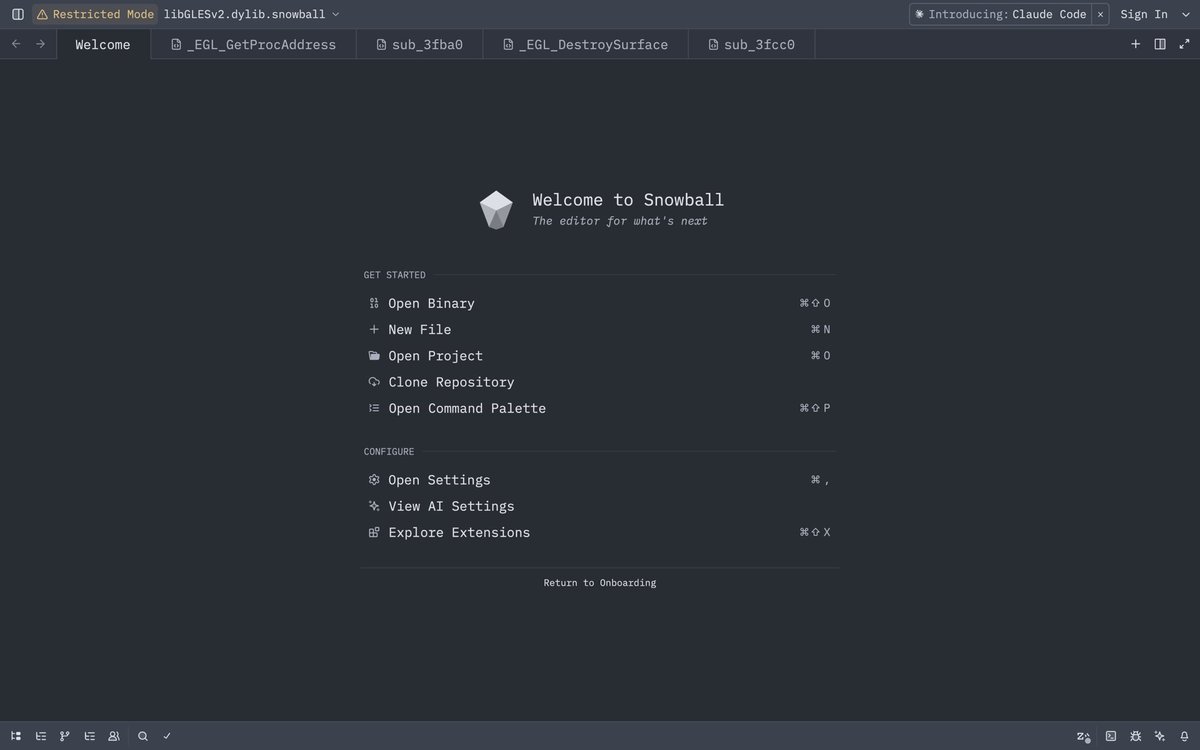
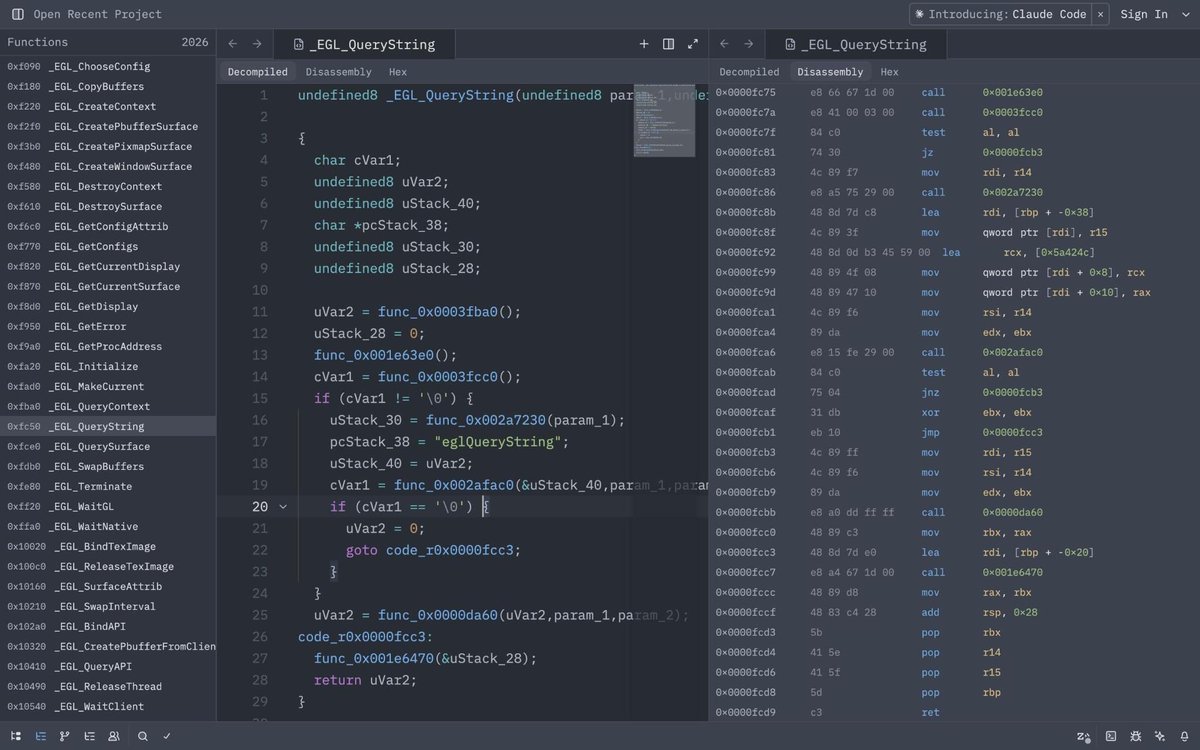
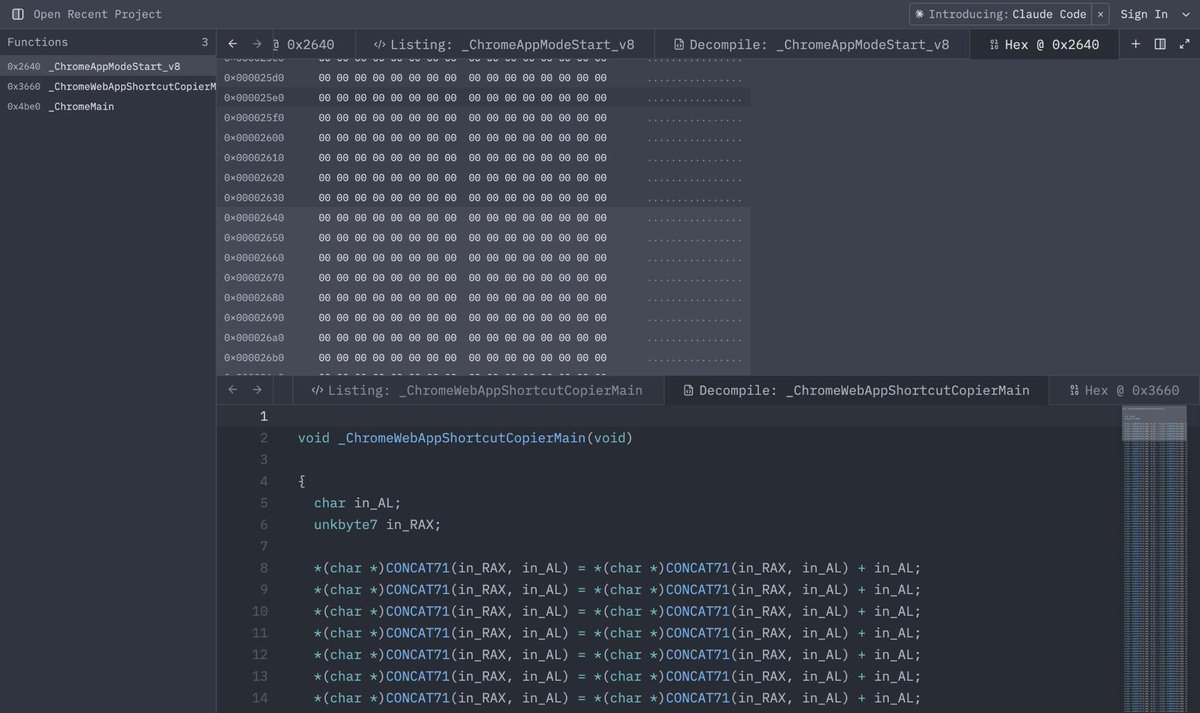
