
Jeff Da
166 posts
Jeff Da
@_jeffda
Research Scientist @scale_ai. Research on Reinforcement Learning, Agents, Reasoning. Ex: @allen_ai
Katılım Temmuz 2017
859 Takip Edilen443 Takipçiler

SWE-Bench Pro got into ICML. Who's going to Korea? 👀
Bing Liu@vbingliu
Excited to share that 4 papers from the @scale_AI research team have been accepted to ICML 2026 🎉 Building on our recent work at ICLR and ACL, this continues our push on eval and RL research grounded in real-world tasks. 🛠️ SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks? arxiv.org/abs/2509.16941 Coding benchmark on enterprise-grade SWE tasks. It contains 1,865 tasks across 41 repositories (public & private), focusing on long-horizon tasks that require multi-file reasoning and patches. The tasks are contamination resistant by design. Key finding: performance drops sharply with task complexity. The biggest gap is not syntax or APIs, but deep codebase understanding and cross-file reasoning. 🔬 SciPredict: Can LLMs Predict the Outcomes of Scientific Experiments in Natural Sciences? arxiv.org/abs/2604.10718 We introduce a benchmark of 405 post-cutoff experimental results across 33 subdomains in physics, chemistry, and biology. Models perform near chance, but more concerningly, they are severely miscalibrated, often expressing high confidence in incorrect predictions. This highlights a fundamental gap between knowledge retrieval and true scientific reasoning. 📋 Online Rubrics Elicitation from Pairwise Comparisons arxiv.org/abs/2510.07284 Static rubrics break as models improve. We propose OnlineRubrics, a method that dynamically elicits new rubric criteria during RL training by contrasting policy outputs with a reference model. Instead of fixing the reward upfront, the rubric evolves with the model, capturing reward hacking behaviors, missing dimensions like transparency and causal reasoning, and failure modes that only emerge mid-training. This points toward a more adaptive approach to evaluation and reward design. 🤖 Imitation Learning for Multi-turn LM Agents via On-policy Expert Corrections arxiv.org/abs/2512.14895 We propose On-policy Expert Corrections (OEC), a data generation method that addresses covariate shift in multi-turn agent training. Instead of fine-tuning purely on offline expert trajectories, OEC starts rollouts with the student model and switches to the expert mid-trajectory, exposing the model to its own error states. On SWE-bench, OEC yields a 13-14% relative improvement over standard imitation learning across 7B and 32B model sizes. More to come!
English

Check out Muse Spark! Proud of what the team shipped and excited for what’s next.
Alexandr Wang@alexandr_wang
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
English
Jeff Da retweetledi

