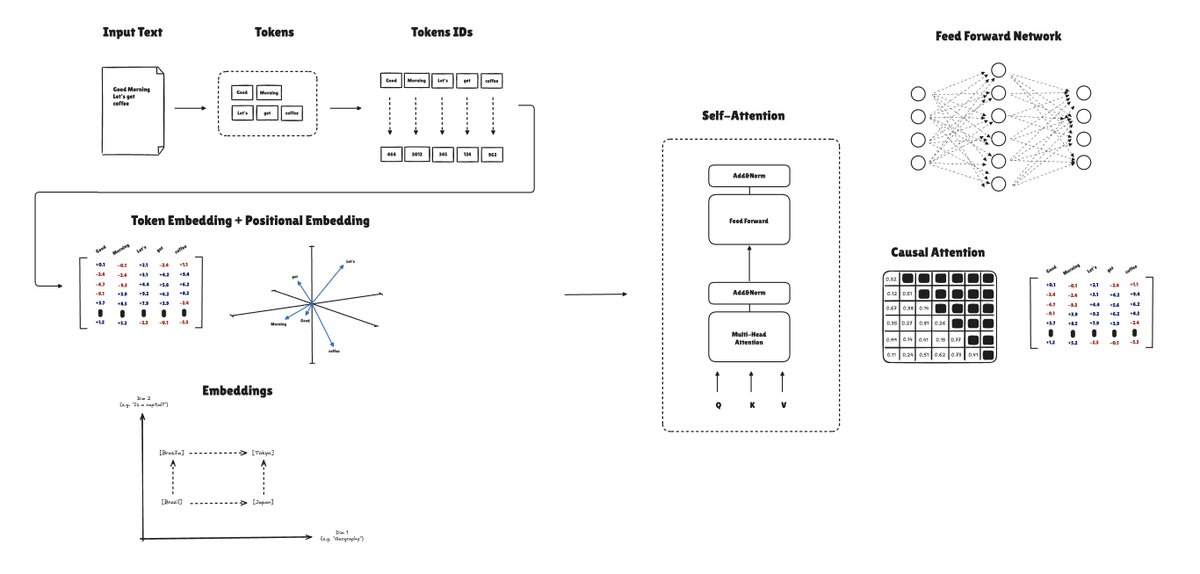
𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗮 𝗚𝗣𝗧 𝗠𝗼𝗱𝗲𝗹
For the past few weeks, I've been reading about Foundation Models [0] and decided to work on the implementation of the GPT architecture [1] to understand its building blocks and how it works under the hood.
Here are the concepts I worked on in this implementation:
Tokenization → Embeddings → Self-Attention → Multi-Head Attention → Transformer Block → GPT Model → Pretraining.
— The tokenization part was focused on building tokens from the input text and transforming them into token IDs; Then using a BPE tokenizer algorithm [2]
— Embeddings: representing tokens with a simple scalar value (ID) is too simplistic. Embeddings come to build richer representations. I built small embeddings for learning purposes and then increased the representation to scale that
— Multi-Head Self-Attention: this was one of the most interesting parts, creating attention scores and building relationships between tokens to produce context vectors
— Transformer blocks have the attention heads, dropout, layer norm, and the feed-forward network
— Pretraining is a standard training process used for deep learning models. But in this case, we update the weights end-to-end, from the embeddings to the attention layer to the feedforward network
The implementation was highly inspired by the Language Modeling from Scratch course [3] and the Build a Large Language Model book [4]. It's still very rudimentary, but very useful if you plan to learn these concepts in depth.
🔗 Article Link: Self-Attention, Foundation Models, and the GPT Architecture from Scratch: iamtk.co/self-attention…
---
In the future, I plan to write about finetuning (using foundation models and finetuning for other tasks) and optimizations (attention blocks optimization, GPU and kernel optimization).
[0] Foundation Models at Nubank: x.com/wordsofteekay/…
[1] LLM implementation repo: github.com/imteekay/llm
[2] Tokenizers lecture: youtube.com/watch?v=SQ3fZ1…
[3] Language Modeling from Scratch: youtube.com/playlist?list=…
[4] Build a Large Language Model: manning.com/books/build-a-…

YouTube
English










when she asks me when are we meeting but petrol prices are 111/L so i just tell her i am gay and stay home
English



@Markmanson I built my feed brick by brick so that this post lands on my fyp.
English

You don’t find your purpose. You build it, brick by brick, mistake by mistake.
English

@AndrewYNg Who do you think would play a more important role, ML engineers or AI engineers. Or it's a team effort ?? @andrewng
English

One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]

English