Achintya
15 posts


@sushobhitxd @Owasp_tiet @Goyal2608 Rev-engineering should've been there man, would've been more fun😂
English

English
been a while i posted
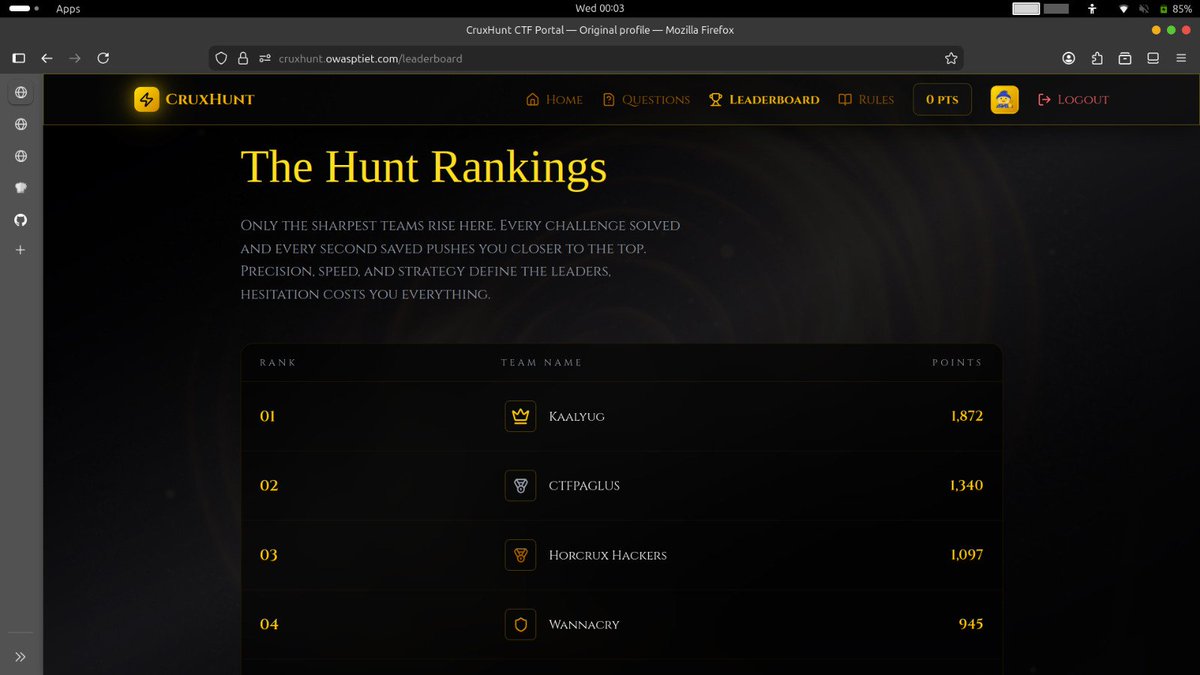
finished this cruxhunt CTF this weekend at 4th. We're maintaing the 3rd position till last round but that prompt injection and image forensics question had us bad.
onto the next one ~
@Owasp_tiet
English
GIF
English
@Rishi2220 @iclr_conf Aeyoo that's big, all the best with the submission G.
English

Transforming human knowledge, sensors and actuators from human-first and human-legible to LLM-first and LLM-legible is a beautiful space with so much potential and so much can be done...
One example I'm obsessed with recently - for every textbook pdf/epub, there is a perfect "LLMification" of it intended not for human but for an LLM (though it is a non-trivial transformation that would need human in the loop involvement).
- All of the exposition is extracted into a markdown document, including all latex, styling (bold/italic), tables, lists, etc. All of the figures are extracted as images.
- All worked problems get extracted into SFT examples. Any referenced made to previous figures/tables/etc. are parsed and included.
- All practice problems are extracted into environment examples for RL. The correct answers are located in the answer key and attached. Any additional information is added as "answer key" for a potential LLM judge.
- Synthetic data expansion. For every specific problem, you can create an infinite problem generator, which emits problems of that type. For example, if a problem is "What is the angle between the hour and minute hands at 9am?" , you can imagine generalizing that to any arbitrary time and calculating answers using Python code, and possibly generating synthetic variations of the prompt text.
- All of the data above could be nicely indexed and embedded into a RAG database for later reference, or maybe MCP servers that make it available.
Then just as a (human) student could take a high school physics course, an LLM could take it in the exact same way. This would be a significantly richer source of legible, workable information for an LLM than just something like pdf-to-text (current prevailing practice), which simply asks the LLM to predict the textbook content top to bottom token by token (umm - lame).
As just a quick and crappy example of synthetic variations of the above example, GPT-5 gave me this problem generator (see image), which can now generalize that problem template to many variations:
- When the time is 11:07 a.m., what is the degree measure of the angle between the hands? (Answer: 68)
- Determine the angle in degrees between the clock’s hands at 4:14 a.m.. (Answer: 43)
- What angle do the clock hands form when the time reads 11:47 a.m.? (Answer: 71)
- At 7:02 a.m., what angle separates the hour hand and the minute hand? (Answer: 161)
- At 4:14 a.m., calculate the angle made between the two hands. (Answer: 43)
- What angle is formed by the hands of a clock at 4:45 p.m.? (Answer: 127)
- What is the angle between the hour and minute hands at 8:37 p.m.? (Answer: 36)
(infinite practice problems can be created...)

