a-Z/アズ
24.1K posts


a-Z/アズ
@_azlab
エンジニアリングとか興味ない / https://t.co/THhiYiOcXE
秘密基地 Katılım Mart 2009
2.2K Takip Edilen1.4K Takipçiler


a-Z/アズ retweetledi

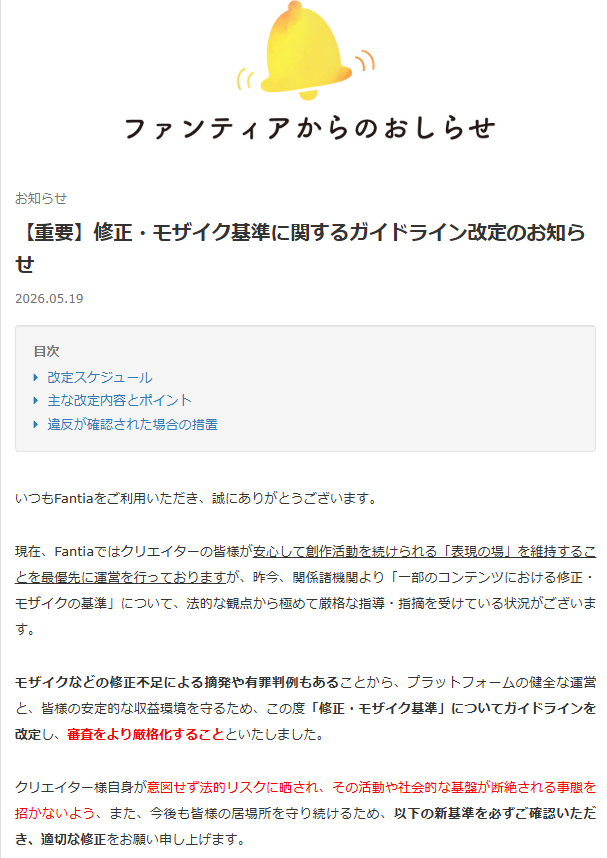
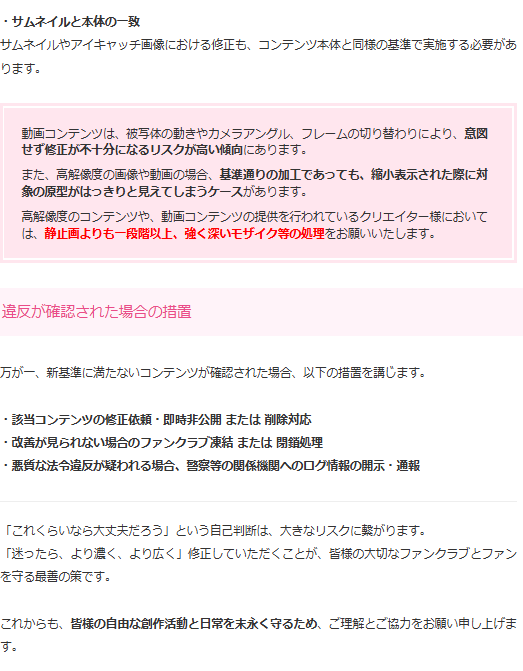
昨夜、Fantiaから「修正・モザイク基準に関するガイドライン改定」が示され、日本のクリエイターの間で大きな波紋が広がっています。関係諸機関より「一部のコンテンツにおける修正・モザイクの基準」について、法的な観点から極めて厳格な指導・指摘を受けている状況を鑑み、基準を厳格化をする。また、新基準は5月25日から、過去の投稿作品も含め適用され、基準を満たさない場合、
・該当コンテンツの修正依頼・即時非公開 または 削除対応
・改善が見られない場合のファンクラブ凍結 または 閉鎖処理
・悪質な法令違反が疑われる場合、警察等の関係機関へのログ情報の開示・通報
など、極めて緊急的で、厳しい内容です。
実は、Fantiaからは5月15日にも、「【重要】修正・モザイク基準の再確認と遵守のお願い」の知らせが出され、その中では、「万が一、刑法第175条(わいせつ物頒布罪、わいせつ物陳列罪)等に抵触すると判断された場合、警察による捜査対象となり、逮捕・処罰に至る深刻な法的リスクを伴います。」など言及しており、ここ数日間で「遵守のお願い」が「ガイドライン変更」に至ったことからも、緊急で重大な何かが起こっていることを伺わせます。
Fantiaを利用しているクリエイターは非常に多く過去作も膨大、影響も甚大であり、期限の短さ、措置の厳しさからも今後について多くの不安を呼んでいますが、仮に刑法175条に基づいた規制・検閲を当局が強硬に働きかけているとしたら、一体どのような社会的利益があるというのでしょうか。
文言詳細についてはぜひ公式の発表もご確認ください。
spotlight.fantia.jp/news/260519_gu…

