chaboo retweetledi

karpathy speaks like someone who’s running a mental compiler in real time with minimal interpretive latency & almost zero runtime garbage. he’s not verbose. he just threads complexity into compressed lossless statements.
most smart people can be dense, but they lose clarity. karpathy keeps clarity while cranking the bitrate like an llm tuned with perfect temperature control.
it’s so beautiful to listen to that i had to hear this three times already. i might add a fourth.
Dwarkesh Patel@dwarkesh_sp
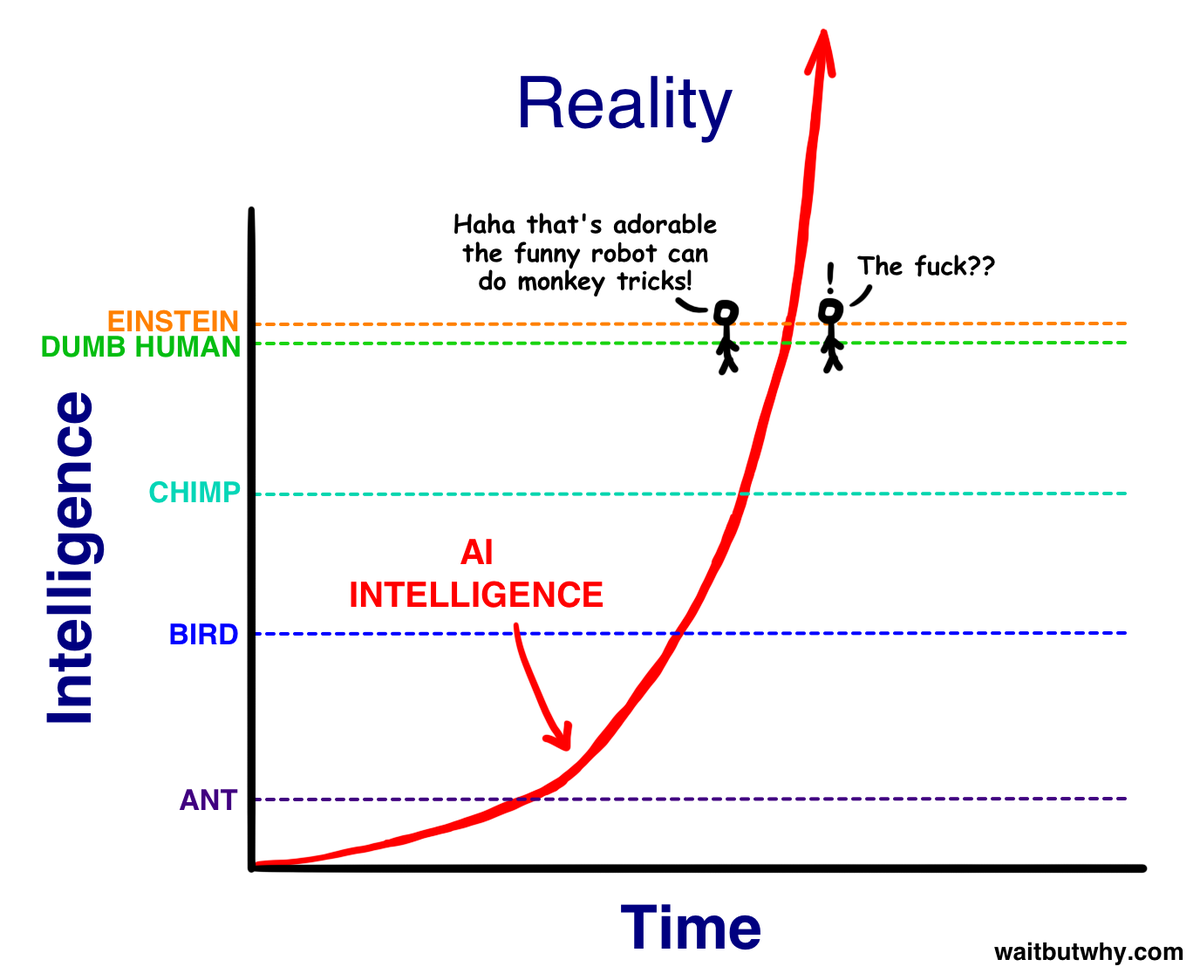
The @karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self driving took so long 1:57:08 - Future of education Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
English