Sabitlenmiş Tweet

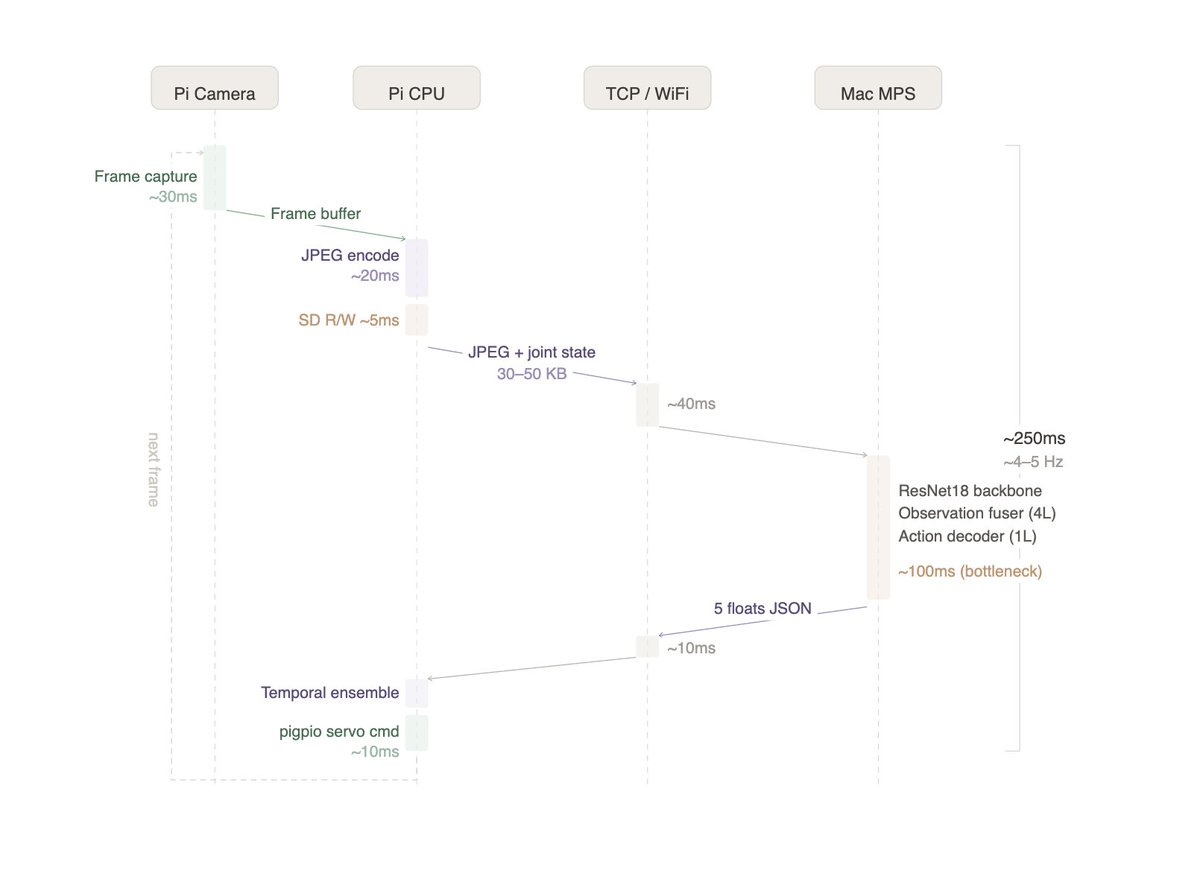
hacked around with Franka Panda on MuJoCo over the last couple of weeks, trying to get it to pick books off a table and drop them in a box. limited myself to SmolVLA and ACT since i was on my own 5070 Ti.
English
Akshit Pareek
219 posts
@apareek05
deep learning kernels and ML inference @TXinstruments




New blackboard lecture w @reinerpope How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do. 0:00:00 – Building a multiply-accumulate from logic gates 0:16:20 – Muxes and the cost of data movement 0:25:59 – How systolic arrays work 0:39:00 – Clock cycles and pipeline registers 0:51:40 – FPGAs vs ASICs 1:03:14 – Cache vs scratchpad 1:07:16 – Why CPU cores are much bigger than GPU cores 1:11:49 – Brains vs chips 1:15:22 – A GPU is just a bunch of tiny TPUs Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!