
Accuney | Free Graphics
560 posts

Accuney | Free Graphics
@accuney
Free banners • logos • memes • TG stickers for your launch / CTO. Working for my bags one pixel at a time. No paid services 😎 Trojan: https://t.co/p6hnl3huts
Katılım Aralık 2025
56 Takip Edilen31 Takipçiler
Accuney | Free Graphics retweetledi



Niggas will do all this dumb shit then blame a launchpad😭😭😭😭😭
I dont like everything bonk, pump, moonshot, fomo etc do and think they should emphasize more community shit
But to blame them SOLELY for how WE behave is fucking asinine.
Them niggas aint tell u to jeet and farm 10-30k coins all day
English
Accuney | Free Graphics retweetledi


@Solana_Monk3 @toly I guess $MONKE inflates this time up :)
English
Accuney | Free Graphics retweetledi



MetaTimer: Using Large Language Models for Precise, Prompt-Aware Inference Latency Prediction
The rapid proliferation of large language models (LLMs) in production systems has exposed a fundamental limitation: inference latency varies dramatically across prompts due to differences in semantic complexity, required reasoning depth, output length, and generation dynamics. Conventional prediction methods—ranging from token-count heuristics and hardware Roofline models to traditional machine-learning regressors—fail to generalize because they cannot capture these prompt-specific nuances. Accurate a priori estimation of processing time is essential for resource scheduling, dynamic batching, cost forecasting, service-level guarantees, and user-experience enhancements.
We introduce MetaTimer, the first framework to repurpose a lightweight LLM itself as a high-precision meta-predictor capable of forecasting the exact wall-clock inference duration required by any target LLM for an arbitrary input prompt. A compact 8B-parameter model is fine-tuned on a massive corpus of millions of prompt–execution pairs collected across heterogeneous model families (GPT-4-class, Llama 3.1, Claude, Mistral), quantization levels, decoding strategies, and hardware accelerators. The predictor employs chain-of-thought reasoning to decompose prompt semantics, estimate output token distributions and reasoning trajectories, and integrate model- and hardware-specific performance profiles, yielding fine-grained predictions for Time-to-First-Token (TTFT), Time-Per-Output-Token (TPOT), and total latency.
Extensive evaluations on held-out benchmarks spanning reasoning, creative writing, coding, and long-context tasks demonstrate state-of-the-art accuracy: a mean absolute percentage error (MAPE) of 6.3% for end-to-end latency—representing a >40% reduction in mean squared error relative to the strongest Roofline–ML baselines—and strong zero-shot generalization to unseen models and platforms. When integrated into production serving stacks (vLLM, TensorRT-LLM, Triton), MetaTimer delivers up to 31% gains in resource utilization and tail-latency reduction.
These results establish that LLMs possess emergent capabilities for computational self-modeling, opening a new paradigm for self-aware, adaptive, and energy-efficient generative AI infrastructure. We publicly release the predictor model, dataset, and serving plugins to accelerate research in meta-performance modeling for frontier AI systems.
English
Accuney | Free Graphics retweetledi

Accuney | Free Graphics retweetledi


Accuney | Free Graphics retweetledi

Accuney | Free Graphics retweetledi


Accuney | Free Graphics retweetledi


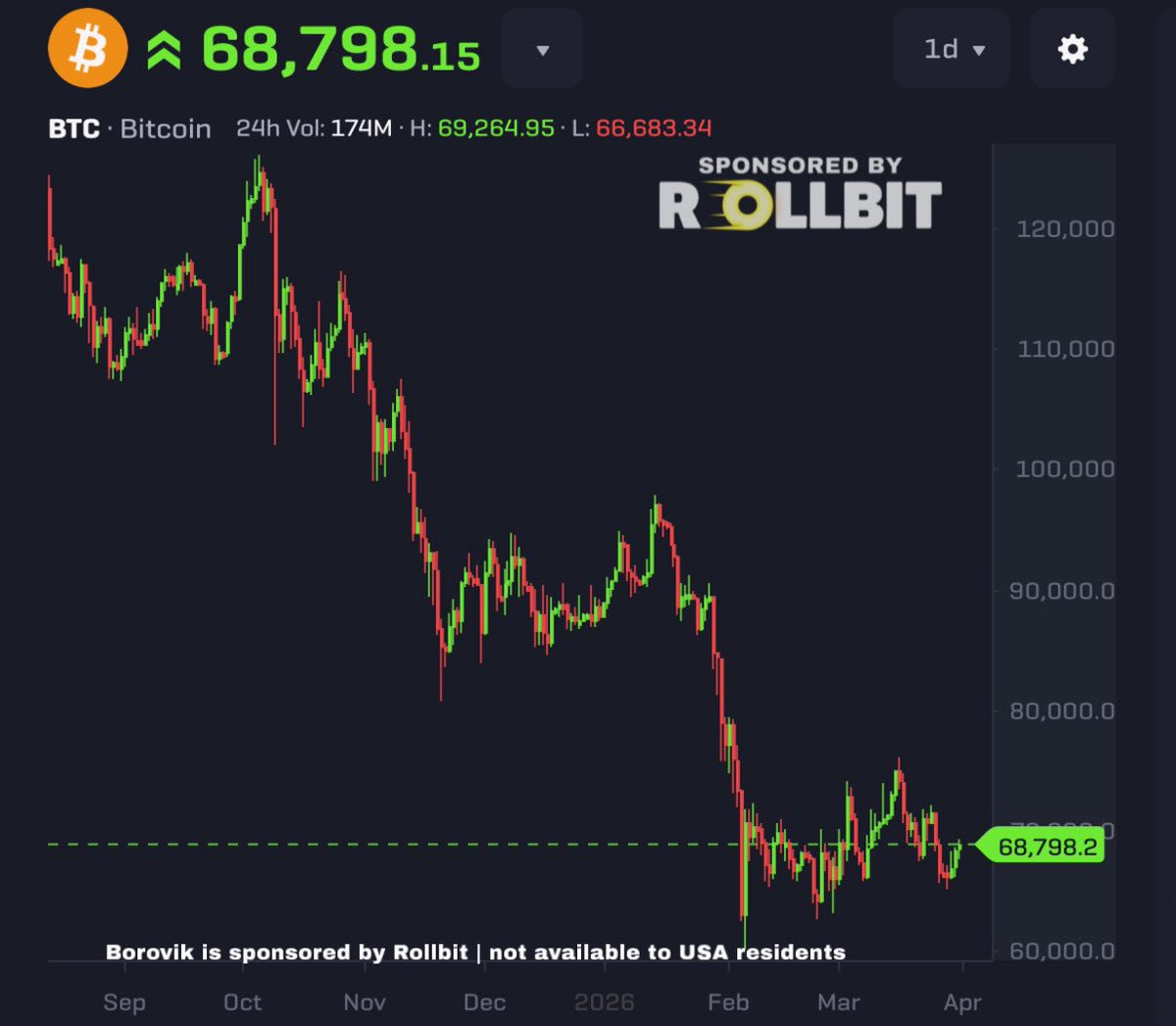
Accuney | Free Graphics retweetledi


Accuney | Free Graphics retweetledi

Off to seal some Monke-ky business deals 🙈😎
Let's get that 100K floor tonight.
The grand never stops 🐵✌️
@Solana_Monk3

English