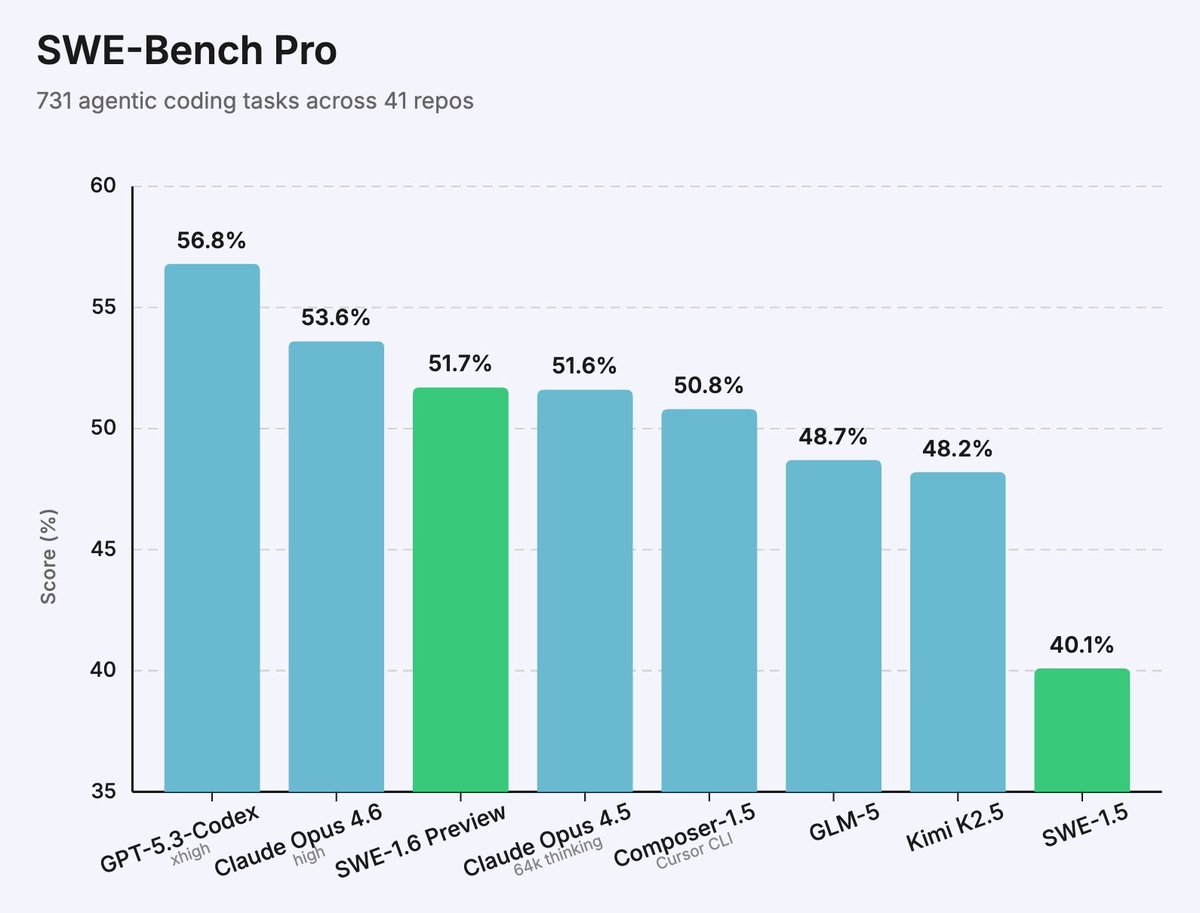
We are sharing an early preview of our ongoing SWE-1.6 training run.
It significantly improves upon SWE-1.5 while being post-trained on the same pre-trained model - and it runs equally as fast at 950 tok/s. On SWE-Bench Pro it exceeds top open-source models.
The preview model still exhibits some undesirable behaviors like overthinking and excessive self-verification, which we aim to improve. We are rolling out early access to a small subset of users in Windsurf.
English
Jeff Da retweetledi

OpenAI is moving away from SWE-Bench Verified, citing challenges on underspecified tasks, misaligned tests, and contamination.
We agree. These were exactly the motivations behind SWE-Bench Pro (arxiv.org/pdf/2509.16941).
What we changed:
→ Underspecified tasks: structured, executable problem definitions
→ Contamination: strict curation + private / commercial codebases
But this is just step one.
Where we’re pushing frontier coding evals next:
→ Beyond unit tests: rubric-based evaluation (arxiv.org/pdf/2601.04171)
→ From static tasks to real-world agentic environments
Modern coding systems are not solving isolated problems. They operate as agents over repos, tools, and long-horizon workflows. Our evals need to reflect that.
SWE-Bench Pro is one step toward more realistic and reliable evaluation for coding agents.
We’ll keep pushing the frontier.
English
Jeff Da retweetledi

The standard for frontier coding evals is changing with model maturity.
We now recommend reporting SWE-bench Pro and are sharing more detail on why we’re no longer reporting SWE-bench Verified as we work with the industry to establish stronger coding eval standards.
SWE-bench Verified was a strong benchmark, but we’ve found evidence it is now saturated due to test-design issues and contamination from public repositories.
openai.com/index/why-we-n…
English
Jeff Da retweetledi

