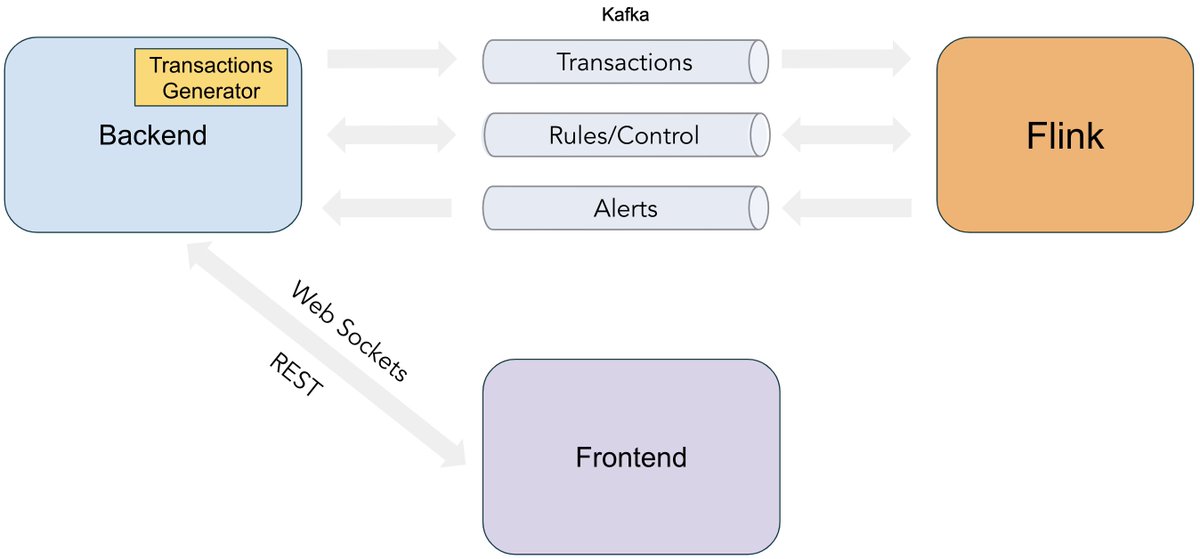
Wrote a tutorial on how to create a lakehouse-based AI evaluation platform using open-source stack.
Blog: saumitra.me/2026/2026-03-0…
Code: github.com/saumitras/ai-e…
We will see how to solve typical scale problems like:
1. Fragmented tooling: each team builds its own eval tooling, schemas, and scoring logic
2. No shared standard: model, prompt, retriever, and dataset versions are tracked inconsistently, making cross-team governance and cross-team knowledge sharing hard.
3. Weak lineage: teams can see a score change but cannot reliably answer what exact configuration caused it.
4. Poor observability: traces and metrics are often separated from run metadata, which slows root-cause analysis.
5. Replay gaps: failures found in production cannot be deterministically reproduced for safe comparisons.
6. Throughput limits: simple eval pipelines cannot keep up with enterprise-scale experiment volume.
7. BI disconnect: analytics teams cannot query cross-app eval data easily through a single pane
8. Failure patterns stay hidden: teams see individual failed cases, but without clustering they miss recurring failure modes and cannot prioritize fixes effectively.
Technologies: AWS #S3, @ApacheIceberg, @apachepolaris , @ApacheAirflow, @deepeval , @raydistributed , @apachekafka , @ApacheSpark , @PostgreSQL , @trinodb , @apachesuperset , Google Agent Development Kit, @OpenAI , #llm, #mcp
English