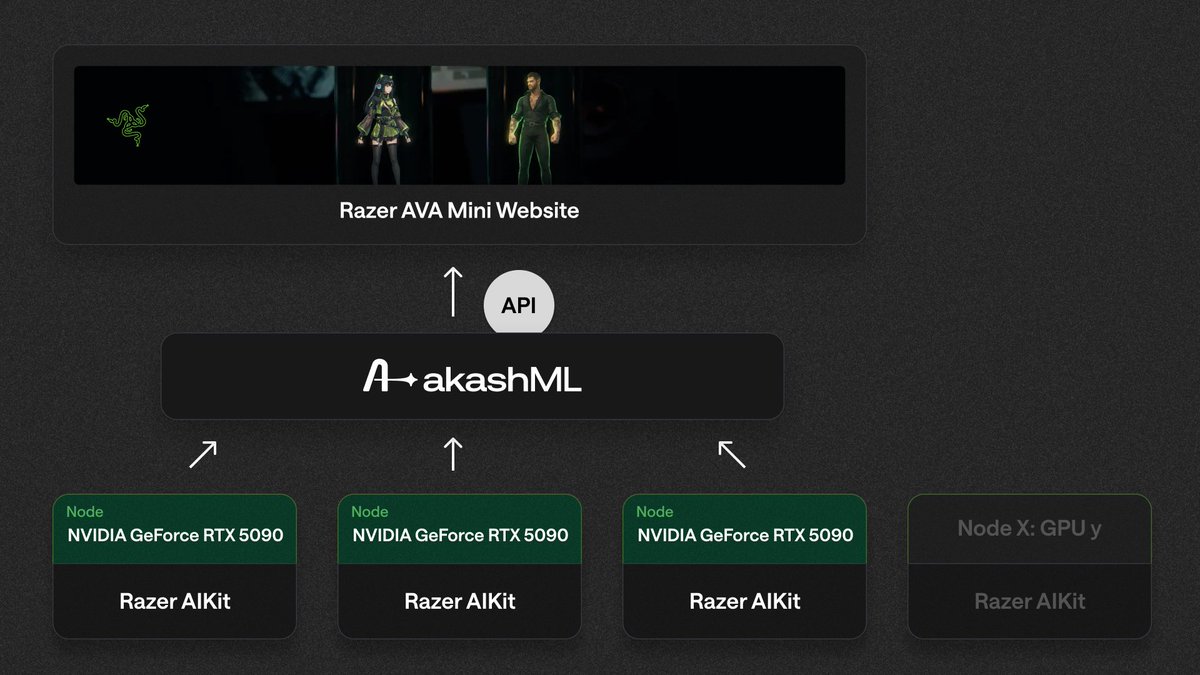
Sabitlenmiş Tweet

Never let token limits interrupt your workflow again.
Developers who keep getting cut off mid-session can now hot swap to AkashML.
Choose from DeepSeek V4 Flash, Kimi K2.6, or Qwen3.5 35B A3B and get back to building in minutes.
First 10 builders to make the switch and reply to this tweet with their experience get $100 in credits.
Get started → #macos-and-linux" target="_blank" rel="nofollow noopener">playground.akashml.com/docs/guides/cl…

English