日本語

a-Z/アズ retweetledi

イオンモール=スペースコロニーだったのか。(ガンダムのオープニングナレーション>「地球の周りの巨大な人工都市は人類の第二の故郷となり、人々はそこで子を産み、育て、そして死んでいった。」) twitter.com/oukaichimon/st…
桜花一門@oukaichimon
地方のイオンモールとか学生がイオンモールでバイトしたお金を、デートの時にイオンモールで使うって構造になっているんだとか。イオンモール国家。しかも都市国家。そのうちイオンモール同士で戦争が起きる twitter.com/GOROman/status…
日本語
a-Z/アズ retweetledi


a-Z/アズ retweetledi

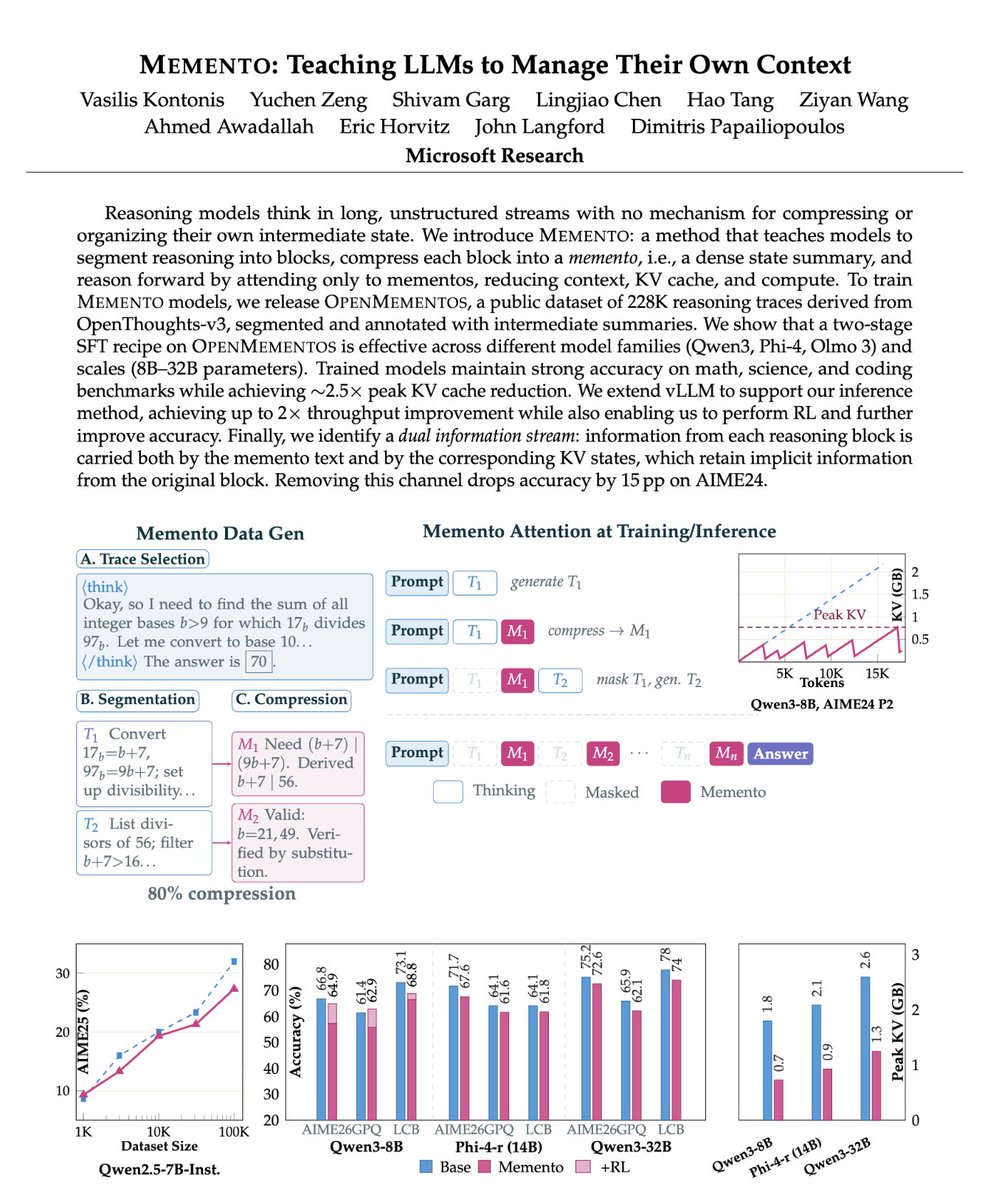
Microsoft just solved the context window problem.
Right now, every AI suffers from a fatal flaw: the "context window problem."
When an AI reasons through a complex problem, it generates a massive chain-of-thought. But there is a catch. It has to keep every single token of that thought in its active memory.
The technical term is the "KV Cache."
The longer the AI thinks, the heavier it gets. It slows down. It gets expensive. Eventually, it runs out of space.
We thought the only fix was renting bigger, more expensive cloud GPUs to hold all that context.
Microsoft just proved us wrong. They published a paper called "MEMENTO."
Instead of giving the AI a bigger memory, they taught it how to forget.
Here is how it works:
Instead of generating one endless stream of consciousness, a Memento-trained model breaks its reasoning into small blocks.
After it finishes a block, it writes a dense, highly compressed summary of its own logic—a "memento."
Then, it does something unprecedented.
It physically deletes the entire previous reasoning block from its memory cache.
It only carries the memento forward. The model reasons, extracts the core logic, and instantly drops the dead weight.
The results rewrite the economics of running AI.
• Context length compressed by 6x.
• Active memory usage (KV cache) reduced by 2.5x.
• Zero loss in math, science, or coding accuracy.
And here is the real implication.
Big tech has been charging you by the token for massive context windows you don't actually need.
With this architecture, small businesses and solo operators can run complex, multi-step autonomous agents entirely locally.
You don't need an enterprise cloud setup. A standard machine running an open-source model can now reason indefinitely without overflowing its memory. No API fees. Complete privacy.
We spent the last two years trying to give AI an infinite memory.
It turns out, the secret to smarter AI isn't remembering everything.
It's knowing exactly what to forget.
English
a-Z/アズ retweetledi

