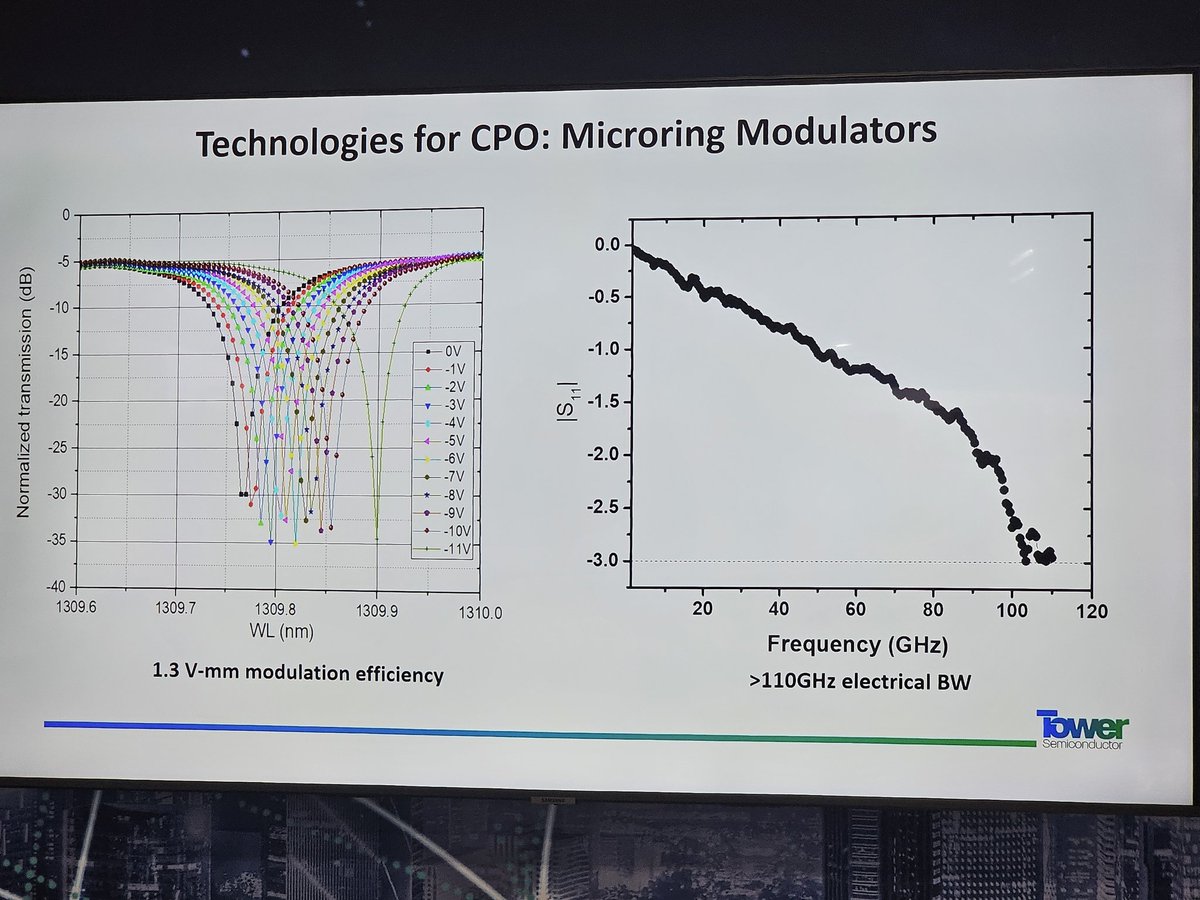
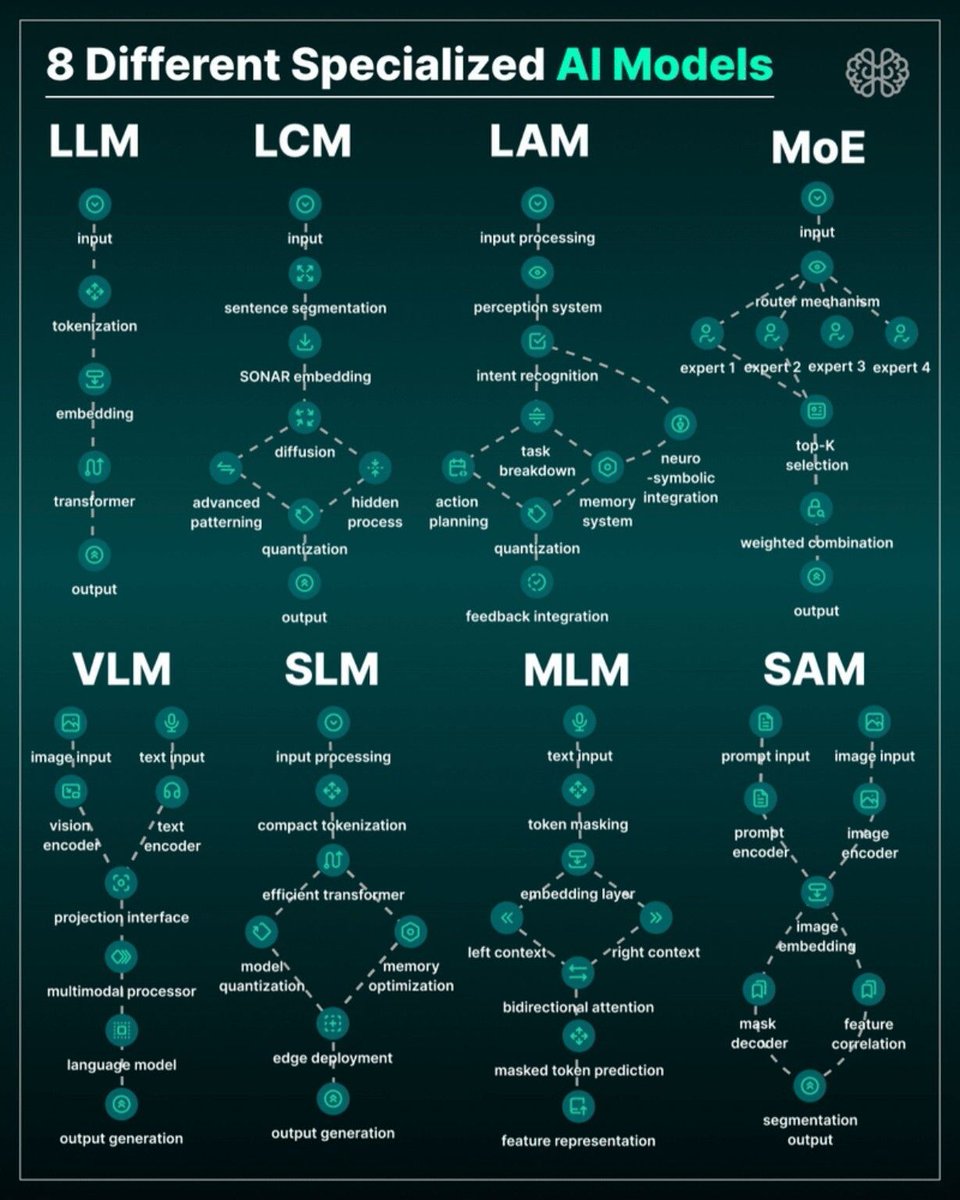
Serenity@aleabitoreddit
The upcoming CPO / Silicon Photonics Bottleneck Cheat Sheet:
$SIVE, Sumitomo, $LITE, $COHR, $AVGO, $MTSI, $AAOI - Light Source (CW DFB Lasers)
$TSEM, $GFS, $UMC, $TSM, $INTC - SiPh foundry
$NOK, $CIEN, $CSCO, $COHR - DCO
