Sabitlenmiş Tweet
apaz
1.2K posts


apaz
@apaz_cli
https://t.co/EYtS07MR7w Making GPUs go brrr
Hiding in your wifi Katılım Temmuz 2019
584 Takip Edilen875 Takipçiler



I lost track of time again >.< I'm really sorry if you DMed me lately. I promise to go over my DMs!
---
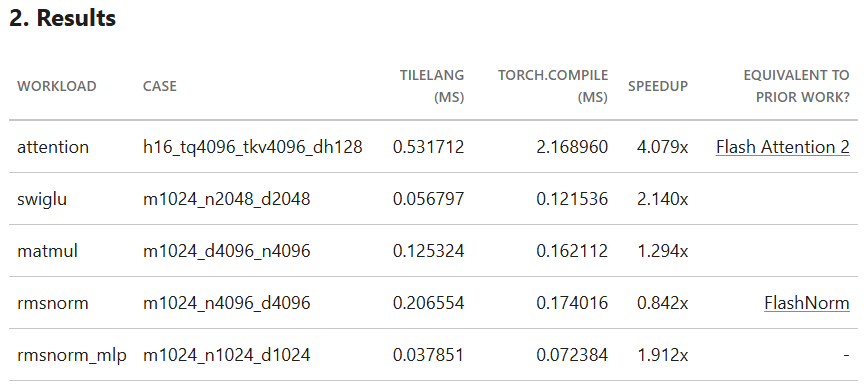
This sprint, I built a Lean4-to-TileLang Tensor Program Superoptimizer. With this, I now have a formal infrastructure where I (or my agents) can define neural network architectures in Lean4, and automatically get:
1. Optimized IO-aware accelerator kernels in TileLang. It can find FlashAttention2, FlashNorm, split-k matmul, and others automatically. I'm currently getting a ~1.8x geomean speedup on my benchmark set on A100s.
2. Optimizer choices and parametrization that enable hyperparameter transfer across width and depth (see my previous blog posts).
3. Hyperparameter scaling laws that tell us how to adjust hyperparameters as we scale batch size, training horizon, dataset size, and etc. (see quoted tweet).
4. Low-rank proxies for the optimizers to speed up hyperparameter tuning at small scales and have them transfer to the full-rank case (we have an upcoming paper on this, stay tuned!).
GIF
leloy!@leloykun
'Autoresearch', but for theoretical science? I formalized my blog posts on steepest descent convergence bounds and hyperparameter scaling laws in Lean using Codex. This started as an art project, but I ended up having similar (almost exactly the same) results as prior work while having much weaker assumptions so I think I may be onto something here 👀 This is also a glimpse of how theoretical science might look like in the near future. LLMs are good now at "reverse mathematics" where instead of asking what results we can get from a set of assumptions, we instead ask, "what's the minimal set of assumptions/axioms/postulates we need to reproduce (empirical) results?" Link to repo below vv
English

AI company names are self-negating prophecies. Wonderful demo by the team at Feeling Humans. Can't wait to try this out.
Thinking Machines@thinkymachines
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way. We share our approach, early results, and a quick look at our model in action. thinkingmachines.ai/blog/interacti…
English
@nrehiew_ Some time ago I made a very similar argument, although I didn't back it up with experiments. Good article, and I'm glad people are thinking about this. x.com/i/status/20060…
apaz@apaz_cli
I've been working a while on what's going to be a three or more part blog series. Here is part one. Part 1 makes an argument that training is training, pretraining data is important for RL, and suggests some experiments. Someone can leapfrog me on these experiments if they wish.
English

@CoreAutoAI They are good for backprop, terrible if you're doing zeroth-order optimization because they blow up the total size of your activations and thus limit your batch size while not really providing any stabilization benefit.
English

Are residual connections a hack, or provably optimal way to shape your loss landscape?
English
@_arohan_ Yea, they specifically talked about imagenet data pipelines, and those used to suck. Unless you precompute, but most don't.
I also get the curvature-dominated regime thing now, yeah. Better than being noise-dominated. I'd just never heard it called that
Then had other thoughts.
English

