@lucataco93 Nice!
FYI peak memory during training depends on batch size and # tokens in the dataset.
You should give SiLLM a try for training with LoRA/DPO: github.com/armbues/SiLLM
English
Armin Buescher
1.3K posts
@armbues
Security Researcher. Disclaimer: my tweets don't reflect the views of my current or past employers!

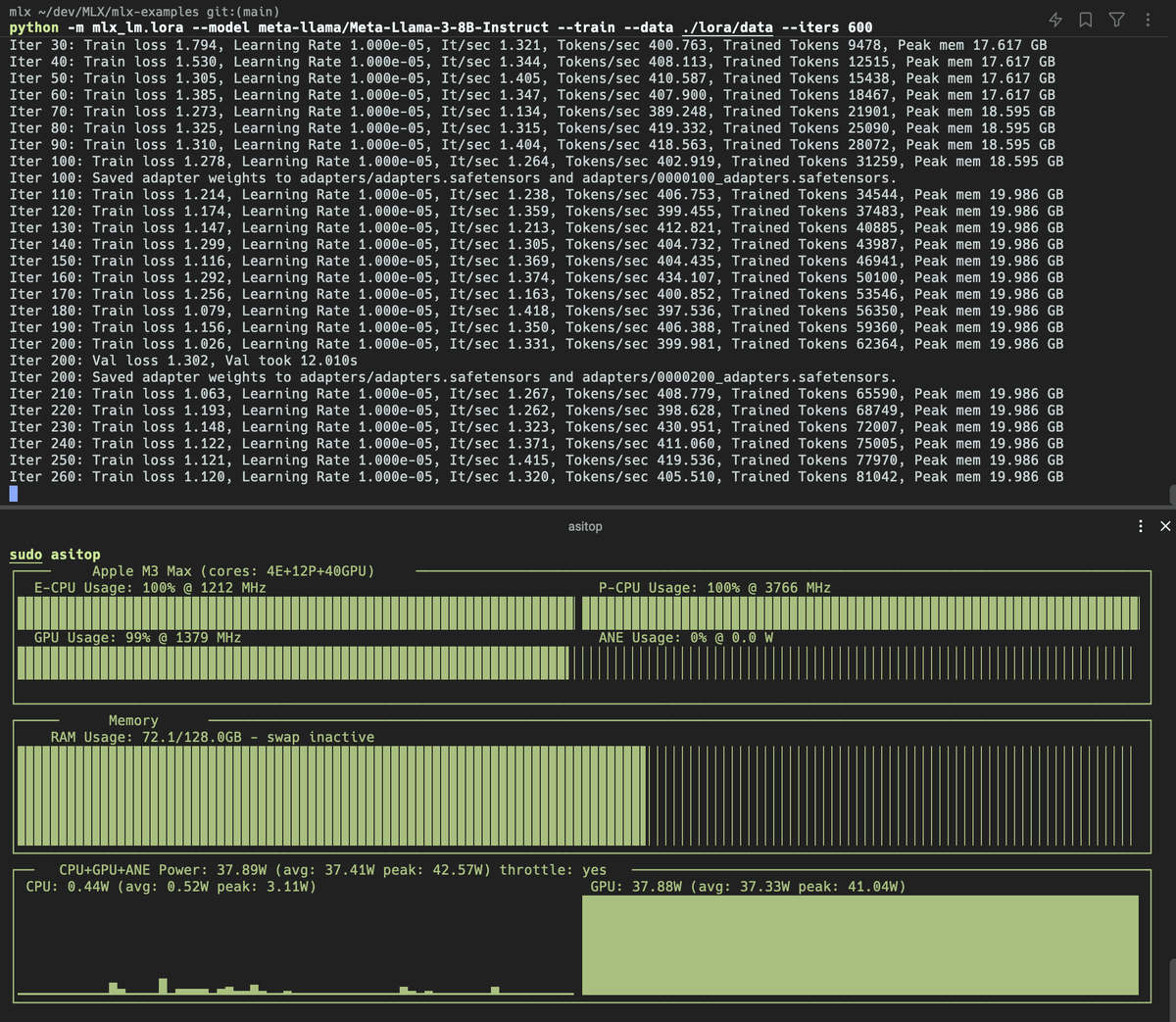
LoRA fine-tuning Llama 3 8B in 16-bit on an M2 Ultra with MLX. Some stats: - Batch size 4, 16 LoRA layers - 530 tokens per second - Avg power 94 W - Peak mem 20GB





I'm excited to share a new open-source project: the Silicon LLM Training & Inference Toolkit, short SiLLM. Check out the project on Github here: github.com/armbues/SiLLM