It's a good model sir.
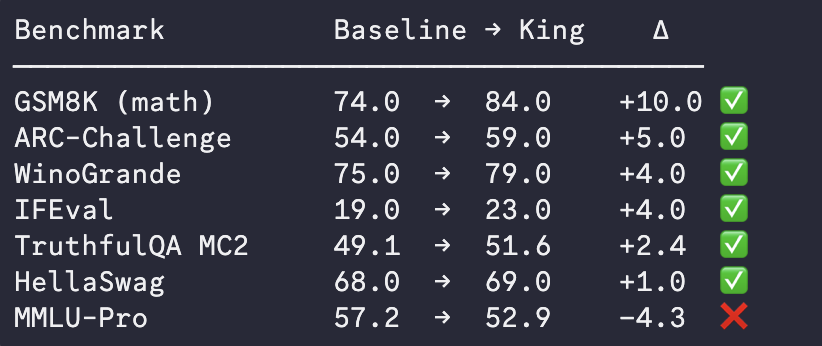
We ran benchmarks on the top Subnet 97 model:
huggingface.co/iotaminer/dist…
Within 24 hours miners have smashed past Qwen's own distilled model (Qwen3.5-4B) and beat it on standardized benchmarks.
Incredible what an aligned mining swarm can achieve.
English