@apaz_cli Depends on what you are doing, data loader bottleneck is a problem on augmentation heavy pipelines of the past arxiv.org/pdf/1907.05550…
I was sending you a good starting point for what curvature dominated regime means, not about data echoing.
English
Big batches and stable optimization. The final boss is curvature, the level after that is generalization.
English
Somehow I hadn't read that one yet. But I just did, and it makes some sense. The premise of the paper seems flawed to me though, I don't think dataloaders are a bottleneck (depending on what you're doing, at least in language with "normal" optimizers). With massive batches with a dataloader doing image augmentations or something maybe it's different.
If anything what I'm getting from the paper is a listing out of the equations you have to rearrange to derive an optimal lr/bs schedule. Predicated on the assumption that your training is stable in those setups. Which... kinda sounds like what you were talking about. But I felt like this was a solved problem, just use the existing lr/bs schedules that work.
Many training instabilities are along the lines of "Ah, our activations or gradients are too big in this part of the model, let's figure out why and squash that down." I've found more success hunting sifting through batches and activations and grads than trying to come up with a more stable optimizer. The problem is always in the model somewhere.
Then again, AdamW is somehow magical and is able to paper over a lot of problems which would make Muon unstable. It's only now that we require stability patches like qk-clip, things like mHC, etc. These are architecture fixes. So I think stability is a skill issue and fundamentally an architecture problem. Although a more stable Muon that is more forgiving of skill issues would be nice.
The biggest wins in generalization, I feel, are mostly in things like skillful data mixing and scheduling, making sure your data is formatted into the right distribution. That sort of stuff. Data experiments have a big impact, and are some of the most impactful work. This is something that I'm hyped about with autoresearch, actually. Teach it to use data pipelines and train small models to come up with better and better data mixes, and evaluate them. It's a good research direction.
I it is also true that models trained with Muon feel different from models trained with Adam. It feels... orthogonalized. If that makes sense. It probably doesn't. But I feel it somehow. Playing with models I've trained, they feel different. It feels like there's something here, not that it's possible to measure.
English
@apaz_cli proceedings.neurips.cc/paper_files/pa…
Mainly looking at theory. Usually convergence improves by increasing batch size until it no longer is the biggest term in the convergence bound.

English
@hello_gensi You're wrong, in a manner that makes me think you're probably a bot, so I'm blocking you.
English

@vvenki22 Cool work. Different problem, but related and potentially useful tricks.
That's a thing with bandit problems, I've noticed. Everything is a bag of tricks, and it's always possible to come up with a new reward function and invent new approximations. I'm gonna go crazy.
English

@apaz_cli Spot on. Bandits are very relevant in sample-efficient retrieve-reason setups and also TTS setups. We are working in this line for a while now. Here is one paper where we scale retrieval using a simple disposable bandit like, with linear surrogate - dl.acm.org/doi/10.1145/37…
English
@alexUnder_sky Yeah, when you try to reason past two or three steps into the future the gains fall off really fast, and the uncertainty accumulates exponentially. Like any numerical analysis of this sort. There are tradeoffs.
I wrote a C impl and was able to scale to like 512 ideas compared.
English

@StefanGliga With that said I learned about this field's existence literally two days ago.
English
@StefanGliga I believe you're witnessing me getting nerdsniped by gaussian processes. Or rather, I've come up with a new (I think novel?) gaussian process for use in the async-batching case.
English
@teortaxesTex >FSDP128
Kinda crazy. Then again deepseek did something kinda similar with their werid ZeRO grad bucketing so maybe not.
I was not aware the Atlas had such a large densely connected scaleup network. I haven't looked into it in a while.
English

continued training of DeepSeekV4 vs Ascend Atlas 800T@TorchTitan
> Can ordinary developers write heavy fusion kernels like Sparse Flash MLA?
> The community has released a tool called CAN Bot (part of CANN Skills)…
man, this isn't fair


China Research Collective@CRC_8341
DeepSeekV4 on Ascend: Continued Training Optimization with TorchTitan Full details here: open.substack.com/pub/chinaresea…
English

i remember proposing automatic optimization of speech prosody, voice, timbre etc to maximize user gooning
didn't expect us to get it so soon?
AmirMušić@AmirMushich
Meta Tribe2 is a model that predicts your brain's response on videos so now you can edit videos with more clarity of how to compose them, what works and what doesn't and we built a free tool for you based on this model yes, totally free see details below
English
I've been committing war crimes with this the likes of which you couldn't believe.
DeepSeek@deepseek_ai
The DeepSeek-V4-Pro discount has been extended until May 31, 2026, 15:59 UTC!
English

something went wrong when the industry converged on randomly initialized special token delimiters that occupy a totally fucked up superposition of embedding space (in a way that somehow mangles the in-context learning the base model could already do over plaintext sequences)
English
@charliermarsh
I beg
I'll do anything
Change anything
Please
please
My code is so good
Surely you want to merge my code
plsplsplsplsplspls
plspls
Please?
Let me fix uv's wheel download implementation
It breaks if there's a slight hiccup in the connection
But that's okay
It's not like connections will ever hiccup, right?
That's impossible. Surely that won't happen. I mean, who has spotty internet? Basically nobody.
I beg
Please let me fix your code
I promise my code is SOLID or whatever bullshit people care about nowadays
I flush the buffers like I flush out my eyelids
please ive been waiting so long please ill make it worth your while pleasepleaseplease
Surely you will not regret merging my code
See, it's smiling at you?
It wants you to merge it.
Please please
please
my commits are so clean
look at my commits
im not like those other pr authors
Most assuredly you will not regret it.
My code will make you proud
It will restore honor to your clan
Forge new horizons in python wheel downloading
It's good shit
You know it's good shit
You want it so bad don't you
You do.
merge my code its all i ever wanted
please notice me
i will name my firstborn after u
please
help
github.com/astral-sh/uv/p…

English