angkyw retweetledi

Fine-tuning just got a whole lot easier.
Serverless SFT is now in public preview on W&B!
Managed infrastructure (powered by @CoreWeave) that auto-scales to your training workloads. No cluster setup. No idle GPU costs.
English
angkyw
115 posts













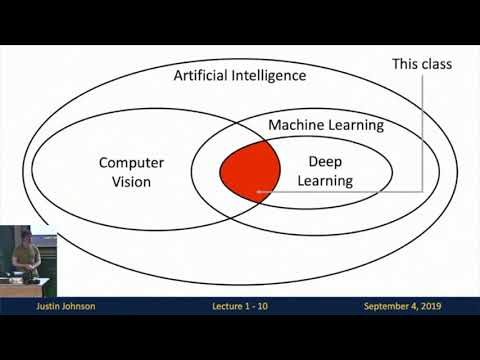
Here's a new lecture I made on learning embeddings with multidimensional scaling and TSNE for our ML course at Cornell Tech (with @volokuleshov). It covers the formulation and goes through some code for a deeper look Notebook: github.com/kuleshov/corne… PDF: drive.google.com/drive/folders/…