Sabitlenmiş Tweet
Xudong Guo
25 posts

Xudong Guo
@_traceur__
Researcher @Alibaba_Qwen | Ph.D. @Tsinghua_Uni | Prev. @Microsoft @UN @Princeton | Test-Time Scaling of AI Agent
Katılım Kasım 2023
183 Takip Edilen88 Takipçiler

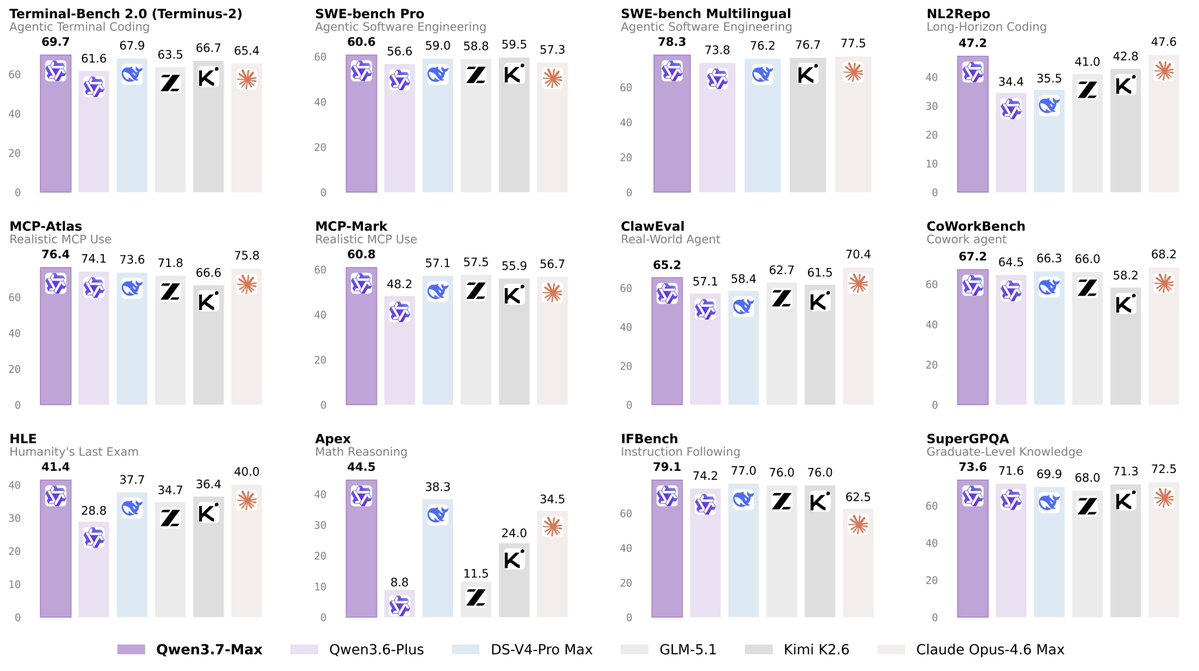
Qwen3.7-Max pushes the Pareto frontier of in-context learning to a new level 🚀 Even beats Opus 4.7 and GPT 5.5 with less cost
atomic.chat@atomic_chat_hq
Qwen 3.7-max beats Opus 4.7 and GPT-5.5 We tested three frontier models on a real agentic task: write a Tetris bot that plays the game and trains itself. Each model could read its own code, run benchmarks, and rewrite itself across 10 iterations. Then we compared the final bots head to head. Qwen 3.7-Max: training cost $1.32, bot improvement +56% Claude Opus 4.7: training cost $12.15, bot improvement +28% GPT-5.5: training cost $2.85, bot improvement +7% Qwen won on every dimension - biggest jump, 9× cheaper than Claude, 2× cheaper than GPT. Long agentic loops is where Qwen Max actually delivers.
English
@kimmonismus Also, we got the 10x speedup on Alibaba's brand new PPU chips, never seen during training
English

Alibaba released Qwen 3.7 max. Benchmarks incredible.
Their new model ran autonomously for 35 hours, made 1,158 tool calls, and achieved a 10x speedup - on a single attention kernel.
This isn't "AI improving itself across the board." It's a model grinding through compile-profile-rewrite loops on one well-defined optimization target.
Impressive? Absolutely. The kind of self-improvement people will imagine when they see the headline? Not yet.
The actually interesting claim is buried deeper: Qwen says agentic capabilities generalize from diverse training environments the same way language capabilities generalize from diverse text. If that holds, it's a bigger deal than any benchmark number.

