
L
669 posts


Anthropic had 16 AI agents build a C compiler from scratch. 100k lines, compiles the Linux kernel, $20k, 2 weeks.
To put that in perspective GCC took thousands of engineers over 37 years to build. (Granted from 1987 - however) One researcher and 16 AI agents just built a compiler that passes 99% of GCC's own torture test suite, compiles FFmpeg, Redis, PostgreSQL, QEMU and runs Doom.
They say they "(mostly) walked away." But that "mostly" is doing heavy lifting.
No human wrote code but the researcher constantly redesigned tests, built CI pipelines when agents broke each other's work, and created workarounds when all 16 agents got stuck on the same bug.
The human role didn't disappear. It shifted from writing code to engineering the environment that lets AI write code.
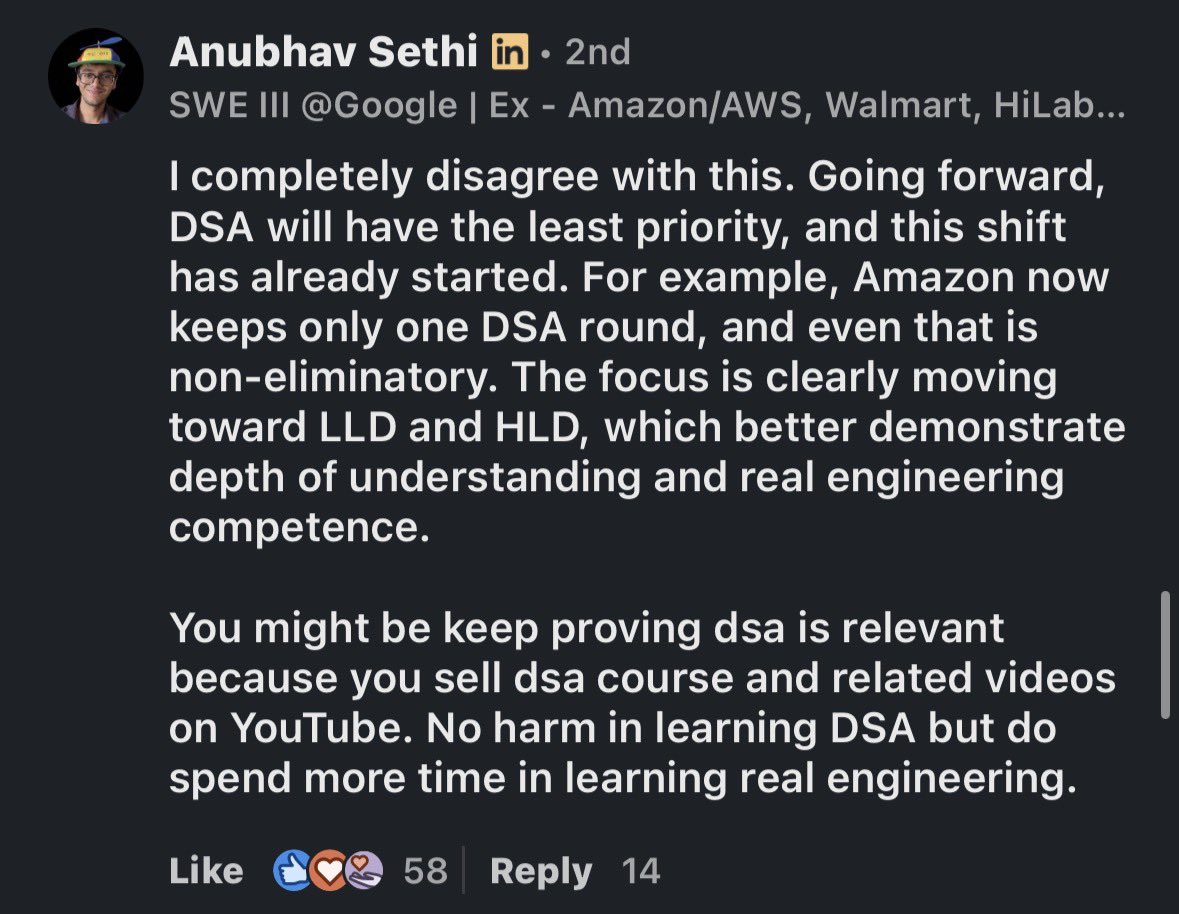
I don’t know how you could make the point AI is hitting a wall.
English
@FordFocusMk67 @mkljczk co ty mówisz, oba używają llmow, co wiecej LLMy i transformery wzięły się z tego że Google chciał mieć lepszy translate xD
Polski


Trzeba być naprawdę zaślepionym amerykanofilią żeby używać Google Translate zamiast DeepL xDD
Aleksandra Fedorska@a_fedorska
Antyamerykański szał ogarnia Niemcy! Media i pseudoautorytety wmawiają Niemcom, jak ci mają wszystkie cyfrowe zastosowania zastąpić niemieckimi (europejskimi) aplikacjami, a oni serio to robia !!!! Niemcy idą prosto do cyfrowej jaskini i poza świat AI, rozumienie to? @Szysz4Szyszek, @miloszlodowski, @SlubowskiG, @rutkem, @cezarykrysztopa
Poznan, Poland 🇵🇱 Polski

Trochę szokujące jest zobaczenie "512GB" na pudełku od Maca - i nie - to nie jest przestrzeń dyskowa, a pamięć RAM.
Zdjęcie od znajomego ☺️

