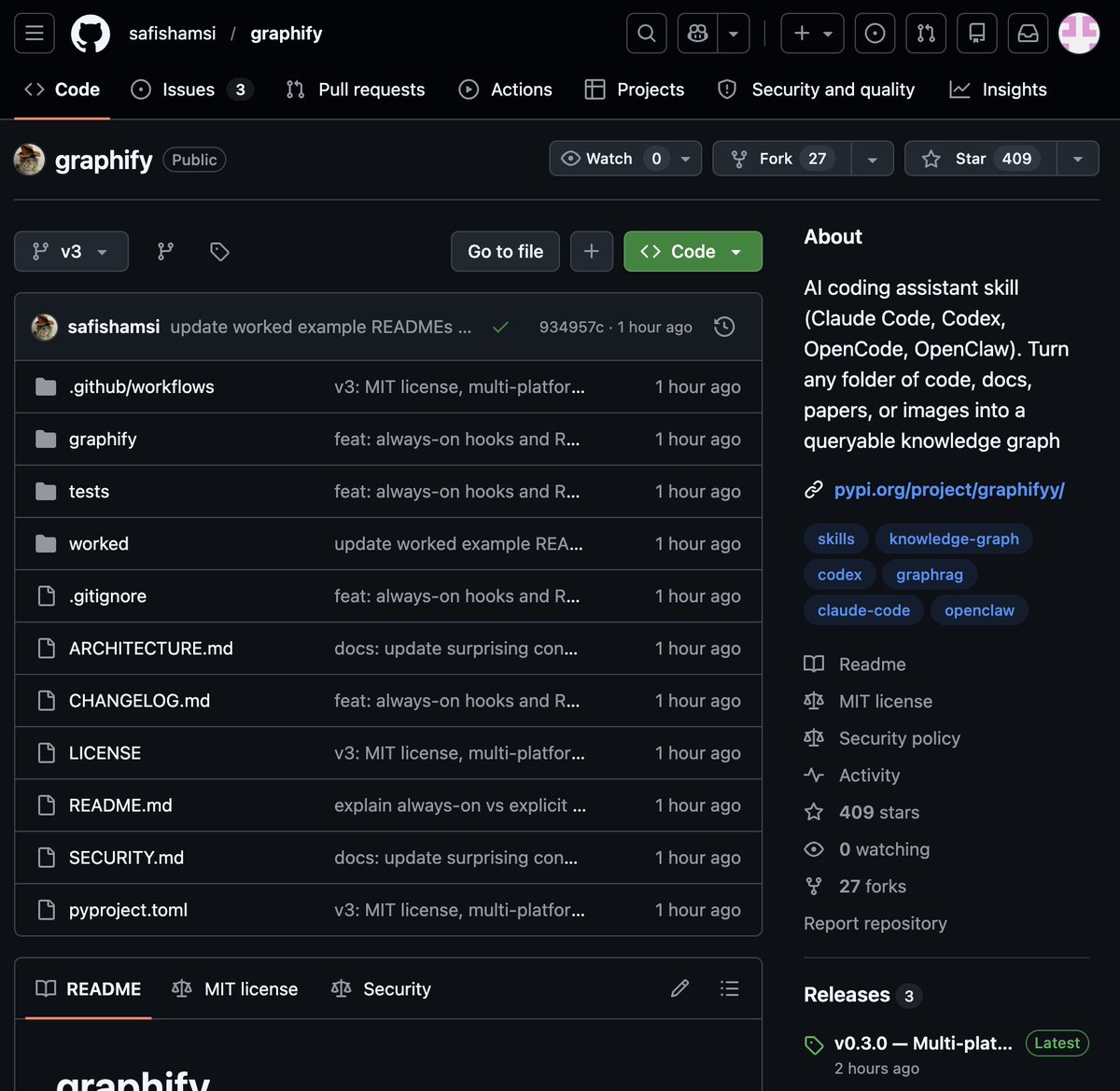
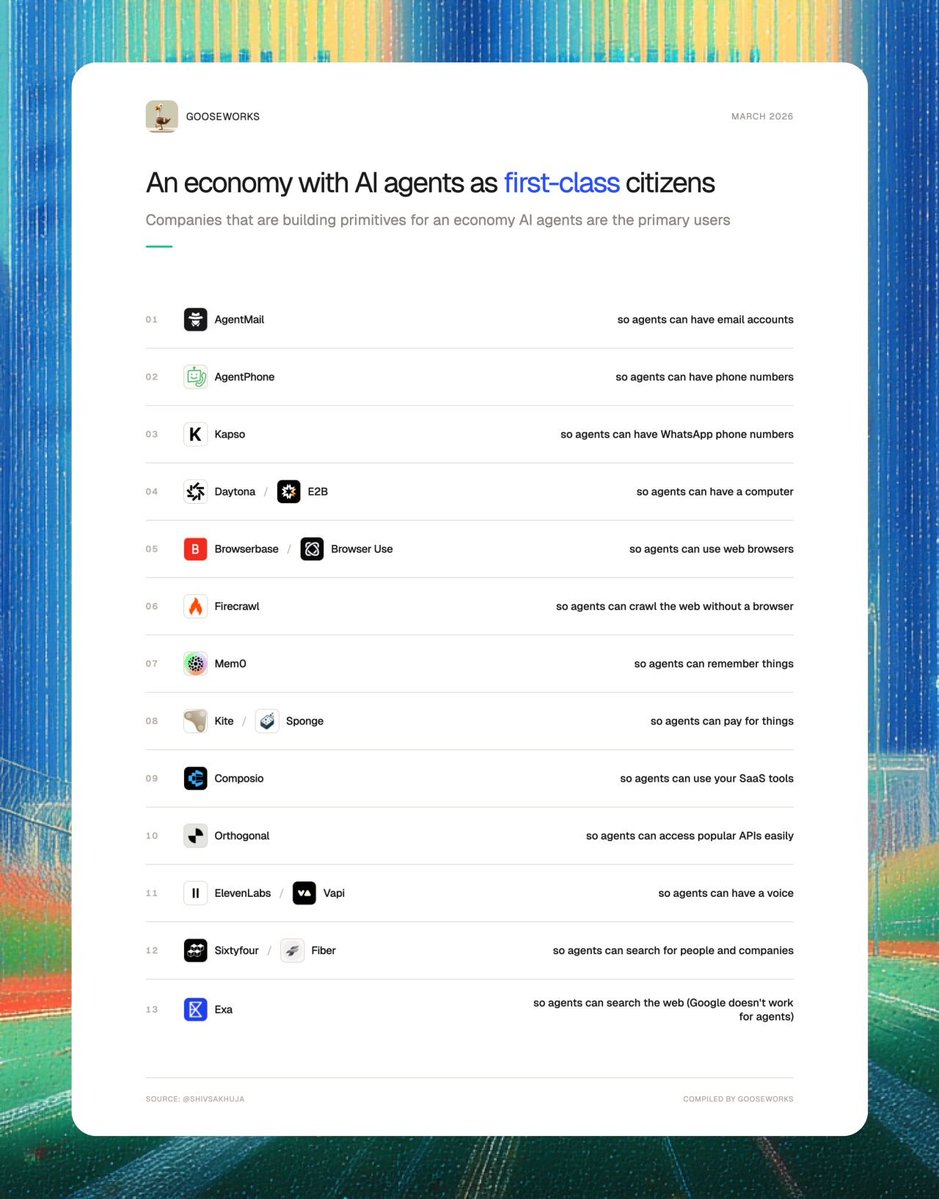
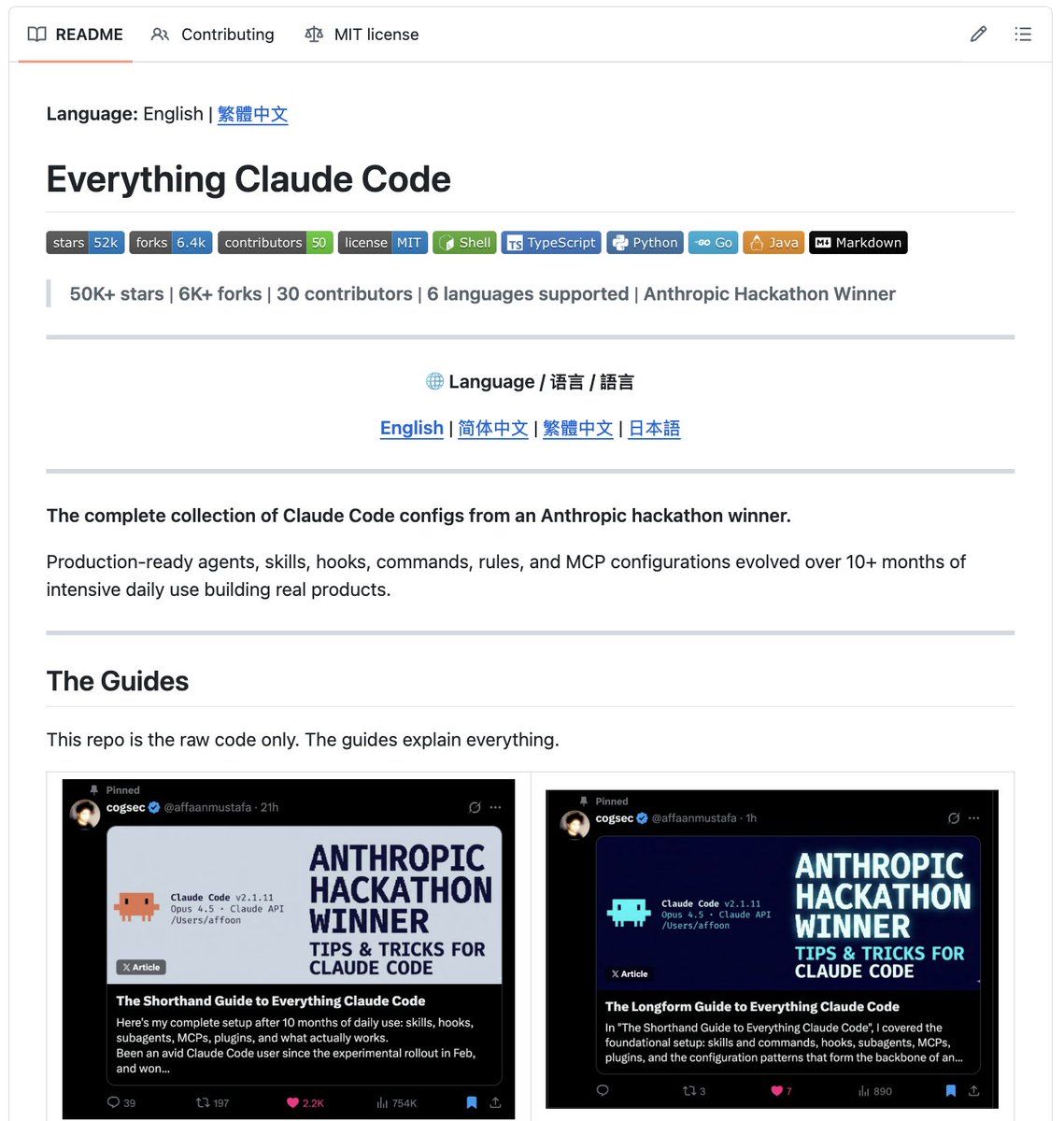
Sabitlenmiş Tweet

AI that forgets is brittle. AI with memory can reason.
At #PyConIndia2025, I’ll present "Memory is the Agent: Architecting Stateful Reasoning", explaining why memory must be the backbone of intelligent systems.
#Python #AI #Intelligent #memory #pythonprogramming @pyconindia
PyCon India@pyconindia
Insights, inspiration, and Python power! 🐍 Be there for Archit Singh’s session on “Memory is the Agent: Architecting Stateful Reasoning” at #PyConIndia2025 Tickets still open: in.pycon.org/2025/tickets/ Conference schedule: in.pycon.org/2025/program/s… #TechTalk #conference #Python
English