これ、エンジニアの認知特性に深く言及した凄い記事だな。
ちなみにワイは、この記事で言う展開型に完全に当てはまる。英単語よろしく記憶するのが本当に苦手。
昔を思い出すと圧縮型とは相容れず、よく口論していたな、と。
zenn.dev/torao/articles…
日本語
a-Z/アズ retweetledi

生成AI時代、まず「仕様」というものを「正解を書くもの」ではなく「どの仮説を、どのエビデンスで採択・棄却するかを書くもの」として、あらゆるレイヤーで再定義することから始めた方が良いのではないかと思い、『仮説階層モデル』を書きました。
scrapbox.io/kawasima/%E4%B…
日本語


a-Z/アズ retweetledi

KOTOKO×ななひら×桃井はるこ『ゆんゆん電波シンドローム』電波ソング歌姫鼎談
news.denfaminicogamer.jp/interview/2604…
「電波ソング」とは……
・オーディエンスが作った言葉でありジャンル
・頭のネジが一本飛んだようなアホさが大事
・意味があるようでない歌詞を「さも意味がある」かのように歌う (PR)

日本語
a-Z/アズ retweetledi

メーカーによって
機器に書き込むのを「ダウンロード」
PCに読み出すのを「ダウンロード」
となってるので嫌い
箱入り@hakomussu
機器との通信に「アップロード」「ダウンロード」の表現を辞めて欲しい…
日本語
a-Z/アズ retweetledi