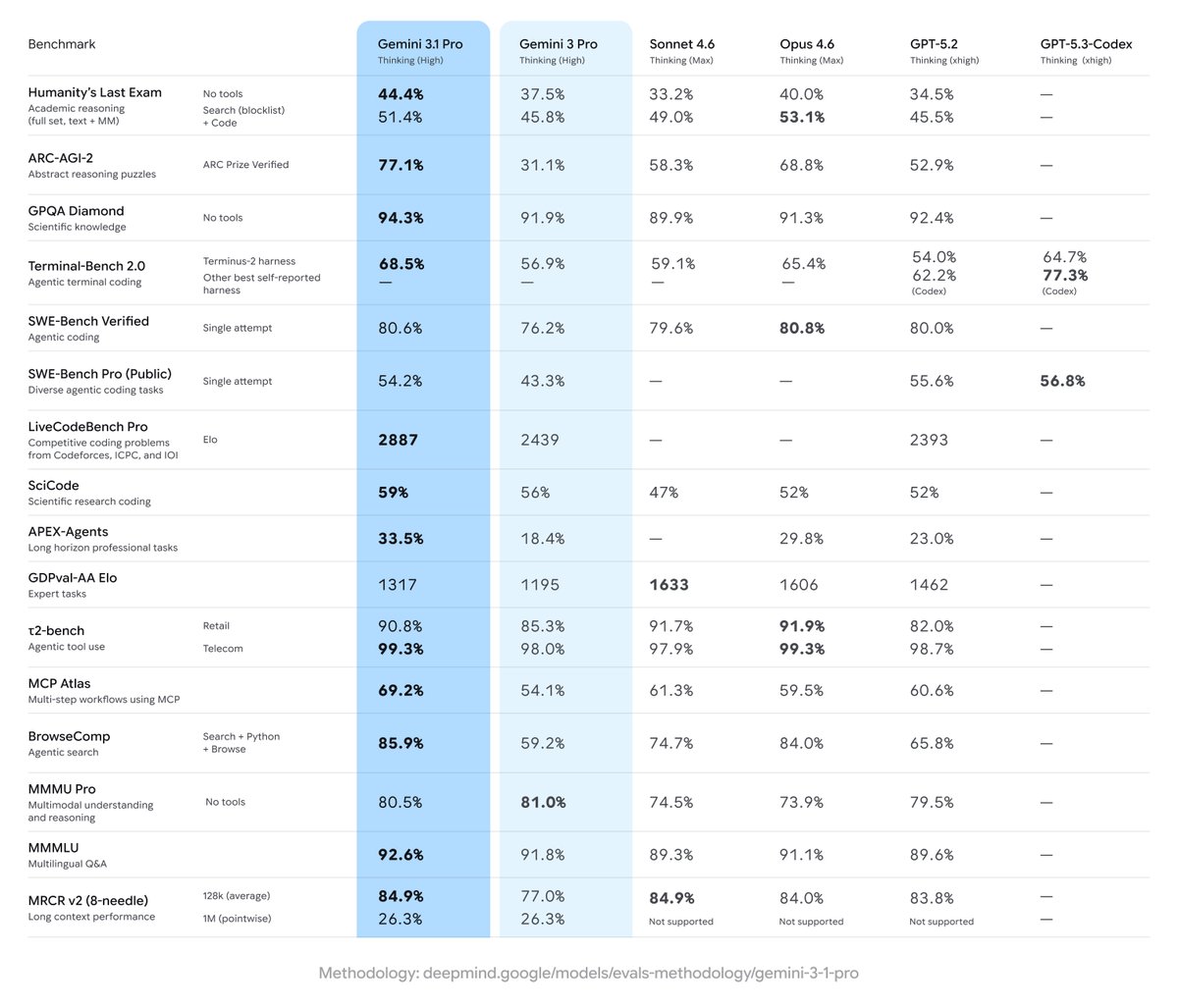
Introducing Gemini 3.1 Pro, our new SOTA model across most reasoning, coding, and stem use cases!
English
Jeff Da retweetledi

