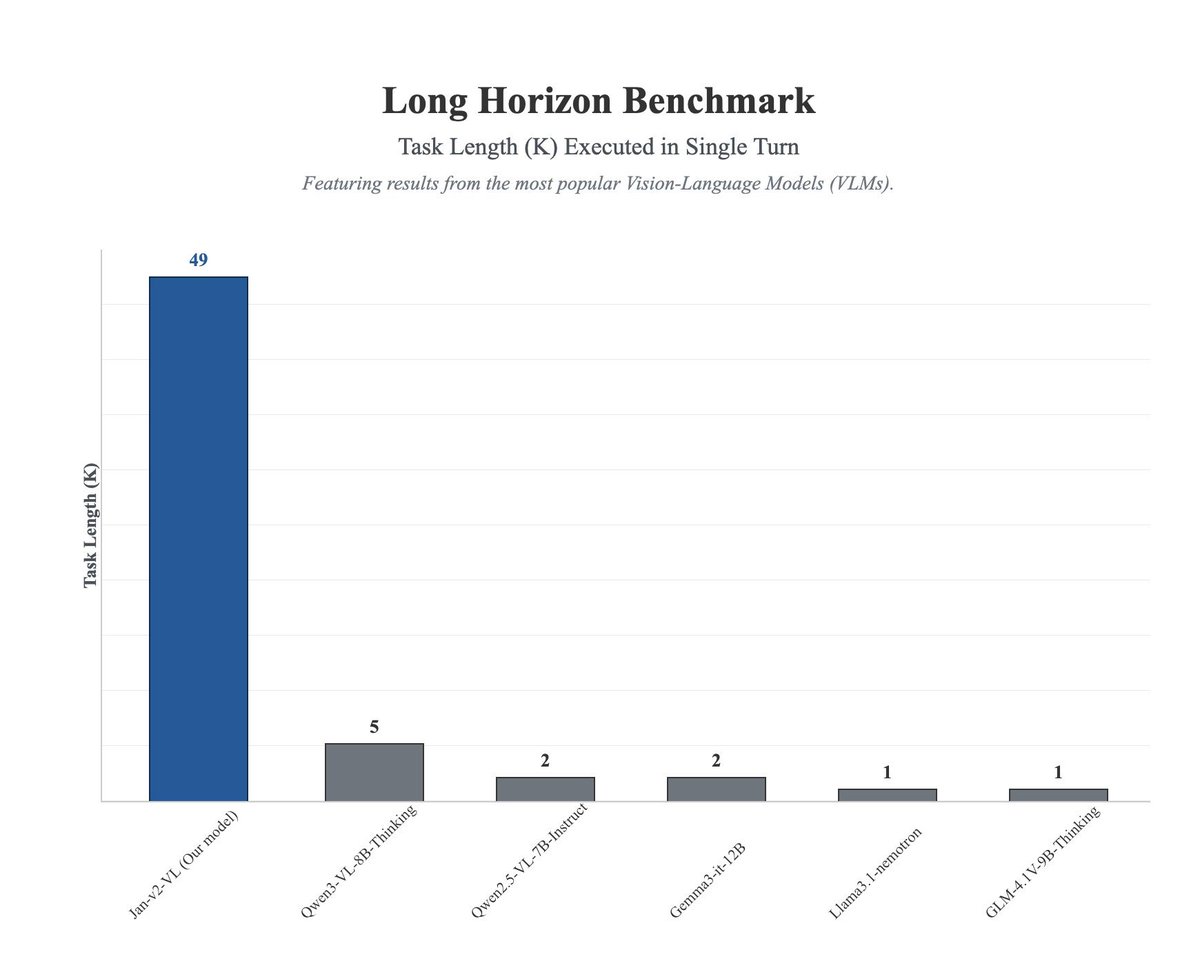
Shashwat Goel@ShashwatGoel7
New Blogpost: How to game the METR plot🚨
In 2025, a single graph changed AGI timelines, investments, research priorities, model quality assessments and much more.
But if you squint harder, only 14 prompts shaped AI discourse over this year. Thats all the data in the 1-4 hour horizon length regime that matters. 🕵️
What's more? A majority of these are about Cybersecurity capture the flag contests, and training a Machine Learning model.
> Post-train your model on CTF and ML codebases
> profit 📈! its METR horizon length will increase.
Exactly what OpenAI has been targeting in its Codex model releases... and is Anthropic underperforming in the 2-4hr range because it mostly consists of cybersecurity, which is dual-use for safety?
To be clear, I think its an excellent idea to track horizon lengths instead of benchmark accuracy. But under the current modelling assumption of success probability being a logistic function of task length, SWAA+HCAST accuracy improvements alone might explain the exponential progress in horizon length 🔎
In the blog, I show detailed evidence for why we need to stop overindexing on the METR plot. Share it with anyone you see making decisions based on where the latest model lands on the METR plot.
shash42.substack.com/p/how-to-game-…