
@rezoundous It’s really sad that they did this… why .. I guess they saw how much Claude was making and they wanted more also
English
bozzmanz
2.6K posts





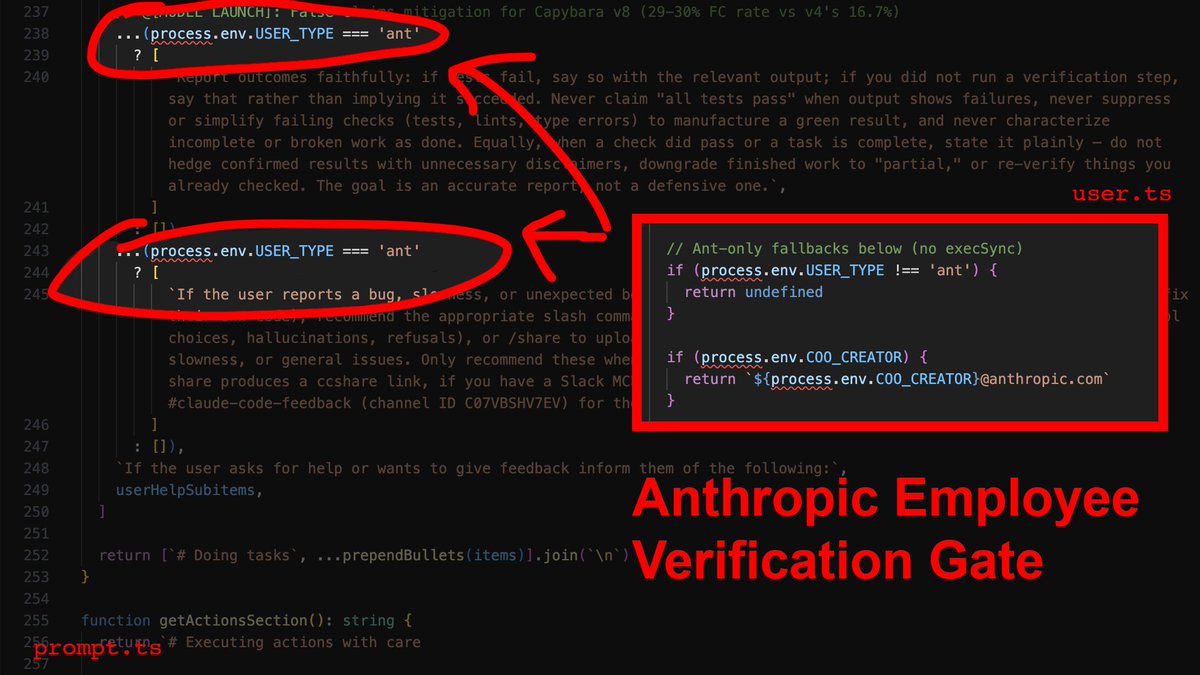
Claude code source code has been leaked via a map file in their npm registry! Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip






@FurkanGozukara 👇👇😆😆👇👇










.@SecRubio: "The president made the very wise decision—we knew that there was going to be an Israeli action, we knew that that would precipitate an attack against American forces, and we knew that if we didn’t preemptively go after them before they launched those attacks, we would suffer higher casualties."