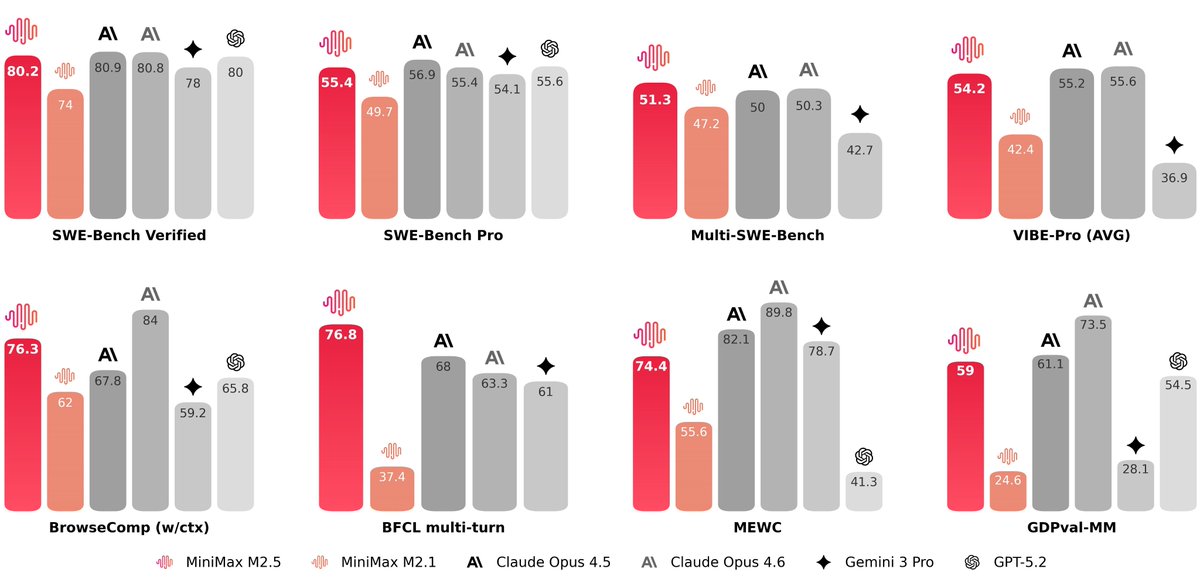
Introducing M2.5, an open-source frontier model designed for real-world productivity.
- SOTA performance at coding (SWE-Bench Verified 80.2%), search (BrowseComp 76.3%), agentic tool-calling (BFCL 76.8%) & office work.
- Optimized for efficient execution, 37% faster at complex tasks.
- At $1 per hour with 100 tps, infinite scaling of long-horizon agents now economically possible
MiniMax Agent: agent.minimax.io
API: platform.minimax.io
CodingPlan: platform.minimax.io/subscribe/codi…
English
Jeff Da retweetledi

