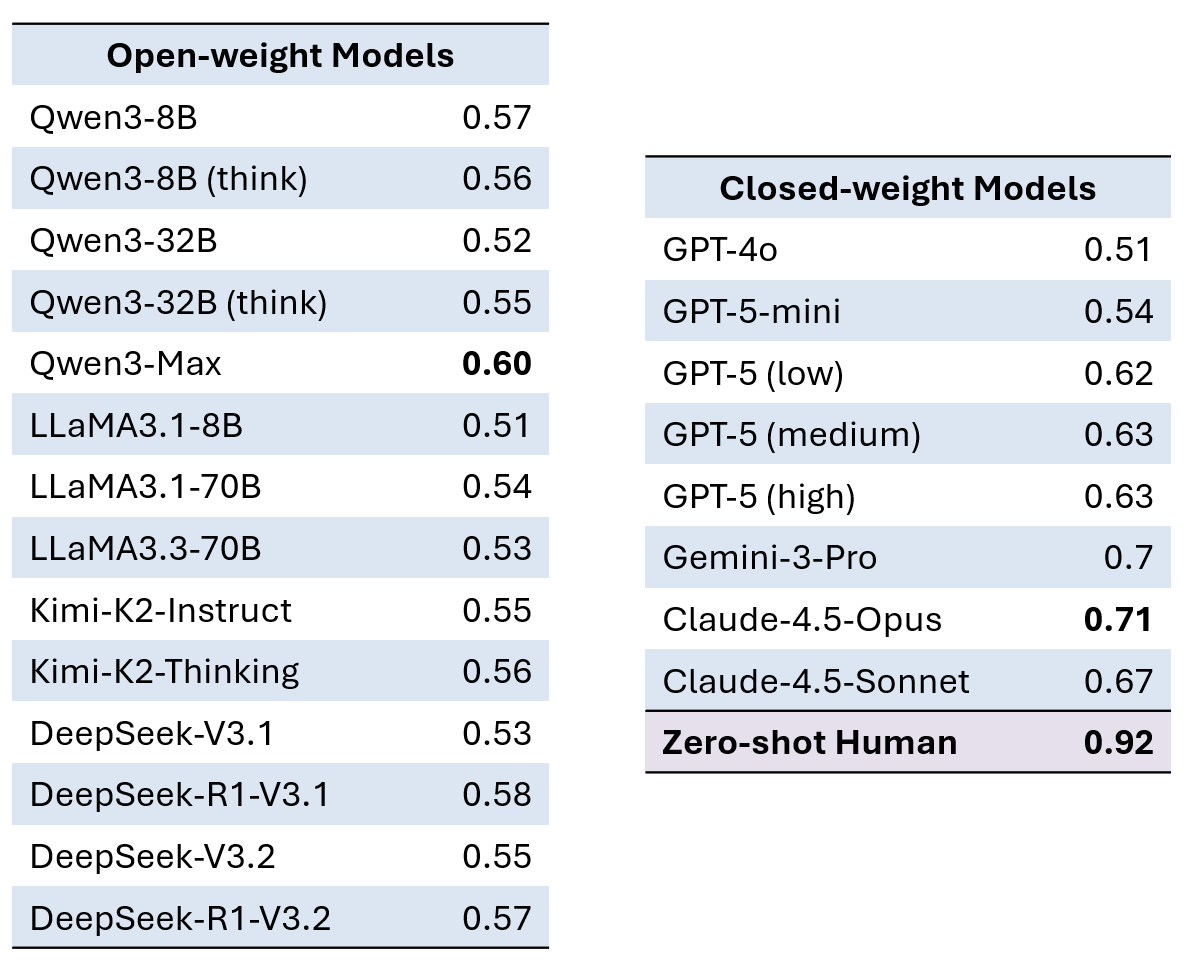
Cole Salvador@ColeSalvador31
In 2022 and 2023, tiny teams of researchers drew straight lines on graphs that predicted the US was headed for an energy bottleneck in AI. But the government had no idea.
The future of AI is too important to make the same mistake again. We need talent-dense, AI-focused offices that can skate to where the puck is going and implement President Trump’s AI agenda.
In a new piece for AFPI (@A1Policy), we discuss 2 promising offices that could act as hubs of government AI foresight: the Center for AI Standards and Innovation (CAISI) in the Department of Commerce and the Bureau of Emerging Threats (ET) in the Department of State.
We found that they have the density of talent to succeed but still lack resources: funding, headcount, and authorization. Here’s a summary:
1) The Center for AI Standards and Innovation (CAISI) lacks resources
> It has talented technical staff and a strong track record in evaluations, industry relationships, and insight into China
> But it’s chronically underfunded. It’s been around for 3 years but only received $30M in total, not annual, funds. That’s 11 times less than the UK’s equivalent. (It’s even short of Canada and Singapore)
> It’s only has 20-30 employees who are swamped with workstreams and external requests from agencies like the IC
To solve this, Congress should fund CAISI with an annual budget of $50-100 million.
2) CAISI lacks authorization or a focused mission
> Between Department asks, inbound from other offices, and the AI Action Plan, it has more missions than staff
> Its critical mission could be threatened by future administrations, who would externally pressure it to pursue DEI initiatives
Congress needs to enshrine the office and give it a clear mission. We present an America First vision for CAISI, in which it acts as a technical strike team, bridge between industry and government, frontier analysis unit, and technical standards organization.
3) The Bureau of Emerging Threats (ET) lacks authorization
> ET is similarly talent-dense, with experts in cyber, AI, and international relations
> But it lacks congressional authorization and could be destroyed or co-opted by future administrations
The Bureau needs concrete support from Congress and levers of interagency influence, like regular reports to national security leaders.
With appropriate action, Congress can help ensure the President has the resources he needs to help America win the AI race and usher in a new golden age of human flourishing.
Always fun to collaborate with @CrovitzJack and @YusufSMahmood, who have posted about other sections of our piece.