English
Continuing the journey of optimal LLM-assisted coding experience. In particular, I find that instead of narrowing in on a perfect one thing my usage is increasingly diversifying across a few workflows that I "stitch up" the pros/cons of:
Personally the bread & butter (~75%?) of my LLM assistance continues to be just (Cursor) tab complete. This is because I find that writing concrete chunks of code/comments myself and in the right part of the code is a high bandwidth way of communicating "task specification" to the LLM, i.e. it's primarily about task specification bits - it takes too many bits and too much latency to communicate what I want in text, and it's faster to just demonstrate it in the code and in the right place. Sometimes the tab complete model is annoying so I toggle it on/off a lot.
Next layer up is highlighting a concrete chunk of code and asking for some kind of a modification.
Next layer up is Claude Code / Codex / etc, running on the side of Cursor, which I go to for larger chunks of functionality that are also fairly easy to specify in a prompt. These are super helpful, but still mixed overall and slightly frustrating at times. I don't run in YOLO mode because they can go off-track and do dumb things you didn't want/need and I ESC fairly often. I also haven't learned to be productive using more than one instance in parallel - one already feels hard enough. I haven't figured out a good way to keep CLAUDE[.]md good or up to date. I often have to do a pass of "cleanups" for coding style, or matters of code taste. E.g. they are too defensive and often over-use try/catch statements, they often over-complicate abstractions, they overbloat code (e.g. a nested if-the-else constructs when a list comprehension or a one-liner if-then-else would work), or they duplicate code chunks instead of creating a nice helper function, things like that... they basically don't have a sense of taste. They are indispensable in cases where I inch into a more vibe-coding territory where I'm less familiar (e.g. writing some rust recently, or sql commands, or anything else I've done less of before). I also tried CC to teach me things alongside the code it was writing but that didn't work at all - it really wants to just write code a lot more than it wants to explain anything along the way. I tried to get CC to do hyperparameter tuning, which was highly amusing. They are also super helpful in all kinds of lower-stakes one-off custom visualization or utilities or debugging code that I would never write otherwise because it would have taken way too long. E.g. CC can hammer out 1,000 lines of one-off extensive visualization/code just to identify a specific bug, which gets all deleted right after we find it. It's the code post-scarcity era - you can just create and then delete thousands of lines of super custom, super ephemeral code now, it's ok, it's not this precious costly thing anymore.
Final layer of defense is GPT5 Pro, which I go to for the hardest things. E.g. it has happened to me a few times now that I / Cursor / CC are all stuck on a bug for 10 minutes, but when I copy paste the whole thing to 5 Pro, it goes off for 10 minutes but then actually finds a really subtle bug. It is very strong. It can dig up all kinds of esoteric docs and papers and such. I've also used it for other meatier tasks, e.g. suggestions on how to clean up abstractions (mixed results, sometimes good ideas but not all), or an entire literature review around how people do this or that and it comes back with good relevant resources / pointers.
Anyway, coding feels completely blown open with possibility across a number of "kinds" of coding and then a number of tools with their pros/cons. It's hard to avoid the feeling of anxiety around not being at the frontier of what is collectively possible, hence random sunday shower of thoughts and a good amount of curiosity about what others are finding.
English
@Aryaman1702 We do need that, what work is required to put it all together?
English

@TensorTonic Your vision with TensorTonic is cool , you guys got a link for the thing?
English

Tested the model on 20 prompts , with a mix of basic prompts , translation tasks , role-based and few shot prompts , bidirectional and RAG Styled prompts. The model performed decent on all except from role-based and few shot, and also, it was unable to structure its outputs.


English



- start training cnn at night (thousands of images)
-begin to feel bored (watching the epoch bar)
- fall asleep
- forgot to turn off the screen saver
- wake up in the morning to see the disconnected GPU
- feel frustrated
- close the notebook
- will try someday in future
#aiml

English

I’ve been building a C++ UI SDK from scratch, no dependencies, cross-platform, pixel-level rendering.
FernKit 0.1.0 beta is out.
Launch blog here: rishi2220.hashnode.dev/fernkit
retwts appreciated.

English
Achintya retweetledi

The open source DeepSeek-R1 model is now available as an NVIDIA NIM microservice preview on build.nvidia.com to help developers securely experiment with its advanced AI reasoning capabilities.
NVIDIA AI Developer@NVIDIAAIDev
Securely experiment and build your own specialized agents, as the 671-billion-parameter DeepSeek-R1 model is now available as an NVIDIA NIM microservice in preview on build.nvidia.com. Learn more ➡️ nvda.ws/4grQaBq
English