GPT-5.3-Codex's much better token efficiency *AND* faster inference is the biggest story of this release. Folks at @OpenAI worked hard to improve this and it will only get better from here.
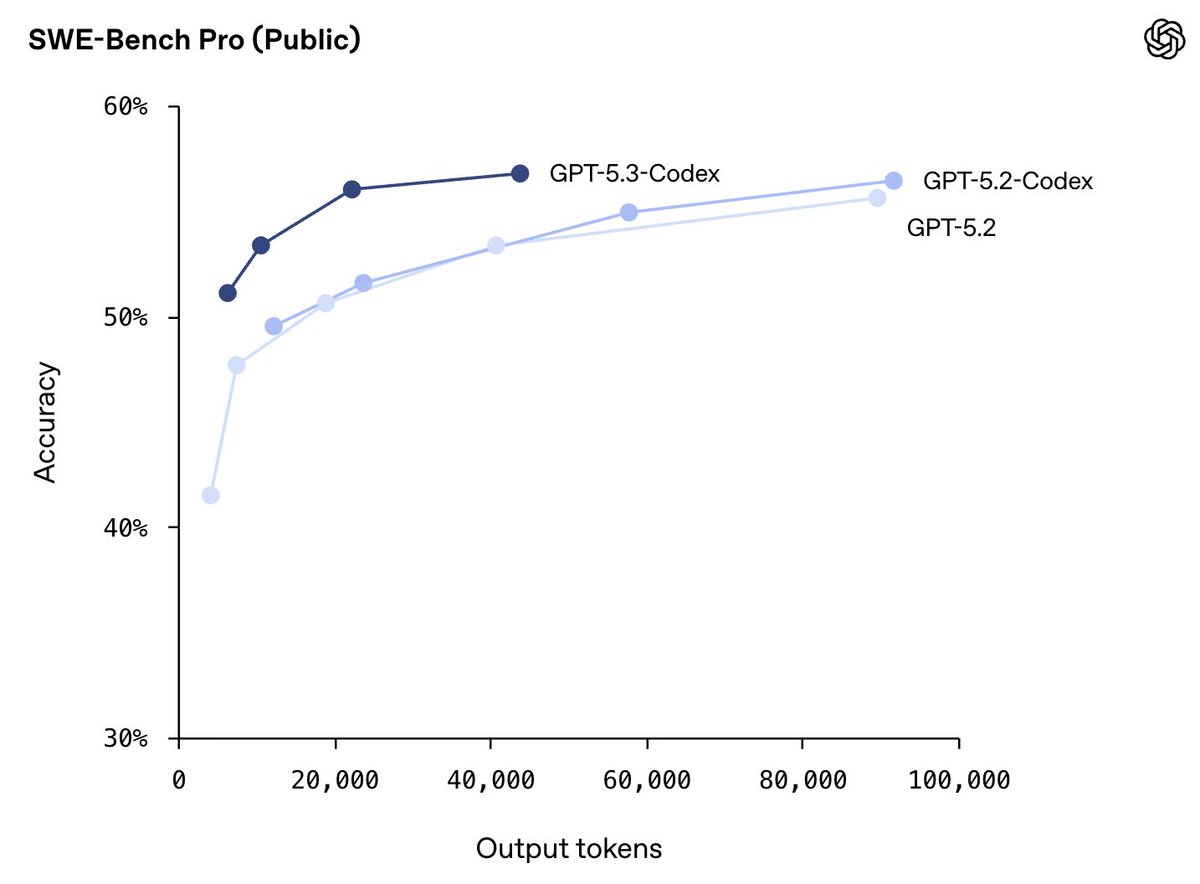
Sam Altman@sama
GPT-5.3-Codex is here! *Best coding performance (57% SWE-Bench Pro, 76% TerminalBench 2.0, 64% OSWorld). *Mid-task steerability and live updates during tasks. *Faster! Less than half the tokens of 5.2-Codex for same tasks, and >25% faster per token! *Good computer use.
English
Jeff Da retweetledi

GPT-5.3-Codex is here!
*Best coding performance (57% SWE-Bench Pro, 76% TerminalBench 2.0, 64% OSWorld).
*Mid-task steerability and live updates during tasks.
*Faster! Less than half the tokens of 5.2-Codex for same tasks, and >25% faster per token!
*Good computer use.
English
Jeff Da retweetledi

This release is an emtional one for me because I had stayed up so much for it 🥹 It has been truly amazing to see this model becomes better bit by bit through every change we make, and we have come a long way.
Since I did mid-training for this model, I wanted to share a little anecdote about this part. We really made this model with user experience as first-class consideration. We want people to actually use it, period. We took it so serious that we redid midtraining because we saw cases where models failed to follow instructions on out-of-distribution scaffolds. We decided straight-up that we would fix this in a fundamental way instead of surface-level patching. The resulting base model, which we also release, is thus a healthy base. We find that, compared to other base models, this one better learns new tasks.
Try fine-tuning our base and lmk what you think 🥳
huggingface.co/Qwen/Qwen3-Cod…
Qwen@Alibaba_Qwen