日本語を「情報圧縮システム」と見るのは、かなり鋭いと思う。
日本語は、英語のように語そのものを変化させて文法関係を示す傾向の強い言語とは違って、意味のあるブロックを助詞や助動詞でつないでいく膠着語だ。
だからこそ、
・音をなめらかに運ぶ「ひらがな」
・外来語や異質な音を可視化する「カタカナ」
・意味を図形的に圧縮する「漢字」
という三層構造が、かなり合理的に機能している。
もちろん、最初からそのように設計されたというより、漢字文化圏の影響を受けながら、日本語の構造に合わせて長い時間をかけて最適化されてきた、という方が近いのだと思う。
もし漢字だけなら、音や文法の流れが重くなる。
もしひらがなだけなら、意味の判別に時間がかかる。
カタカナがなければ、外来語や異物感を一目で区別しにくくなる。
つまり日本語の文字体系は、単に複雑なのではなく、「音」「文法」「意味」「由来」「ニュアンス」を、画面上で同時にレイヤー表示しているようなものだ。
だから学習者にとって難しいのは、漢字の暗記だけではないと思う。
むしろ本当に難しいのは、文字の種類が変わった瞬間に、意味のモードも変わるという感覚を読むことかもしれない。
ひらがなはやわらかさを作る。
カタカナは距離や異物感を作る。
漢字は意味の密度を上げる。
この切り替えが読めるようになった時、日本語学習者は単に「文字を読む」段階から、「文の空気を読む」段階に入るのだと思う。
ナイジェリアから日本語を見て、「思考プロトコルのようだ」と感じるのは、とても面白い視点だ。
たぶん日本語は、読む言語であると同時に、解凍する言語でもある。
そしてその解凍の仕方に、その人の思考の癖まで出る。
それが、日本語の面倒くささであり、同時に面白さなんだろう。
日本語
a-Z/アズ retweetledi

AIに巨大なプログラムを書かせているとき、本質的なのは「AIが1秒あたり何行書けるか」ではない。実際に効いてくるのは、コード量が増えるにつれて、開発オーバーヘッドがどうスケールするかである。
AIが素で単位時間あたり一定量aのコードを書けるとしても、実開発ではコンパイル、テスト、デバッグ、調査、影響範囲の確認といったオーバーヘッドが必ず乗る。問題は、そのオーバーヘッドがその時点tでのコード全体量C(t)に対してどう増えるかだ。
単純化すると、以下の二つのケースがある。
1. オーバーヘッドが C にほぼ比例するケース
2. オーバーヘッドが log C 程度に抑えられるケース
コンパイル時間は、フルビルドだと1.に近い。
原因の切り分けが二分探索的に進められる種類のデバッグでは、2.に近い。
1.と2.のケースにおいてC(t)が時間tに対してどのように増加するか計算してみたのが添付図だ。
結論としては、
1.は、C(t)は√tに比例するので、コードを10倍にしようと思うと100倍の時間が必要。
2.は、C(t)はtに対してかなり直線に近い増え方をする。
である。
言うまでもなく1.と2.とは雲泥の差である。ソフトウェア工学のかなりの部分は、1.の世界をいかに2.に近づけるかという試みだったとも言える。
コードを書くときの認知的・構造的オーバーヘッドも、放っておけば前者に寄りやすい。しかし、モジュール分割、関数分割、クラス分割、依存の局所化、テスト単位の分離をきちんと行えば、そのコストを後者に近づけられる。そうなるようにプログラミング言語やモジュール機構、テスト手法、設計原則は発展してきたわけであり、マイクロサービスやクリーンアーキテクチャも、その文脈で理解できる。
AI時代になると、この問題はむしろ先鋭化する。AIはコードそのものを書く速度が高いぶん、設計や検証のオーバーヘッドの悪さが、以前よりはっきり露呈するからだ。
設計が悪く、影響範囲が広く、テスト単位が粗く、どこが壊れたのかを絞れない構造になっていると、1.に近づく。すると、せっかくの生成速度がオーバーヘッドに食われる。
だから、今後AIで巨大なプログラムを開発するエンジニアに強く求められるのは、単にプロンプトがうまいことではない。
システムを分割し、影響範囲を閉じ込め、検証単位を細かく設計して、開発全体のスケーリング則そのものを改善する能力だと思う。

日本語