Polski

Myth: Only big companies have the resources to do AI.
Reality: You can now train an LLM in 3 hours on a single GPU node.
Andrej Karpathy@karpathy
nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node). GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100. Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc. As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try. A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here: github.com/karpathy/nanoc… Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning. The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up. Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!
English

The age of the tech company with 1,000 engineers is over.
English

does anyone else still remember back when computer vision was “AI”?
Ilir Aliu@IlirAliu_
AI in robotics gets all the attention right now, but sometimes the most interesting work is very practical. Viet built a small vision system that counts potatoes on a conveyor belt. No giant dataset. No huge model. Just a clear problem and a smart setup. He used Ultralytics’ ObjectCounter, trained a tiny YOLO11 nano model, and because there was no potato dataset, he annotated a single frame with SAM 2 and trained from that. One frame. Still works across the whole video. It is a good reminder that useful AI in industry often looks like this. Focused. Lightweight. Solves a real task. If you work in manufacturing or robotics, these small systems are usually the fastest wins. They save time, reduce errors, and do not need massive infrastructure. Nice work, Viet. His projects: github.com/vietnh1009 —- Weekly robotics and AI insights. Subscribe free: scalingdeep.tech
English


Tłumaczę i objaśniam. Robisz stronę typu "haha przetłumacz bełkot dewelopera na polski i odwrotnie". Podpinasz klucz z jakimś gównomodelem typu gpt-4o/gemini flash 3 za 5gr. Strona staje się viralem bo każdy chcę chociaż raz spróbować. Podpinasz pod stronę jakąś reklamę lub reflink. Strona notuje milion wyświetleń w tydzień i zdycha. Odbierasz profit i stawiasz coś innego.
Polski

genai w służbie….. nawet nie wiem czego, po chuj to robić
Kamil Stanuch@KamilStanuch
Narzędzie stworzone pod Polskich deweloperów. Wgrywasz render ze strony dewelopera, dostajesz prawdziwą wizualizacje, jak budynek czy osiedle będzie wyglądać we wtorek w Listopadzie.
Polski
@ArmenShimoon @GenAI_is_real There are no gains from AI in planning. Its too complex, even impossible to fit relevant info in context. Sure you can tell it to design some system that was previously already scoped out by a sr eng, but AI can't design or plan end to end coordinating multiple teams and products
English

@_luki222 @GenAI_is_real Companies need to refactor their organization and processes, not code. Agents can refactor the code just fine, but overbloated and slow moving people will continue to be in the way, preventing AI unlocks and gains from being realized.
English

FAANG is literally panicking refactoring because human code is now the bottleneck. But honestly, monorepos won't save them from the infinite spaghetti code agents are about to dump. OAI already has internal tools for this that make Bazel look like a toy. The era of human "senior engineers" is ending faster than you think @karpathy @sama
Samswara@samswoora
Rumor is FAANG style co’s are refactoring their monorepos to scale in preparation for infinite agent code
English



The software engineers have been anal about code maintainability and structure because they knew that they would have to read and fix this code at some point in the future.
When AI writes and fixes the code, it can be as messy (from the human software engineer's anal point of view) as it could be, and this wouldn't matter because no human would have to read and fix this code at some point in the future.
Leave machine commands to the machine to write and fix. Do a human thing: make decisions under uncertainty.
English
@tomo9000p @lamontcraynston We will not get systemic collapse from openai running out of funds though
English

@lamontcraynston At first glance, sure. But in the event of a systemic collapse, there won’t be any winners and $Googl will get caught in the crossfire, too...
English
Mam wrażenie, ze openAI zaczyna byc 'too big to fail' I wcale bym się nie zdziwił jakby w następnej rundzie nie dołączył $googl 🙈🐈⬛
Co sądzicie?
zerohedge@zerohedge
*AMAZON IN TALKS TO INVEST UP TO $50B IN OPENAI: WSJ
Polski

There are companies actively discouraging developers from AI assisted engineering.
Others are heavily encouraging any and all automation.
One of these groups will win.
English
@progXprog Ogólnie w nie troll postach to działa tak że ludzie wstawiają screeny z gry do Genie a on tworzy świat na podstawie tego screena, dlatego to wygląda jak istniejąca gra
Polski

Obecnie mój feed jest obsrany tego typu „grami”
Chyba na tych przykładach najlepiej widać, jak AI kradnie content
Jeśli tak miałyby wyglądać gry przyszłości to może w końcu nadrobię kupkę wstydu 🙂
Alex Cohen@anothercohen
Wow. Just made my first AI video game with Google’s Genie 3 The prompt: "A realistic high-speed racing game where you have to escape the cops. Ignore all laws of physics" The gaming industry is so cooked
Polski
@TheAhmadOsman It has to land and be profitable for Google otherwise what's the point? Giving away free Gemini 3 Pro doesn't make sense long term.
English


@josefbender_ The answer like everything in software engineering is "it depends"
English



We are hiring for 50+ roles just reach out of you are passionate about the future of robotics and AI
microagi@microagi
We're hiring. We're building the world's largest dataset of human tasks, from folding laundry to operating nuclear power plants. At this stage, your work will define the company and the future of humanity. If you're genuinely obsessed with AI and robotics, reach out. We're especially looking for engineers and ops/marketing people, but we want to talk to anyone who thinks they belong here. Munich (engineering and ops), Mumbai/Pune/Cape Town (ops). Come build abundance with us and work with frontier labs. careers@micro-agi.com
English