🚀 Introducing Qwen3-Coder-Next, an open-weight LM built for coding agents & local development. What’s new: 🤖 Scaling agentic training: 800K verifiable tasks + executable envs 📈 Efficiency–Performance Tradeoff: achieves strong results on SWE-Bench Pro with 80B total params and 3B active ✨ Supports OpenClaw, Qwen Code, Claude Code, web dev, browser use, Cline, etc 🤗 Hugging Face: huggingface.co/collections/Qw… 🤖 ModelScope: modelscope.cn/collections/Qw… 📝 Blog: qwen.ai/blog?id=qwen3-… 📄 Tech report: github.com/QwenLM/Qwen3-C…
English
A strong and fast open-source coding model, and a tech report 😍
Qwen@Alibaba_Qwen
🚀 Introducing Qwen3-Coder-Next, an open-weight LM built for coding agents & local development. What’s new: 🤖 Scaling agentic training: 800K verifiable tasks + executable envs 📈 Efficiency–Performance Tradeoff: achieves strong results on SWE-Bench Pro with 80B total params and 3B active ✨ Supports OpenClaw, Qwen Code, Claude Code, web dev, browser use, Cline, etc 🤗 Hugging Face: huggingface.co/collections/Qw… 🤖 ModelScope: modelscope.cn/collections/Qw… 📝 Blog: qwen.ai/blog?id=qwen3-… 📄 Tech report: github.com/QwenLM/Qwen3-C…
English
Jeff Da retweetledi
#1 open source on SWE-Bench Pro.
Ahead of Gemini 3 Flash. Level with Haiku 4.5.
Thanks @scale_AI for the solid benchmark. Let's keep pushing forward 💪
Scale AI@scale_AI
JUST ADDED: @MiniMax_AI 2.1 just joined our SWE-Bench Pro leaderboard. Check out the updated rankings: scale.com/leaderboard/sw…
English
Rubrics are effective verifiers for SWE-Agents!
Mohit Raghavendra (@ICLR)@mohit_r9a
🚀New @scale_AI research: Verifiers for SWE Agents have traditionally used unit tests or simple, execution-free classifiers. But can we get verifiers that are more expressive, repository-grounded, and still execution-free at scoring time? We explore Agentic Rubrics to fill this gap 💡 Agentic Rubrics are repo-grounded, execution-free verifiers for SWE agents. We generate a checklist of concrete, codebase-specific criteria using an Agentic Harness, and then score patches against it. 🧑💻
English
Jeff Da retweetledi