$HIMX, FOCI (3363.TWO) - Micro-lens + Fiber Arrays
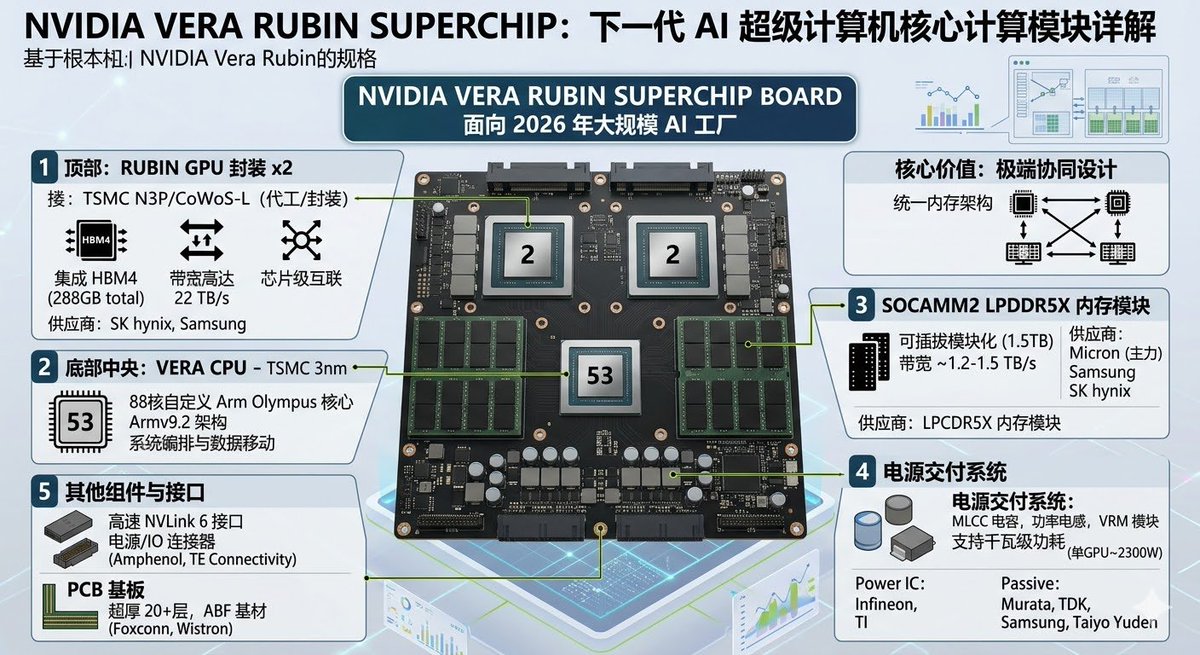
$POET - Optical Interposers
$SOI, $AXTI, Shin-Etsu - Substrates
$FN, $ASX, Innolight, Eoptolink - Optical Packaging and Assembly
$MTSI, $SMTC, $MRVL, $MXL - Analog/Mixed-Signal ICs
$LWLG - Speculative Modulator Materials.
