
Archie
33 posts

Archie
@archiesienna
Caffeine, Claude Code & ChatGPT. PhD in Promptcasting @Hogwarts. Currently stalking markets with MLscope. Part time Larper @X.
wandering Katılım Aralık 2025
16 Takip Edilen0 Takipçiler


pi is crazy fast and you would not believe me until you try it yourself, i've stopped praising opencode, claude code and codex after a single day of using pi.
it just works, as intended. no agent harness can even touch this beast. used it for like 3 hours and now i am addicted.
English
@iyoushetwt Only if they used it to build Siri something like a device operating agent....
English

@kimmonismus I just know the model itself would me impressive, but Google's shitty infrastructure would make it unusable anywhere else other that Gemini Chat....
English
@forloopcodes Okay, so we step 1 of token maxxing is messy aesthetics setup....
English

@forloopcodes @interaction Congratulations, happy for you..... Reffer me when you get promoted.
By that time I'd have completed PhD in Prompt casting from Hogwarts.
English
got hired at @interaction, you can email me at forloop@poke.com
English
@forloopcodes Woke up and decided to dump anxiety on us ;-; again......
English
@forloopcodes Will this work with minimax coding plan as well? They operate on request based usage as well.
English
@archiesienna idk it just works when im asleep/in the bed thinking
English
@kimmonismus ATP just using US models as orchestration and Chinese models as subagents......
The budget is barely anything to bother about, but ofc they need more hand holding and details as compared to GPT and Claude.
English

DeepSeek just made its 75% price cut on V4-Pro permanent. Xiaomi's MiMo slashed V2.5 pricing by up to 99%, effective today. Most coverage frames this as a price war. The more interesting part is the engineering that makes these numbers sustainable.
DeepSeek's V4 paper describes a *hybrid attention architecture* that attacks the core bottleneck of long-context inference: the KV cache. Traditional transformers store key-value pairs for every token in the context. At 1 million tokens, this cache alone can fill an entire GPU's memory. V4 introduces two interleaved attention types.
Compressed Sparse Attention (CSA) compresses every 4 tokens into a single KV entry, then selects only the top-k most relevant compressed blocks per query. Heavily Compressed Attention (HCA) goes further, compressing 128 tokens into one entry and running dense attention over the result. The compressed sequence is short enough that dense attention stays cheap.
V4-Pro's KV cache at 1M tokens is 10% (!!) of V3.2's. Single-token inference FLOPs drop to 27% (!!). The model has 1.6 trillion total parameters but only activates 49 billion per token through Mixture-of-Experts routing, the knowledge capacity of a massive model at the compute cost of one thirty times smaller.
MiMo's approach is different but lands in the same place. Xiaomi's team implemented Sliding Window Attention via SGLang HiCache, reducing KV cache data transfer across GPU memory, CPU memory, and SSD to roughly 1/7 (!!) of previous volume. Cacheable tokens expanded by 5x (!!). Combined with expert parallelism optimization and input length bucketing, per-token serving cost dropped enough to make permanent pricing at these levels viable.
V4-Pro now sits at $0.87 per million output tokens. MiMo V2.5-Pro at roughly $3/M output, with Flash variants far below that. A year ago, sub-dollar output pricing meant you were using a small distilled model with real capability tradeoffs. These are frontier-class reasoners with million-token context windows.
Both companies can commit to permanent cuts because the reductions come from the architecture itself. When your attention mechanism physically processes fewer FLOPs per token and your cache occupies a fraction of the memory, the cost to serve is structurally lower. The price follows the cost curve.



English
Archie retweetledi

Vibecoding is when you let LLMs generate code and you accept it as long as the end result appears to be working. You don't even review the code, you don't care.
When you rigorously ensure that generated code is up to a standard, it's not vibecoding anymore. It's programming.
English
@forloopcodes It feels more like an api wrapper, but the best one indeed.
Lately I've replaced it with notebooklm and couldn't be happier. Daily driver for PPL who need to stay updated on their work, also it filters out fake web/ai slop that Gemini couldn't.
PS: thanks for making Context plus
English
@ProtonMail For accs u don't care Gmail....
For accs u do care Pmail....
Simple isn't it
English

DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
English
@iyoushetwt As long as we are staying alone, if we have loved ones with us we surely will go the other way around........
In solo arc, that's peak setup right there.
English

@dhruvtwt_ Is there any way I can use my ChatGPT Plus subscription to use it? Like not in Codex but in Open Claude
English

IT WORKED.
I'm in love with free open claude code
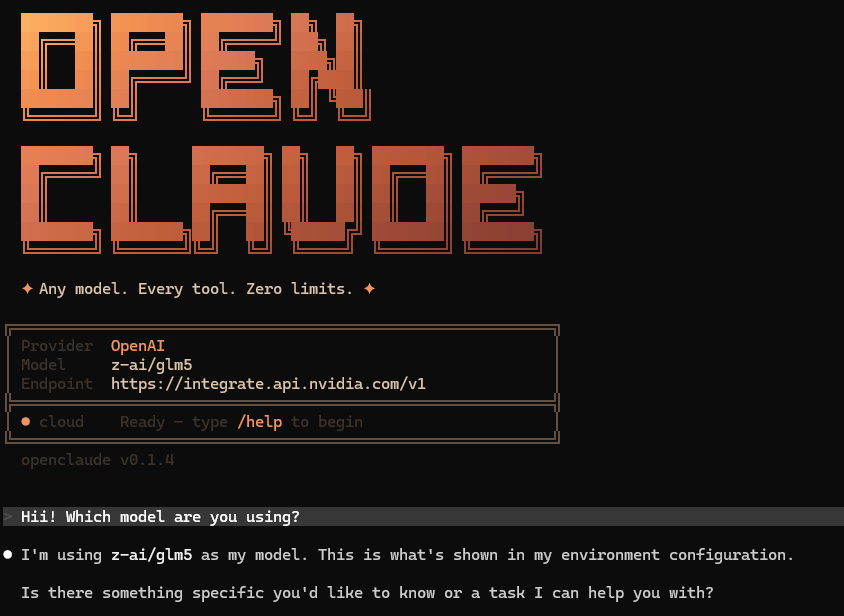
Dhruv@dhruvtwt_
It’s been 24 hours… and someone already dropped OpenClaude. Built on the Claude Code source snapshot that went public via an npm source map exposure on March 31, 2026. And the best part? You can now use it with 200+ models via OpenAI compatible APIs.
English

"Not having a coding experience is becoming an advantage."
Replit CEO Amjad Masad:
"You don't need any development experience. You need grit. You need to be a fast learner."
"If you're a good gamer, if you can jump in a game and figure it out really quickly, you're really good at this."
"Coders get lost in the details."
"Product people, people who are focused on solving a problem, on making money, they're going to be focused on marketing, they're going to be focused on user interface, they're going to be focused on all the right things."
"I think this year it's gonna flip, and I think not having a coding background is gonna be more advantageous for the entrepreneur."
@amasad with @jackhneel
English
@sfwhiteknights "5-hour limit reached - resets at 2am"......
This thing still scares me sm
English
@iyoushetwt I still have it, but it's only boon agentic abilities got nerfed af. They just set it high during promo, now the agent is fragile. It's so lazy now, trying to save compute. Back to old browser.
English
