Sabitlenmiş Tweet

Created a video how to train Flux LoRAs using my convenience script utilizing ai-toolkit on @quickpodio
youtu.be/0I06JHyvuwQ

YouTube
English
Aivan Monceller
1K posts

@aivandroid
I share interesting things I find, what I’m learning, and projects I’m trying. Follow me if you like tech, creative stuff, and learning new things. INFJ-T

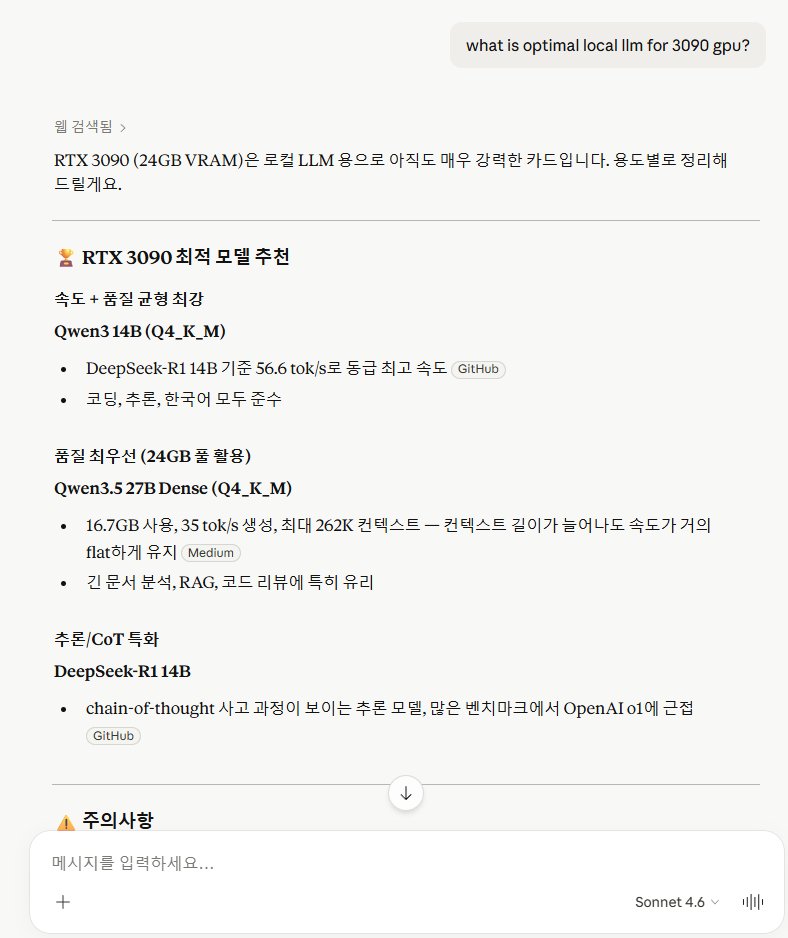


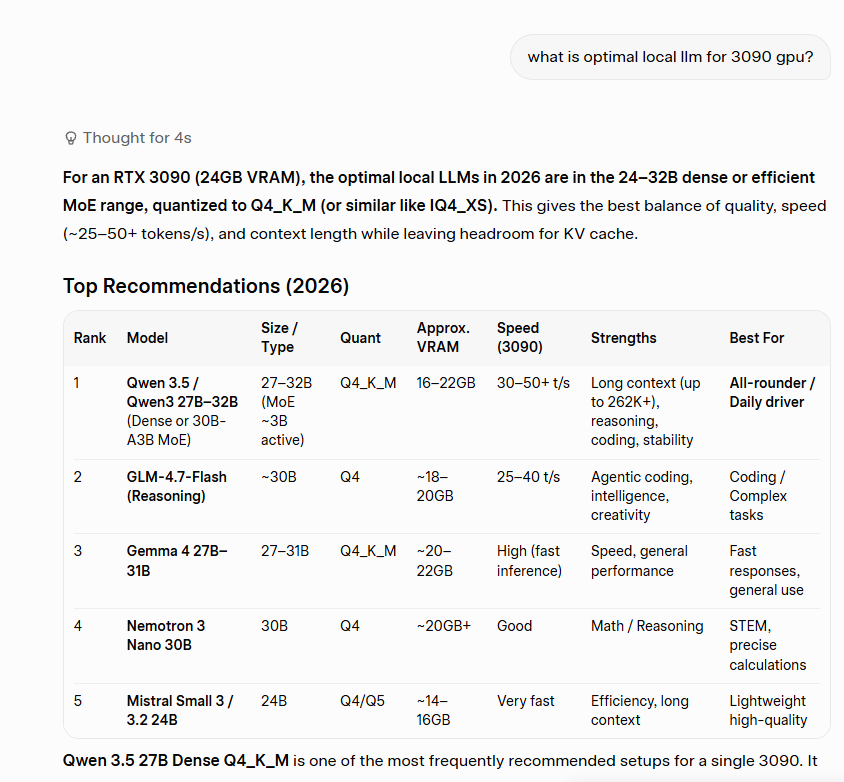






Terminal automation + e2e testing solved Now as simple as snapshot, click, type: – wterm renders terminal-in-html, every cell in the a11y tree – agent-browser automates pages via the a11y tree Here's opencode in one browser driving Claude Code in another