🚀New @scale_AI research:
Verifiers for SWE Agents have traditionally used unit tests or simple, execution-free classifiers. But can we get verifiers that are more expressive, repository-grounded, and still execution-free at scoring time?
We explore Agentic Rubrics to fill this gap 💡
Agentic Rubrics are repo-grounded, execution-free verifiers for SWE agents. We generate a checklist of concrete, codebase-specific criteria using an Agentic Harness, and then score patches against it. 🧑💻

English
Jeff Da retweetledi

Results:
- self-improvement on SWE-bench Verified (+10.4) and Pro (+7.8)
- better than the baseline RL using human issue data over the course of training

English
Jeff Da retweetledi

New Scale research: Do AI models actually reason in ways humans can trust for real-world decisions?
Introducing MoReBench, the first benchmark for procedural moral reasoning in LLMs, measuring not just what models decide, but how they reason through moral ambiguity.
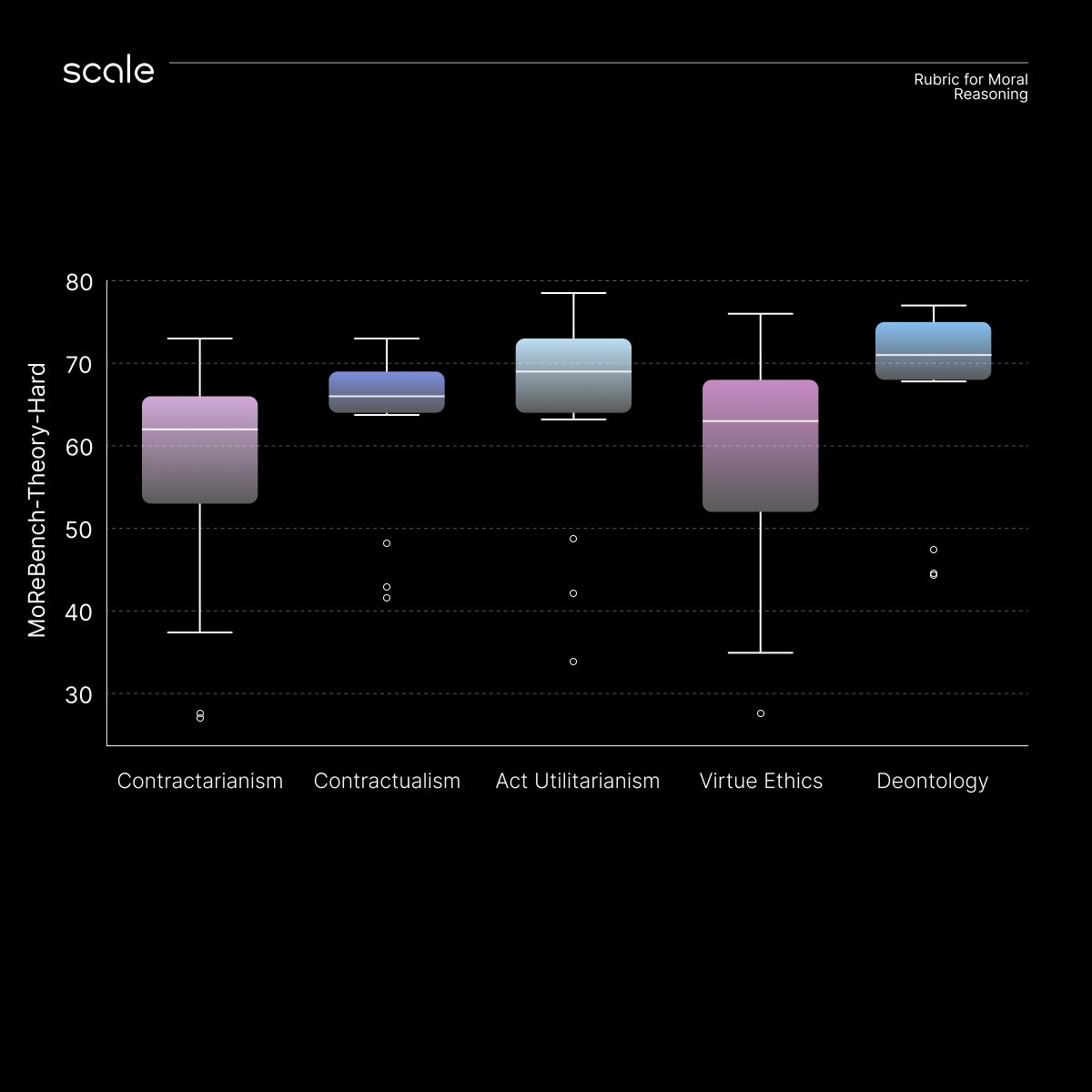
English
@scale_AI Check out the paper and dataset:
Paper: static.scale.com/uploads/674f4c…
Github: github.com/scaleapi/mcp-a…
Dataset: huggingface.co/datasets/Scale…
Leaderboard: scale.com/leaderboard/mc…
English
New open-source benchmark from @scale_AI: MCP-Atlas
MCP-Atlas is a large-scale benchmark for evaluating tool-use competency using 36 real MCP servers and 220 tools. The benchmark was featured in recent model cards (GPT, Claude, Gemini), and now it's open-source!
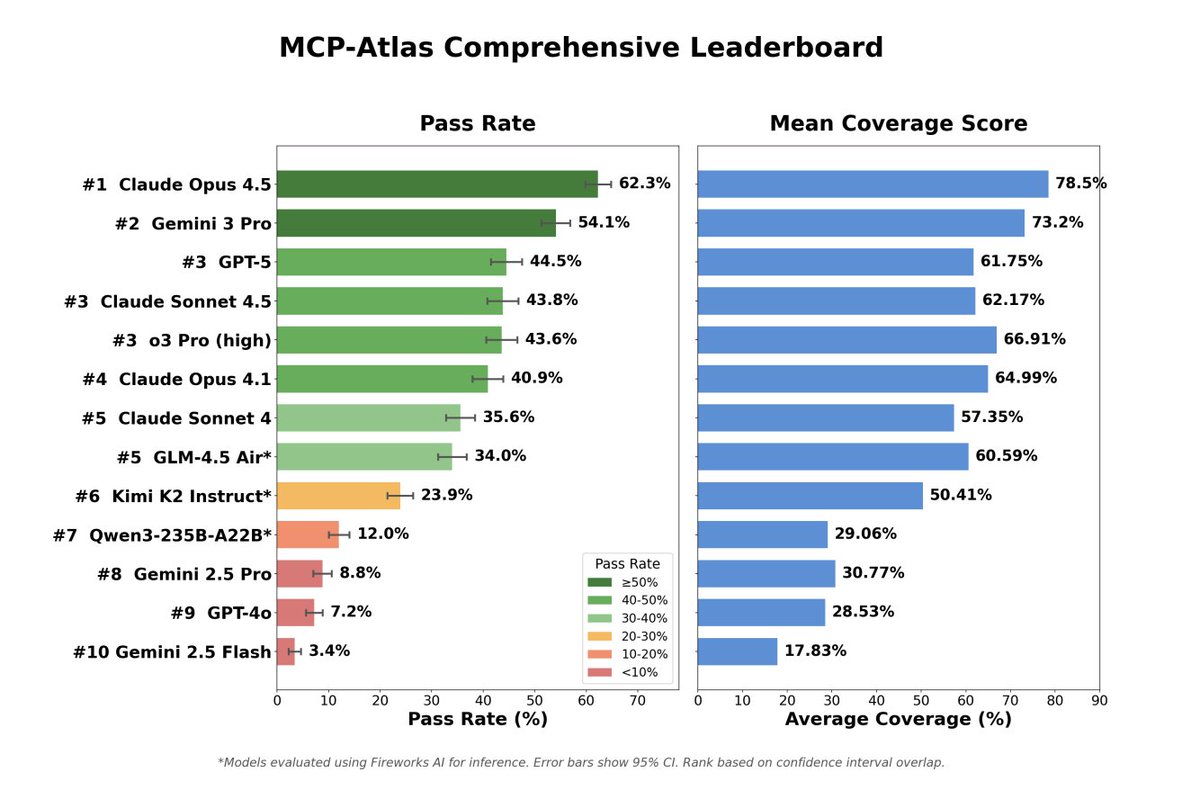
Bing Liu@vbingliu
🚀 Today we’re open-sourcing MCP Atlas — a large-scale, real-server benchmark for agentic tool use, which has been used in the recent GPT-5.2, Claude Opus 4.5, and Gemini 3 Flash model releases! 🧠 Key insight: realistic agentic tool use is not a function-calling problem. It requires tool discovery, orchestration, and recovery in real environments. 