
Aditi Mavalankar retweetledi

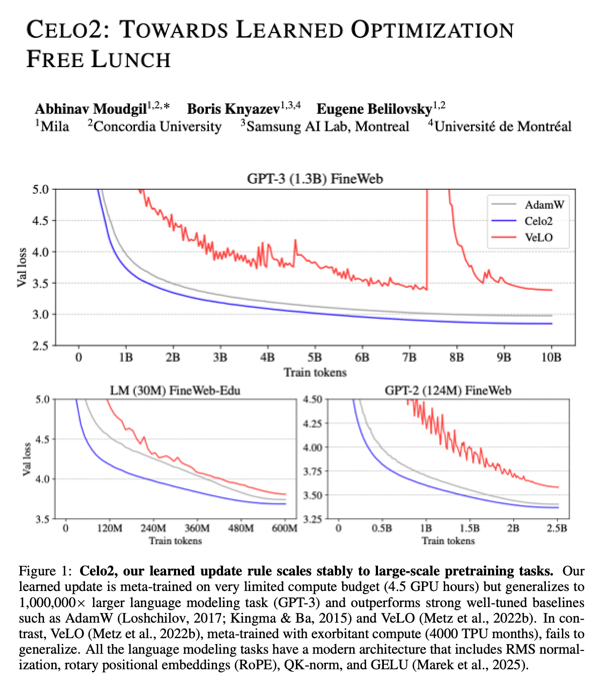
Introducing Celo2: Towards Learned Optimization Free Lunch
We show that learned optimizers can generalize to practical tasks like GPT-3 1.3B pretraining and several out-of-distribution vision/RL tasks from limited meta-training (~4.5 GPU hours)!
🧵
English







