
anasskabil
167 posts


هاري كين علي موعد مع كسر رقم ميسي التاريخي
73 هدفاً.. رقم ليونيل ميسي الإعجازي في 2011-12 الذي اعتقدنا جميعاً أنه سيبقى صامداً للأبد
يواجه اليوم التـ.ـهديـ.ـد الأكبر ..
هارى كين يقف على أعتاب التاريخ بـ 58 هدفاً،
المعادلة شبه مستحيلة ، لكنها ليست مستحيلة ..
المطلوب: 16 هدفاً لكىىىر الرقم ، متبقى مباراة واحدة فى الموسم ..
الخطة: 8 أهداف في كل شوط من المباراة الأخيرة.

العربية
Open weights, MIT license, model card with full eval breakdown:
huggingface.co/anasskabil/byt…
If you work on low-resource Arabic, dialectal NLP, or TTS — would love to hear what breaks.
English
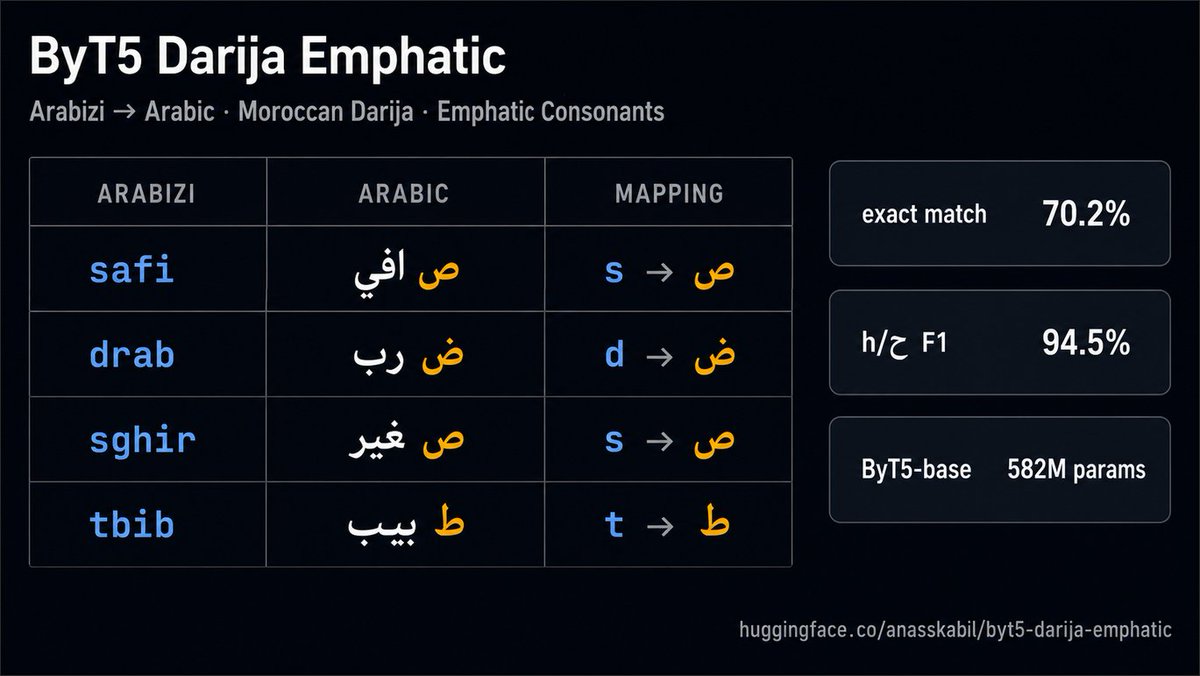
Spent the last month training a model to fix one annoying problem in Moroccan Darija TTS:
When you write "safi" in Latin letters, is the s the regular س or the emphatic ص?
Native speakers know. Models don't.
So I taught one.
English
Why byte-level matters here: Darija Arabizi has zero spelling standard. Same word, 5 spellings, all valid.
Subword tokenizers choke on that. Byte-level just sees the raw chars and learns the patterns.
English
ByT5-base, 582M params, byte-level tokenization.
Results on 4,727 test tokens:
h/ح: 94.5% F1
t/ط: 80.9% F1
s/ص: 81.3% F1
d/ض: 78.5% F1
Trained on data I built from scratch, filtered for the four emphatic pairs.
English
anasskabil retweetledi

New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
English
anasskabil retweetledi

Introducing Mirage, a unified virtual filesystem for AI agents!
6 weeks. 1.1M+ lines of code. We rewrote bash from the ground up so cat, grep, head, and pipes work across heterogeneous services. S3, Google Drive, Slack, Gmail, GitHub, Linear, Notion, Postgres, MongoDB, SSH, and more, all mounted side-by-side as one filesystem.
Bash that AI agents already know works on every format! cat, grep, head, and wc parse .parquet, .csv, .json, .h5, even .wav! One pipe can stitch S3, Drive, GitHub, Slack, and Linear together, same Unix semantics throughout.
Workspaces are versioned too. Snapshot, clone, and roll back the whole thing with one API call. A two-layer cache turns repeated reads into local lookups, so agent loops stay fast and cheap.
Drop a Workspace into FastAPI, Express, or a browser app. Wire it into OpenAI Agents SDK, Vercel AI SDK, LangChain, Mastra, or Pi. Run it alongside Claude Code and Codex.
Site: strukto.ai/mirage
GitHub: github.com/strukto-ai/mir…
#AIAgents #OpenSource #AgenticAI #Strukto #Filesystem #VFS


English

anasskabil retweetledi


anasskabil retweetledi

Introducing Realtime TTS-2, a new generation of voice model built for realtime conversation.
It is the first voice model that hears the conversation, takes natural-language voice direction, holds one voice identity across over 100 languages, and speaks like a person who is paying attention.
The result is voice AI that feels as good as it sounds.
Try it out: tinyurl.com/RealtimeAI
Learn More: tinyurl.com/TTS-2Blog
English
anasskabil retweetledi

How many times does this meme need to appear?

Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English
العربية

مستحيل ! 12 مليون نافذه طول السياق ... شي يستحيل التصديق ولكنه صار حقيقه بهذا النموذج الجديد !
اطلق @alex_whedon مشروعه الجديد @subquadratic الي يزعم عن تفوقه بـ OPUS 3.6 من ناحيه نافذه السياق Context window
المشكلة الي كانت تواجه الكثير من الناس انك اذا ضليت ساعات تتكلم مع الذكاء الاصطناعي راح يبلش ينسه و ذاكرته تقل كلما زادت المحادث او زاد كود مشروعك
اجت subq وحلت المشكلة وعملت 12 مليون نافذه سياق يعني تضل تتكلم معه اسبوع وماينسى
- 3 بالمية من التكاليف الي تدفعها لـ Opus
- 52 ضعف اسرع
- 1000 ضعف اقل استخادم للحوسبه
x.com/i/status/20516…
Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
العربية
Early access seems like a scammy marketing move waiting for the actual release next week like they claimed
Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English
anasskabil retweetledi

"YOUR CLAUDE CODE SESSION LIMIT HAS BEEN REACHED"
English
anasskabil retweetledi

27x faster Attention Residuals!!! 🚀
We implemented Block AttnRes as a pip-installable package.
!pip install flash-attn-res
No annoying kernel nonsense.
No compile/autograd plumbing.
Call it like a regular PyTorch op.
It just works.
Methodology:
🔹 fused triton kernels
🔹 batched attention over residual blocks
🔹 online-softmax merge
🔹 flash attention-style split-KV reduction
Thanks @LLMenjoyer and @cartesia for the support and guidance✌️

Kimi.ai@Kimi_Moonshot
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…
English
anasskabil retweetledi

🚀 Introducing FlashQLA: high-performance linear attention kernels built on TileLang.
⚡ 2–3× forward speedup. 2× backward speedup.
💻 Purpose-built for agentic AI on your personal devices.
💡Key insights:
1. Gate-driven automatic intra-card CP.
2. Hardware-friendly algebraic reformulation.
3. TileLang fused warp-specialized kernels.
FlashQLA boosts SM utilization via automatic intra-device CP. The gains are especially pronounced for TP setups, small models, and long-context workloads.
Instead of fusing the entire GDN flow into a single kernel, we split it into two kernels optimized for CP and backward efficiency. At large batch sizes this incurs extra memory I/O overhead vs. a fully fused approach, but it delivers better real-world performance on edge devices and long-context workloads.
The backward pass was the hardest part: we built a 16-stage warp-specialized pipeline under extremely tight on-chip memory constraints, ultimately achieving 2×+ kernel-level speedups.
We hope this is useful to the community!🫶🫶
Learn more:
📖 Blog: qwen.ai/blog?id=flashq…
💻 Code: github.com/QwenLM/FlashQLA

English
@yb_taha @mouad_builds Majrbtoch
Fl backend kan5dm b gemini tayjini a7san wa7d f context kbir w5a machi a7san 7aja fl ktba dlcode t9dr t analyzer bih project w generer lcode b claude wla gpt
English

@SNK_9999 @mouad_builds Fl back end ? T7eto flevel dyal sonet wela 7sen
English

فعليا ولا صعيب تواكب السرعة ديال التطور والمنافسة فـ Ai, كل ساعة كيخرج موديل جديد شفنا من قبل القضية لي دارت Anthropic و الثمن لي تبدل.
اراك ل DeepSeek الموديل الصيني جا اليوم و طلق الموديل (DeepSeek-V4) وفااابور
غانحاول نجرب Performance ديالو اليوم ان شاء الله
كيقولو ان الأداء ديال نسخة V4 Pro كتواجه وكتفوت أقوى الموديلات بحال GPT-5.4 و Claude Opus 4.6 فالبرمجة والرياضيات والمنطق
الموديل ايضا ولى كيدعم واحد الـ context كبير بزاف كيوصل حتى لـ 1M Context و بكفاءة عالية
و الـ API ديالو أرخص من المنافسين بـ 10 حتى لـ 50 مرة!
والاهم من هادشي كامل Open source ف HuggingFace
الشركات الأمريكية كتصرف المليارات باش تحتكر الموديلات و تربطك باشتراكات, و الصين كتحط ليك Model أقوى وناضي و فابور.
DeepSeek@deepseek_ai
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n
العربية
@yb_taha @mouad_builds jrbto f kilo code mziaan f agentic tasks , ta9riban a7san wahd an5dm bih fhad area
Fcode machi a7san 7aja 3l a9al f front end
Tayb9a opus n1 fhadxi
Kimi 3jbni agent swarm chft xi use cases la5r
HT
anasskabil retweetledi

Meet Kimi K2.6 Agent Swarm 👋
Highlights:
🔹 Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from 100 / 1,500 in K2.5).
🔹 Outputs are real files, not chat - one run delivers 100+ files, 100,000-word literature reviews, or 20,000-row datasets.
🔹Heterogeneous skills - search, analysis, coding, long-form writing, and visual generation all running in parallel
🔗Try it at: kimi.com/agent-swarm?ch…
English