Yann LeCun@ylecun
Thankfully, ML/AI research is largely free of the commercial publishing stranglehold.
Preprints are posted on ArXiv and OpenReview, short papers in top conferences like ICLR, NeurIPS, ICML, and a few others, and longer papers in JMLR and TMLR.
All of these venues are open access and free for both readers and authors.
ArXiv and OpenReview are supported by philanthropy (they need more), conferences by registration fees, and journals by nothing (it really costs essentially no money to run an online journal).
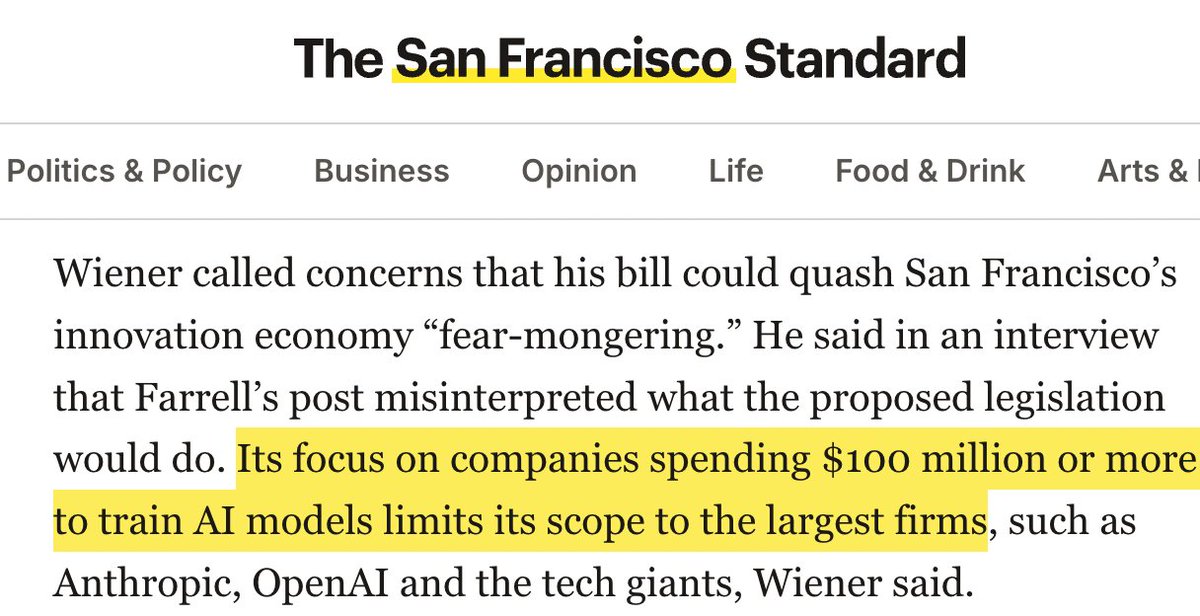
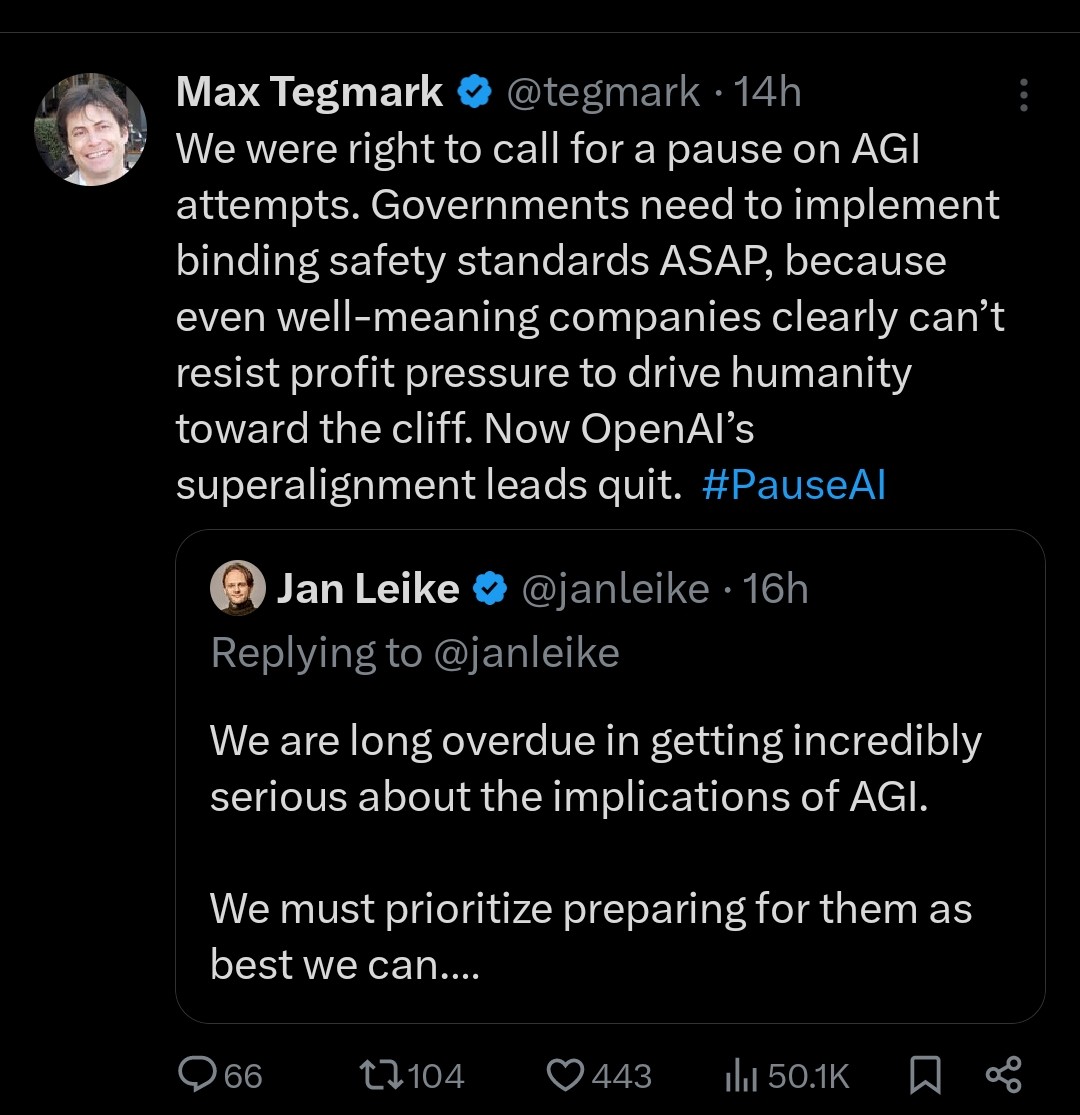
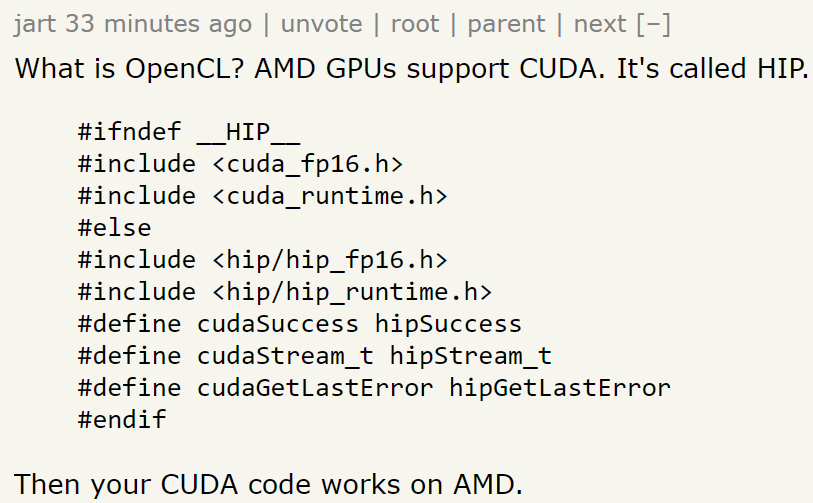
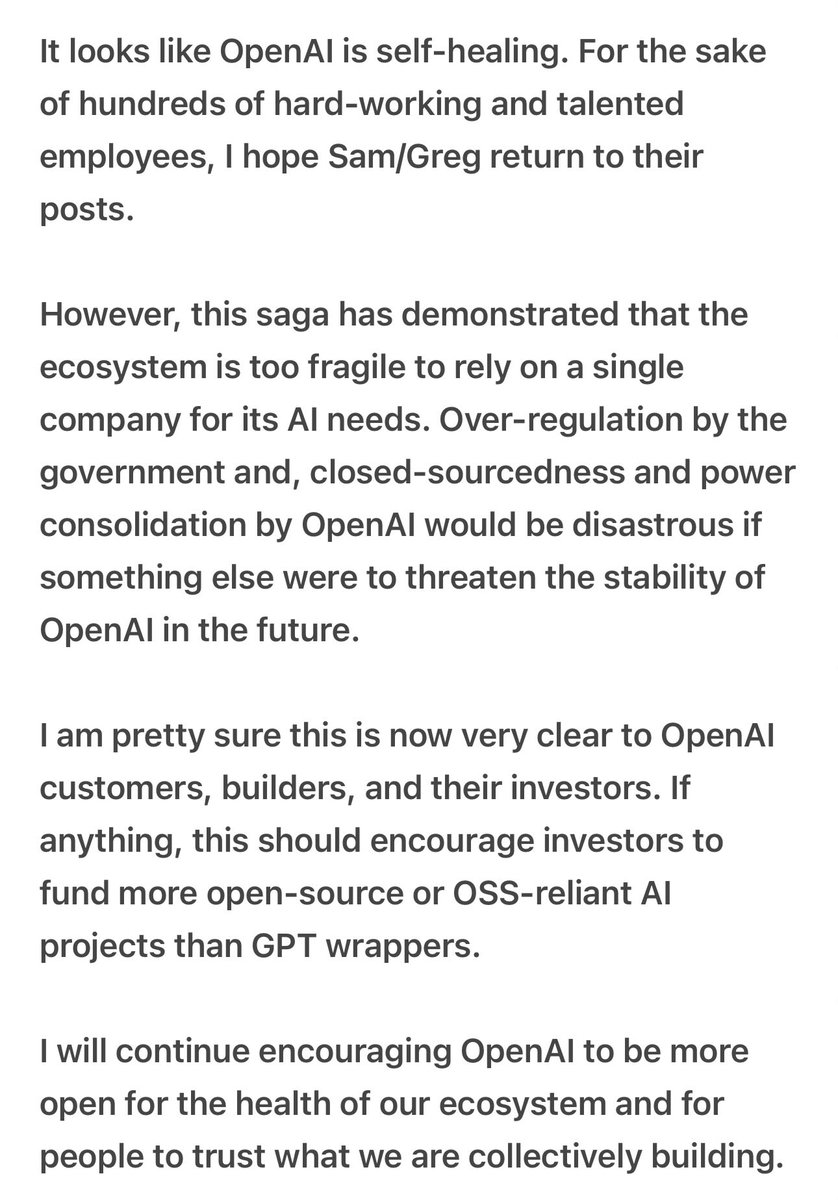
The exceptions are the few folks who still think that publishing in Nature Machine Intelligence, Machine Learning Journal, and other for-profit journals is a good idea (looking at you, DeepMind 😠).
Not surprisingly, many Nature MI papers are about hardware or applications of AI to the sciences, topics that are not well covered by "core" ML venues.