Sabitlenmiş Tweet

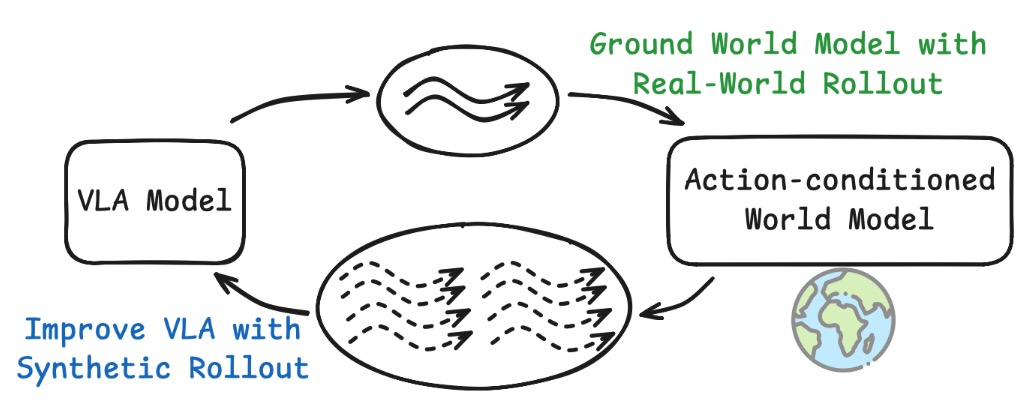
VLAs are great, but most lack long-term memory humans use for everyday tasks. This is a critical gap for solving complex, long-horizon problems.
Introducing MemER: Scaling Up Memory for Robot Control via Experience Retrieval.
A thread 🧵 (1/8)
English