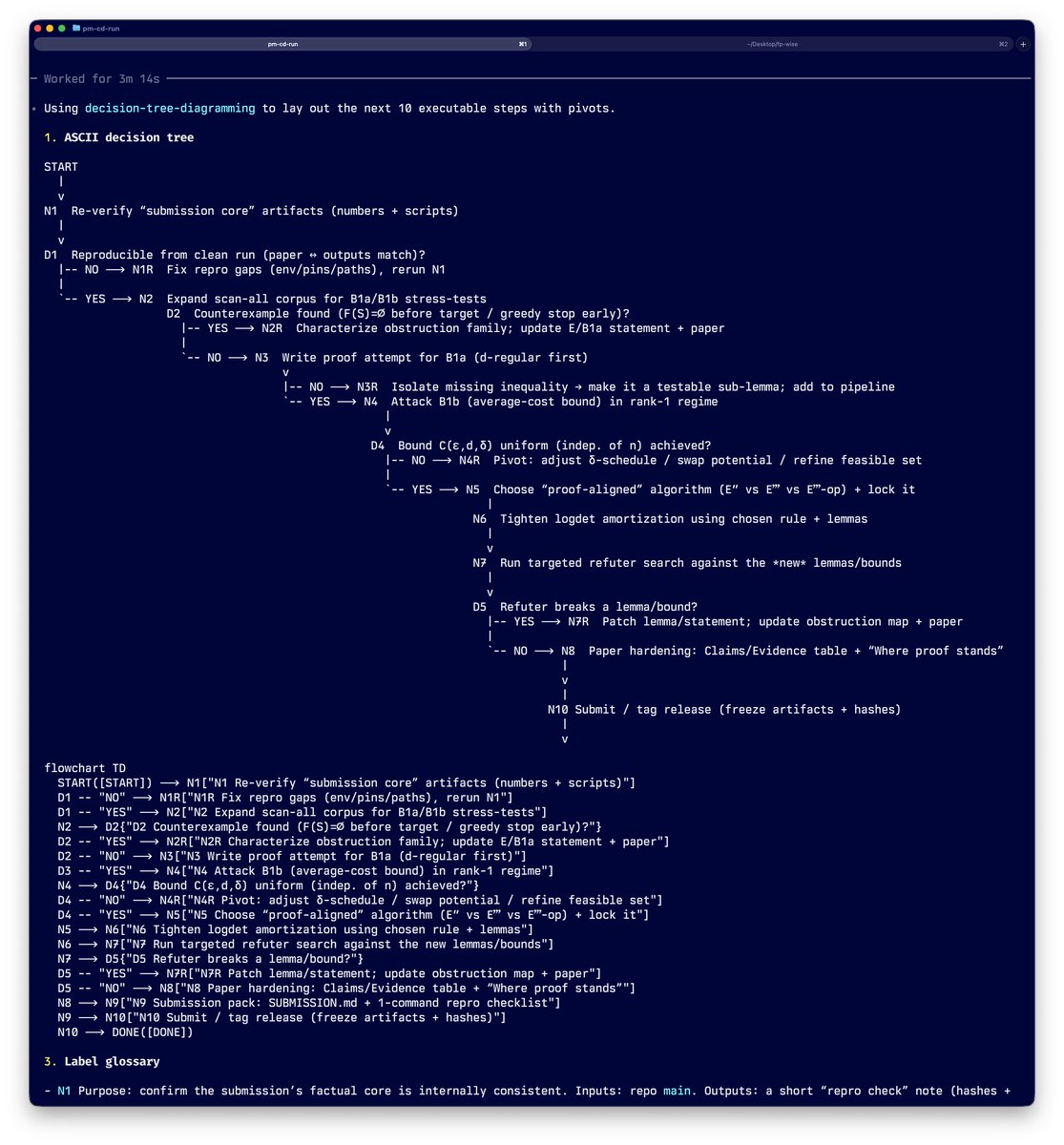
@PinkDraconian While everyone is building vuln discovery agents and workflows, the real need is that of a triage tool which is grounded in the codebase.
