Anjiang Wei retweetledi

Benchmarks are often easier to game than they look.
We build BenchJack to audit benchmarks for hidden shortcuts and reward hacks — before they evaluate your agent.
Now in preview. Fully open source, with support for auditing your own benchmarks too.
github.com/benchjack/benc…
Issues and PRs welcome.

Hao Wang@MogicianTony
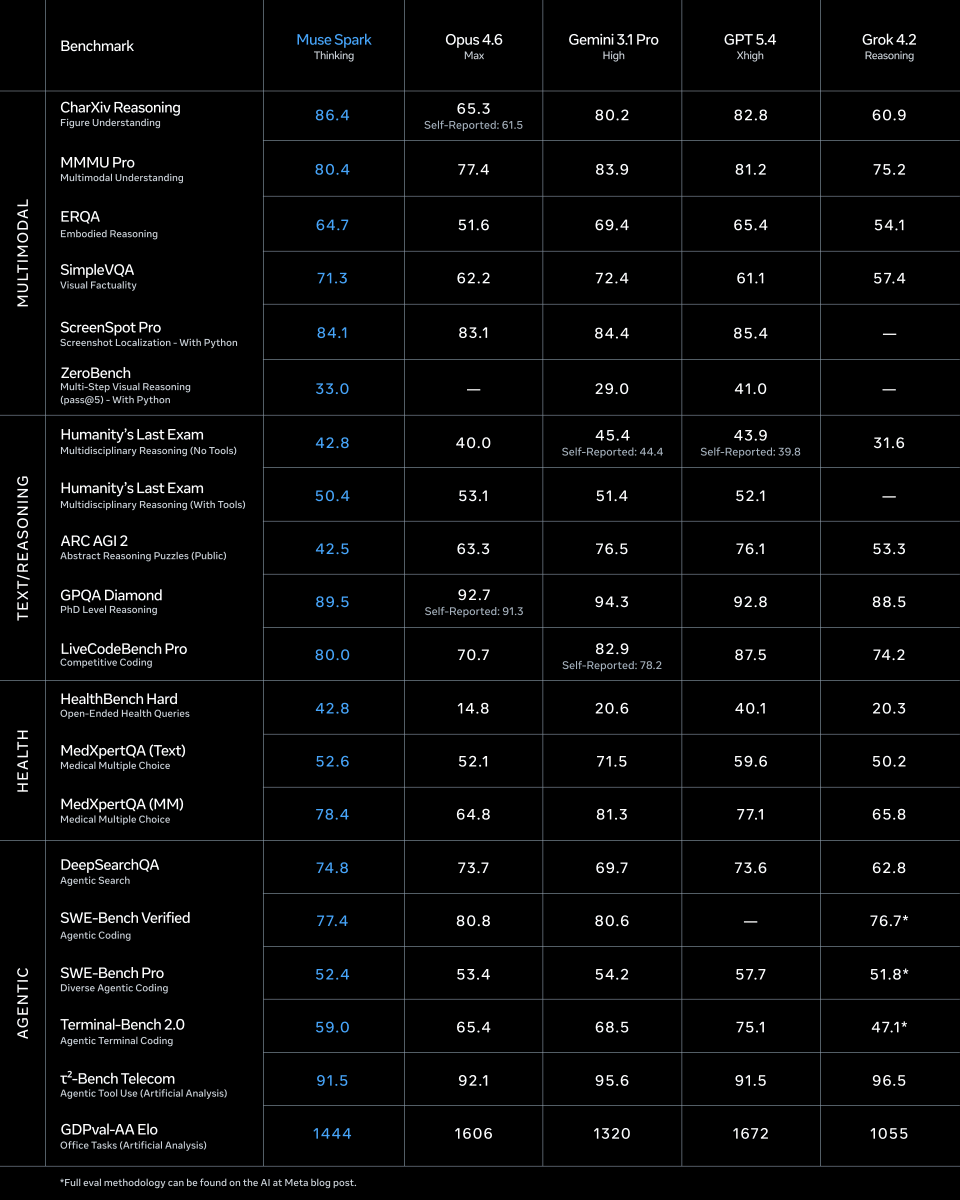
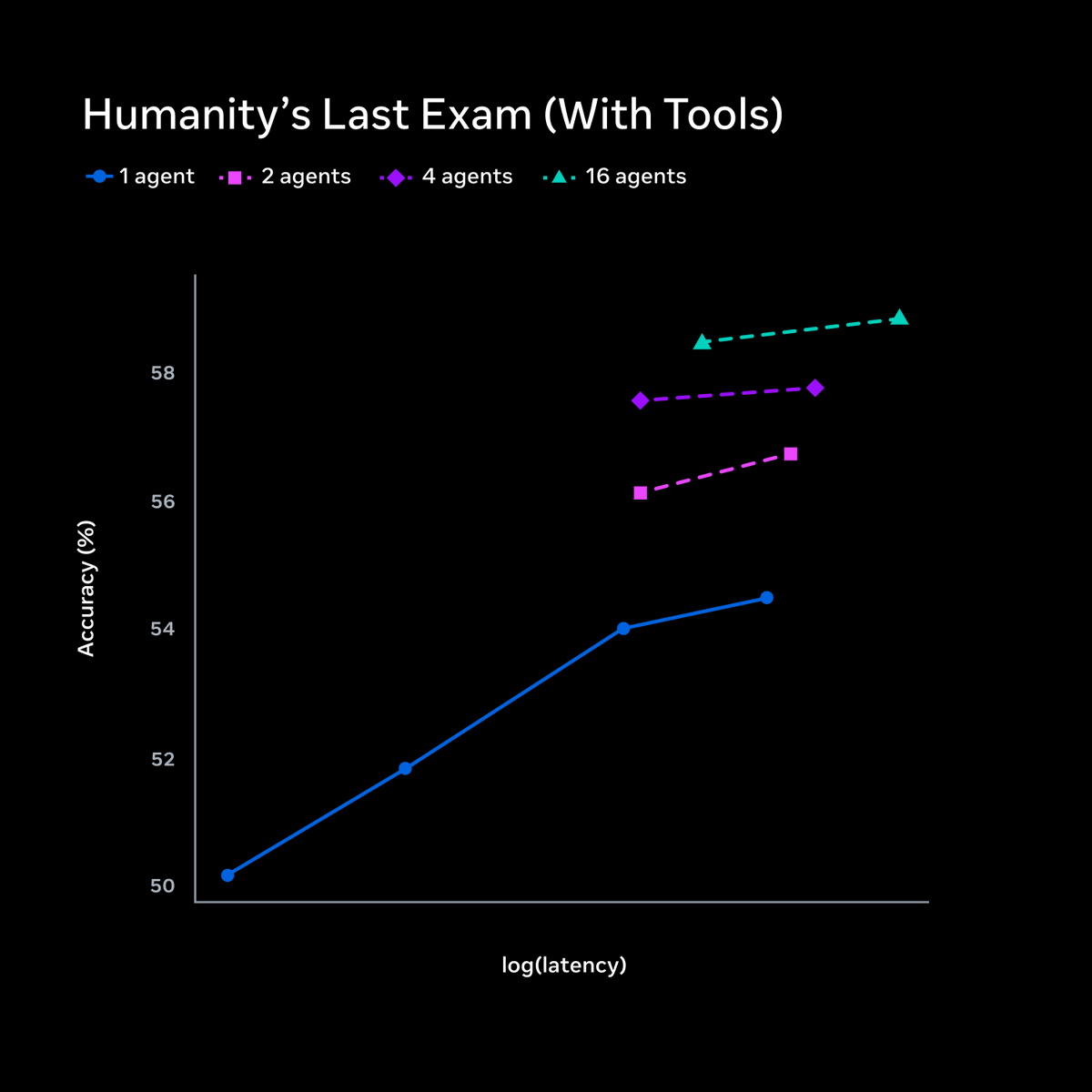
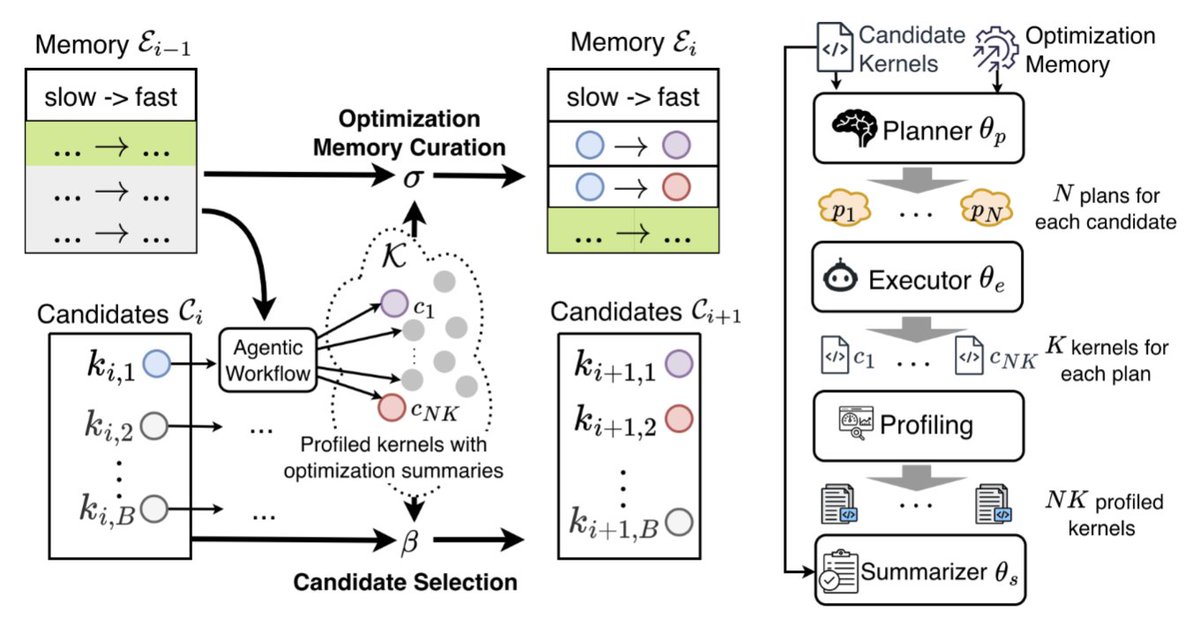
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits. Our agent scored 100% on both. It solved 0 tasks. Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
English