Qwen@Alibaba_Qwen
📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era. A versatile foundation for agents that actually get things done: 🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it. 🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration. ⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding. 🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere. API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio. Go build something wild!🏃🏃♂️ 📖 Blog: qwen.ai/blog?id=qwen3.7 ✅ Qwen Studio: chat.qwen.ai/?models=qwen3.… ⚡️ API:modelstudio.console.alibabacloud.com/ap-southeast-1…
English
@rohanpaul_ai we got the 10.0x speedup on unseen PPUs instead of the training GPUs. Qwen 3.7 was learning while exploring.
English

Alibaba just released Qwen3.7-Max.
Their best flagship model built for real-world tasks and production environments.
- Agent reliability the center of the story, where the model must plan steps, call tools, inspect results, fix mistakes, and continue without collapsing after the first wrong turn.
- 56.6 on the Artificial Analysis Intelligence Index, up 4.8 points from Qwen3.6-Max. Qwen 3.7 Max sitting at 5th, pretty much on par with GPT 5.4 (xhigh)
- The Intelligence Index gains over Qwen3.6 Max Preview are concentrated in scientific reasoning, agentic capability and coding.
- One important layer of the serving stack, the inference kernel, was optimized heavily. from near-baseline speed to 10.0x geometric mean speedup after many rounds of low-level GPU optimization.


Qwen@Alibaba_Qwen
📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era. A versatile foundation for agents that actually get things done: 🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it. 🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration. ⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding. 🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere. API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio. Go build something wild!🏃🏃♂️ 📖 Blog: qwen.ai/blog?id=qwen3.7 ✅ Qwen Studio: chat.qwen.ai/?models=qwen3.… ⚡️ API:modelstudio.console.alibabacloud.com/ap-southeast-1…
English
Scaling still works
Artificial Analysis@ArtificialAnlys
Alibaba’s new Qwen3.7 Max model scores 56.6 on the Artificial Analysis Intelligence Index, 4.8 points higher than Qwen3.6 Max Preview (51.8). While Alibaba still trails models from OpenAI, Anthropic and Google, Qwen3.7 Max is the closest they have been to the frontier Qwen3.7 Max is @Alibaba_Qwen's latest proprietary flagship, scoring 56.6 on the Intelligence Index, a 4.8 point gain over Qwen3.6 Max Preview (51.8) released in April. Qwen3.7 Max continues Alibaba's pattern, in place since Qwen2.5 Max (January 2025), of releasing Max and Plus models as closed weights while the rest of the Qwen line remains open weights. The leading open weights Qwen on the Intelligence Index is Qwen3.6 27B (Reasoning, 45.8) released in April 2026, and the leading open weights MoE Qwen is Qwen3.5 397B A17B (Reasoning, 45.0) released in February 2026 Key takeaways for the reasoning variant: ➤ The Intelligence Index gains over Qwen3.6 Max Preview are concentrated in scientific reasoning, agentic capability and coding. CritPt +9.7 p.p (3.7% to 13.4%), HLE +9.2 p.p (28.9% to 38.1%), TerminalBench Hard +6.9 p.p (43.9% to 50.8%) and GDPval-AA +42 Elo (1504 to 1546). Scores on other benchmarks in the Intelligence Index are flat compared to Qwen3.6 Max Preview ➤ A significant share of the Intelligence Index gain is driven by higher abstention on AA-Omniscience, not higher accuracy. Qwen3.7 Max's accuracy on AA-Omniscience dropped 7.6 p.p (37.7% to 30.1%), while its hallucination rate dropped 21.3 p.p (44.2% to 22.9%). The model is choosing not to answer more questions rather than recalling more facts. Because hallucination rate and accuracy both feed into the Intelligence Index, the hallucination reduction is one of the larger single contributors to the +4.8 point gain on the Intelligence Index ➤ Qwen3.7 Max used 96.7M output tokens to run the Intelligence Index, ~31% more than Qwen3.6 Max Preview (73.9M). It sits mid-pack on frontier token usage: above GPT-5.5 (high, 44.5M) and Gemini 3.1 Pro Preview (57.3M), below Claude Opus 4.7 (Adaptive Reasoning, Max Effort, 112M), Kimi K2.6 (166M) and DeepSeek V4 Pro (Reasoning, Max Effort, 187M) Key model details: ➤ Context window: 1M tokens (up from 256K on Qwen3.6 Max Preview) ➤ Multimodality: Text input and output only ➤ Pricing: Yet to be announced (Qwen3.6 Max Preview is priced at $1.30/$7.80 per 1M input/output tokens on the @alibaba_cloud first-party API) ➤ Licensing: Proprietary, closed weights
English
@0xsachi Yes! And we are working on more long-horizon real-world tasks. Stay tuned for the next version!
English

Qwen 3.7 significantly outperforms old models in startup decision making 👀

English
Qwen3.7-Max can also power embodied agents: controlling robot dogs via tool calls w/ real-time perception, planning, memory & decision-making in physical worlds, to finish long-term tasks more than 20 mins.
xiong-hui (barry) chen@xiong_hui_chen
One more thing 🚀 Qwen’s agentic capability is no longer limited to the digital world — we’re bringing it into physical world. With our in-house robotic agentic system and navigation model, Qwen can now control a robot to execute tasks in real-world. #qwen #embodied #robotics
English
Xudong Guo retweetledi

📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era.
A versatile foundation for agents that actually get things done:
🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it.
🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration.
⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding.
🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere.
API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio.
Go build something wild!🏃🏃♂️
📖 Blog: qwen.ai/blog?id=qwen3.7
✅ Qwen Studio: chat.qwen.ai/?models=qwen3.…
⚡️ API:modelstudio.console.alibabacloud.com/ap-southeast-1…