English
Aditya Gupta
2.5K posts
@adi1391
Founder @ Attify - Breaking LLM/IoT/Mobile - CFSE Author - Formal Logic & World-Model RE - Teaching Offensive Intelligence Engineering

Axiom launched six months ago with one conviction: mathematics is the right foundation for building systems that reason. Today we announce Axiom's Series A. We raised $200M at a $1.6B+ valuation, led by @MenloVentures, to extend our lead in formal mathematics into Verified AI.



Introducing Claude Code Security, now in limited research preview. It scans codebases for vulnerabilities and suggests targeted software patches for human review, allowing teams to find and fix issues that traditional tools often miss. Learn more: anthropic.com/news/claude-co…
Introducing Claude Code Security, now in limited research preview. It scans codebases for vulnerabilities and suggests targeted software patches for human review, allowing teams to find and fix issues that traditional tools often miss. Learn more: anthropic.com/news/claude-co…

Introducing EVMbench—a new benchmark that measures how well AI agents can detect, exploit, and patch high-severity smart contract vulnerabilities. openai.com/index/introduc…
Just solved & submitted Q10 of #1stProof research-level math problems. If you can prove it, but can't trace what your proof depends on, or query which claims are still hypotheses, or machine-verify the core theorem - it's not really a proof. The initial bottleneck in solving it wasn't mathematical insight, but lack of a system for reliable research. Solving complex problems with LLMs requires a system composed of two things: 1. High-Quality World Model : the problem space 2. Traceable Way Finding : how the LLM experiments to find out the path to the ideal final state of the world model And the critical third layer: a mix of Semi-Formal and Formal Verification. For Q10 (RKHS tensor decomposition), I built: a #CFSE invariant library with explicit proved/hypothesis classification, ASIQL dependency graph queries, and a Lean4 machine-checked proof. Thanks to #FirstProof for doing this. It forced me to solve the hard infrastructure problems of doing research with LLMs - traceability, accuracy and scale. Submission at - github.com/adi0x90/firstp… Invariant Library - github.com/adi0x90/firstp… #Lean4 #AIForMath


Great work Claude 👏🏻 10+ hours.

Very excited about the "First Proof" challenge. I believe novel frontier research is perhaps the most important way to evaluate capabilities of the next generation of AI models. We have run our internal model with limited human supervision on the ten proposed problems. The problems require expertise in their respective domains and are not easy to verify; based on feedback from experts, we believe at least six solutions (2, 4, 5, 6, 9, 10) have a high chance of being correct, and some further ones look promising. We will only publish the solution attempts after midnight (PT), per the authors' guidance - the sha256 hash of the PDF is d74f090af16fc8a19debf4c1fec11c0975be7d612bd5ae43c24ca939cd272b1a . This was a side-sprint executed in a week mostly by querying one of the models we're currently training; as such, the methodology we employed leaves a lot to be desired. We didn't provide proof ideas or mathematical suggestions to the model during this evaluation; for some solutions, we asked the model to expand upon some proofs, per expert feedback. We also manually facilitated a back-and-forth between this model and ChatGPT for verification, formatting and style. For some problems, we present the best of a few attempts according to human judgement. We are looking forward to more controlled evaluations in the next round! 1stproof.org #1stProof