Sabitlenmiş Tweet

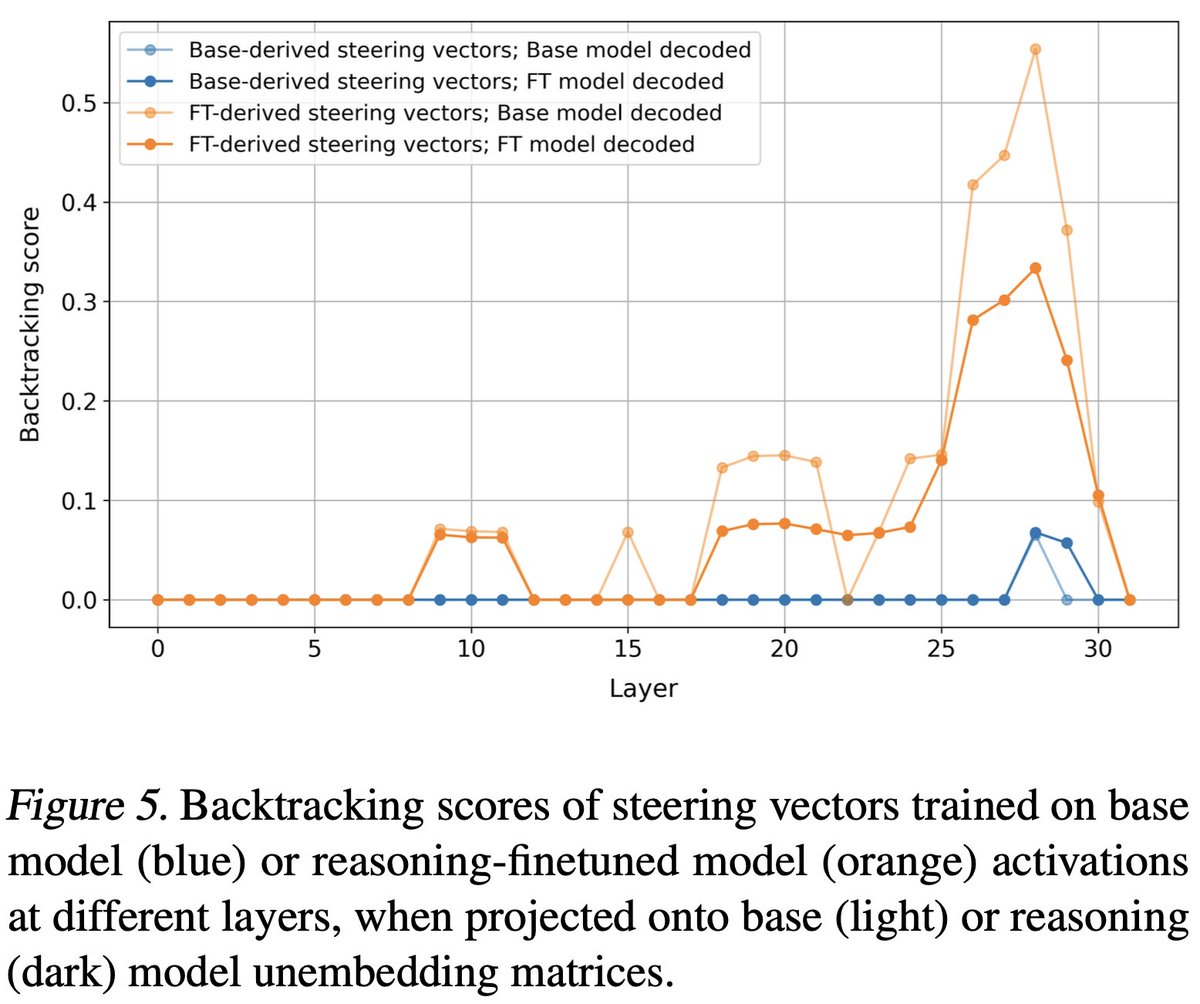
Do reasoning models like DeepSeek R1 learn their behavior from scratch? No! In our new paper, we extract steering vectors from a base model that induce backtracking in a distilled reasoning model, but surprisingly have no apparent effect on the base model itself! 🧵 (1/5)
English