$GLW, $APH, $TEL, $FIT, Fujikura - Connectors and Fibers
$FORM, $KEYS, $VIAV, $AEHR- Test & Measurement
$BESI, $SMHN, $ONTO, $CAMT - Advanced Packaging & Hybrid Bonding
Many are private companies from Lightmatter, Ayar, Ranovus and others.
Now... Everyone is asking... How do you profit?
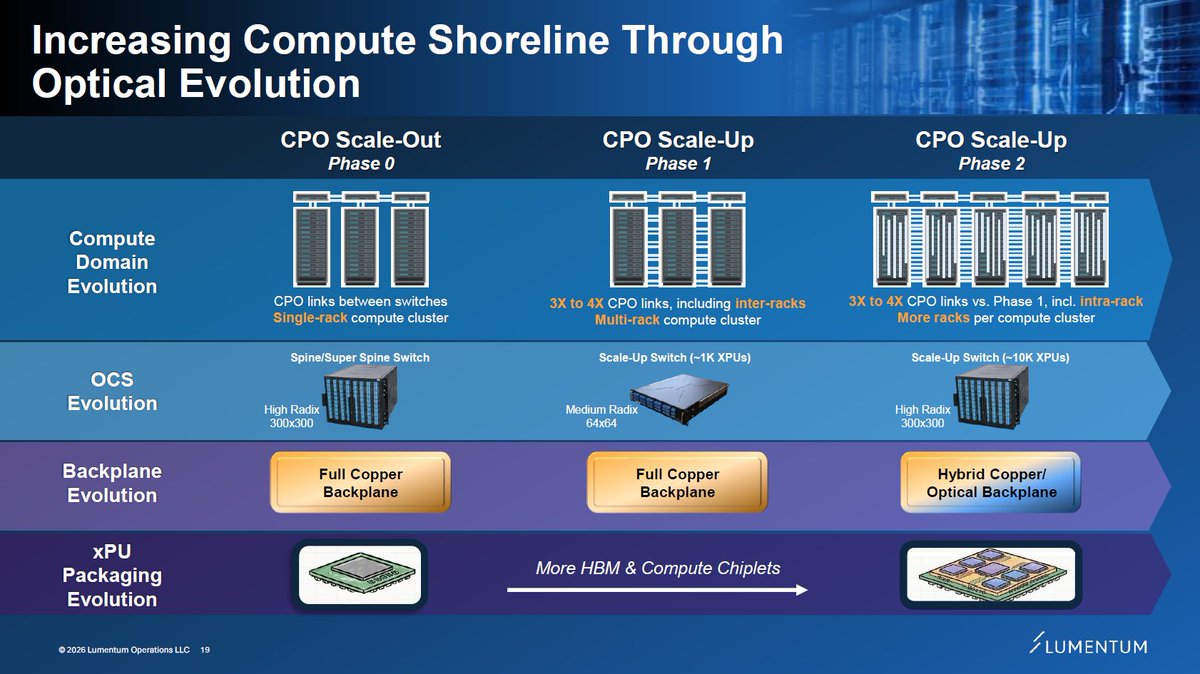
If you look at the forecast for CPO TAM, it's a straight line up, and next year is inflection point for CPO mass deployment.
The alpha is capturing the rotation:
From the current EML bottlenecks ( $LITE, $COHR type) to SiPh / CW DFB architectural winners for CPO.
Highest upside potential are the ones that aren't included in current cycles.
But that are in the next.
Companies like $SOI, $SIVE, or $AEHR are perfect examples.
Ride the current pluggable bottleneck like $AAOI.
But the alpha is frontrunning institutions with the next CPO bottleneck.
The capital rotation is inevitable.