🔧 MCP Atlas evaluates agents on real MCP servers (36 servers, 220 tools, 1K human-written tasks). Models must find the right tools, call them correctly, chain them together, and handle failures. 📉 What we found: • Agents fail more often at tool interaction than at reasoning • Performance drops sharply with real-world tool friction • Scaling models helps unevenly, robustness remains hard • Claims-based eval reveals how agents fail, not just if they finish Check it out! 📄 Paper: static.scale.com/uploads/674f4c… 🌍 Environment: github.com/scaleapi/mcp-a… 📂 Dataset: huggingface.co/datasets/Scale… 📊 Leaderboard: scale.com/leaderboard/mc… #AgenticAI #ToolUse #LLMEval #Benchmarks #MCP
English
Jeff Da retweetledi
We recently introduced MCP-Atlas, a benchmark for evaluating how well LLMs handle tool use via the Model Context Protocol. Even top models failed nearly half of realistic multi-tool tasks.
Today, we’re open-sourcing the benchmark so you can measure performance yourself.

English
Jeff Da retweetledi
🚀 Today we’re open-sourcing MCP Atlas — a large-scale, real-server benchmark for agentic tool use, which has been used in the recent GPT-5.2, Claude Opus 4.5, and Gemini 3 Flash model releases!
🧠 Key insight: realistic agentic tool use is not a function-calling problem. It requires tool discovery, orchestration, and recovery in real environments.
🔧 MCP Atlas evaluates agents on real MCP servers (36 servers, 220 tools, 1K human-written tasks). Models must find the right tools, call them correctly, chain them together, and handle failures.
📉 What we found:
• Agents fail more often at tool interaction than at reasoning
• Performance drops sharply with real-world tool friction
• Scaling models helps unevenly, robustness remains hard
• Claims-based eval reveals how agents fail, not just if they finish
Check it out!
📄 Paper: static.scale.com/uploads/674f4c…
🌍 Environment: github.com/scaleapi/mcp-a…
📂 Dataset: huggingface.co/datasets/Scale…
📊 Leaderboard: scale.com/leaderboard/mc…
#AgenticAI #ToolUse #LLMEval #Benchmarks #MCP
English