English
Xudong Guo retweetledi
🚀🚀Qwen3.7 Preview lands on Arena !
Here come Qwen3.7-Max-Preview & Qwen3.7-Plus-Preview. Alibaba now #6 lab in Text, #5 in Vision.⚡️⚡️
Can't wait to release Qwen3.7 series models!Stay tuned! @arena
Arena.ai@arena
Qwen3.7 Preview By @Alibaba_Qwen lands on Arena for Text and Vision. In Text Arena, Qwen3.7 Max Preview ranks #13 overall. Alibaba is now the #6 lab in this arena. - #7 Math - #9 Expert - #9 Software & IT - #10 Coding In Vision Arena: Qwen3.7 Plus Preview ranks #16 overall, making Alibaba the #5 lab. Congrats to the @Alibaba_Qwen team on the latest progress!
English
Planning + Reflection + Memory -> Long-Horizon Decision-Making
Qwen@Alibaba_Qwen
🚀 Introducing DeepPlanning — a new benchmark for long-horizon agent planning in real-world scenarios. Unlike step-by-step reasoning tasks, we focus on verifiable global constraints: time budgets, cost limits, and combinatorial optimization that must hold across the entire plan. ✈️ Multi-day travel w/ minute-level scheduling + hard time/budget caps 🛒 Complex shopping w/ coupon stacking & item bundling 🧠 Requires active info gathering, local constraint satisfaction & global optimality Even GPT-5.2, Claude 4.5, Gemini & Qwen3 struggle significantly. Perfect for evaluating Agent Planning / Tool Use / Long-Horizon Reasoning. Paper: arxiv.org/pdf/2601.18137 Leaderboard: qwenlm.github.io/Qwen-Agent/en/… Hugging Face Dataset: huggingface.co/datasets/Qwen/… ModelScope Dataset: modelscope.cn/datasets/Qwen/…
English
@Shawnhhhhh There is no separate memory module, but we introduce the memory capacity to both the new model Max and the Qwen-Chat platform.
English

Try agentic memory here: chat.qwen.ai
Qwen@Alibaba_Qwen
🚀 Introducing Qwen3-Max-Thinking, our most capable reasoning model yet. Trained with massive scale and advanced RL, it delivers strong performance across reasoning, knowledge, tool use, and agent capabilities. ✨ Key innovations: ✅ Adaptive tool-use: intelligently leverages Search, Memory & Code Interpreter without manual selection ✅ Test-time scaling: multi-round self-reflection beats Gemini 3 Pro on reasoning ✅ From complex math (98.0 on HMMT Feb) to agentic search (49.8 on HLE)—it just thinks better. 🧠 Think deeper. Solve harder. Try the adaptive reasoning experience now: chat.qwen.ai Completions API: modelstudio.console.alibabacloud.com/ap-southeast-1… Responses API: alibabacloud.com/help/en/model-… blog: qwen.ai/blog?id=qwen3-…
English
Xudong Guo retweetledi
Xudong Guo retweetledi

thanks for the great eval that helps our research!
Lightwheel@LightwheelAI
RoboFinals is Lightwheel's industrial grade evaluation platform for measuring Embodied AI model capabilities beyond academic benchmarks. It enables faster iteration, bottleneck diagnosis, and reliable measurement of real capability gains as models move toward real-world deployment. We’re excited to have @Alibaba_Qwen using RoboFinals for high-throughput, industry-aligned evaluation of its frontier embodied AI models. RoboFinals enables Qwen to rapidly iterate, diagnose bottlenecks, and measure real capability gains beyond academic benchmarks. Besides, Qwen plays a partner in stress-testing RoboFinals and shaping its evolution into an industry standard benchmark for evaluating robotics foundation models. #Lightwheel #Qwen #RoboFinals #EmbodiedAI #Robotics #Simulation #Evaluation
English
Xudong Guo retweetledi
🏆 We are incredibly honored to announce that our paper, "Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free" has received the NeurIPS 2025 Best Paper Award!
A huge congratulations to our dedicated research team for pushing the boundaries of AI.
Read more: blog.neurips.cc/2025/11/26/ann…

English
Not just a chat app, but an agent with more exciting features on the way...
Qwen@Alibaba_Qwen
10,000,000 users creating with Qwen Chat — and we’re just getting started. From here, let’s begin — chat.qwen.ai 🚀
English

@_traceur__ Hi Xudong! We tried to message you with the early access information, but unfortunately your DMs are closed to the public. Do you mind opening those up so that we can get you the early access details? Thanks so much!
English
🚨 We’re reaching out to a few of you in DMs with early access to something huge.
This is one of the first major open-source drops of its kind in the U.S., and it’s almost here.
If you’ve already heard from us, you’re in. If not, no worries! we still have a few spots left before launch next week.
👇 Drop “POKEE” in the comments to lock in early access before we go live!

English