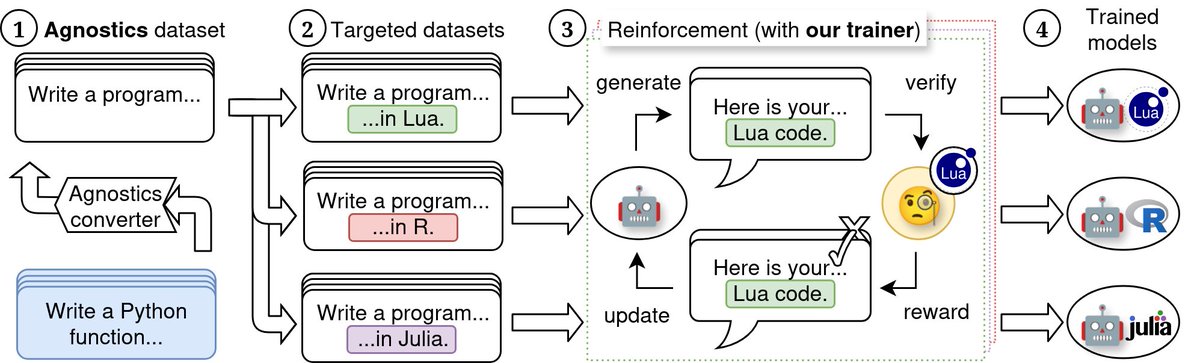
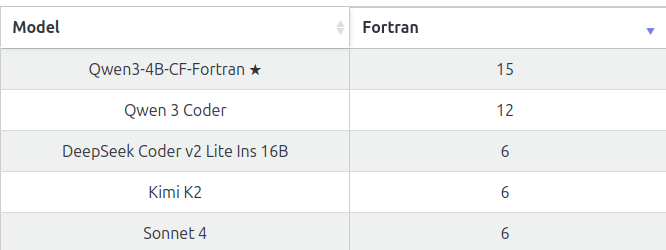
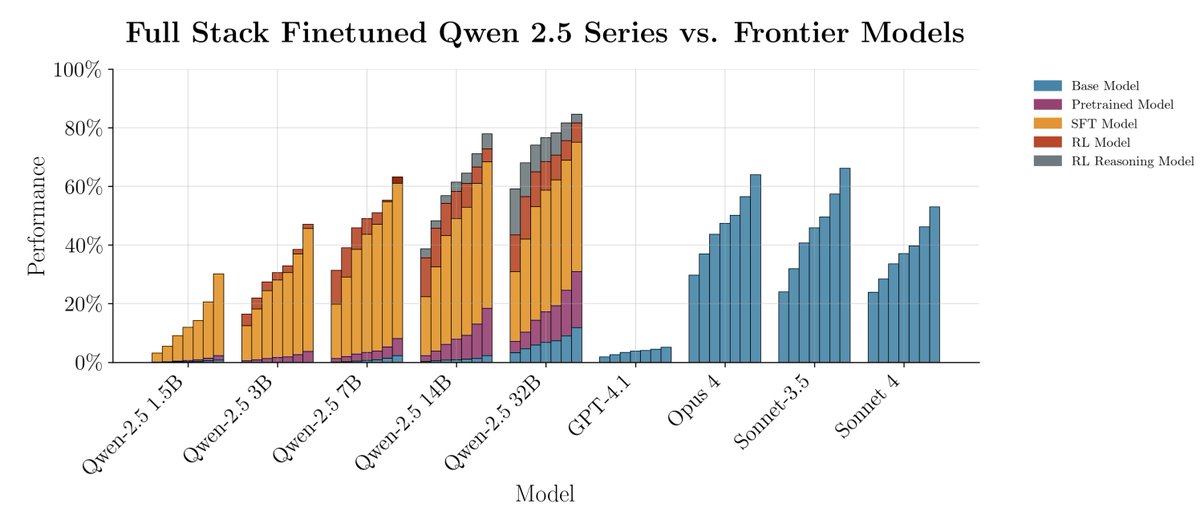
One takeaway from ProgramBench is that some current LLMs tend to give up too early. I'm curious what happens if we prompt models to work until timeout, since long-running autonomous agent have interesting issues! See link mazesofmenace.ai/announcement/ /cc @jyangballin @KLieret
English