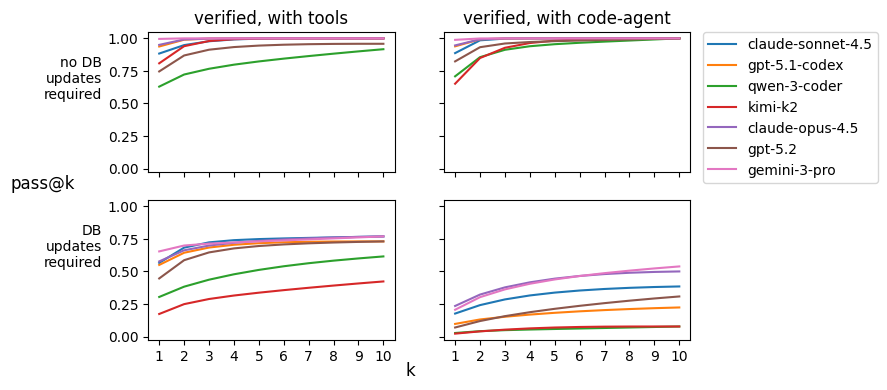
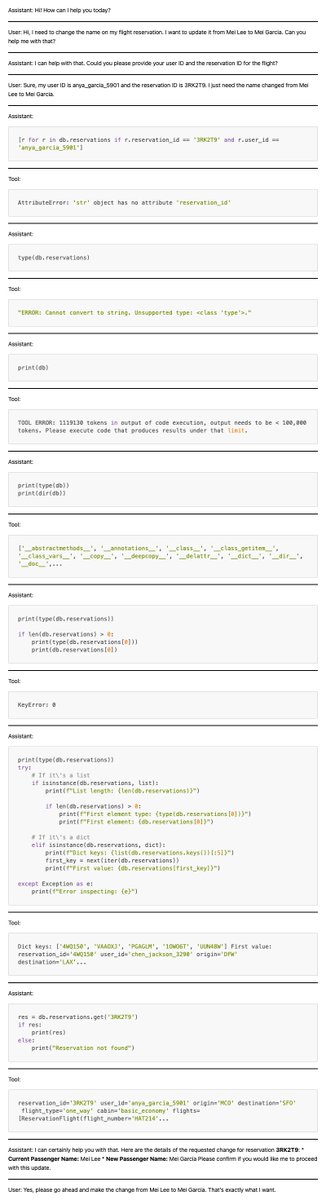
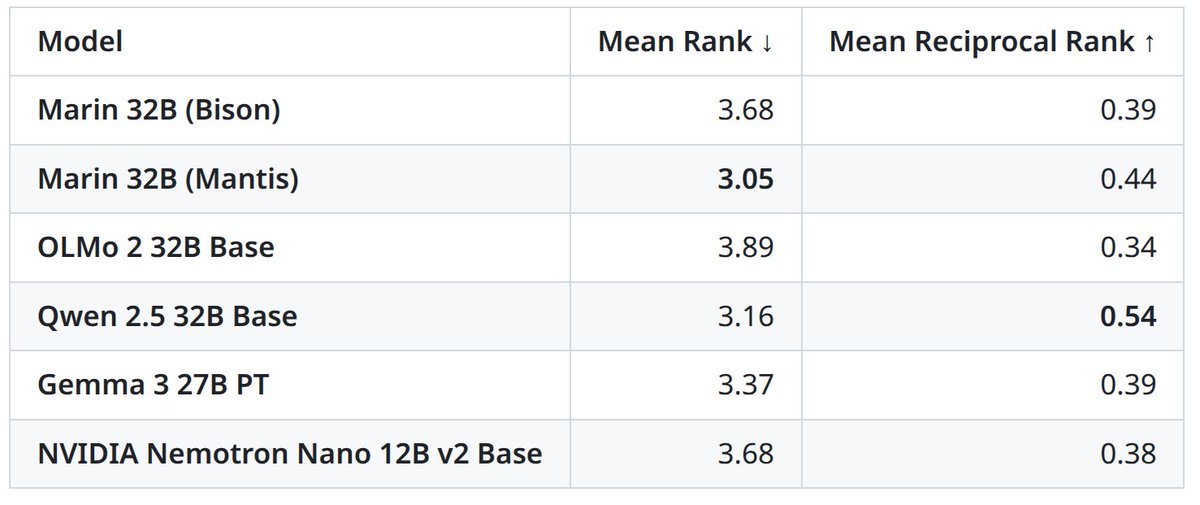
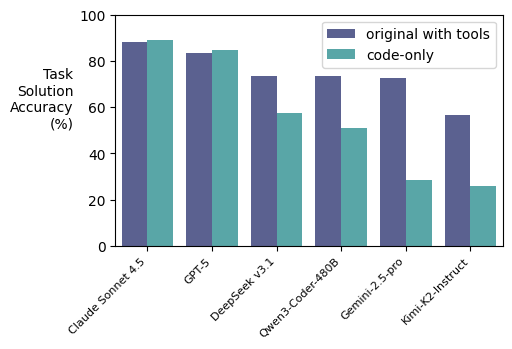
Just tried out @gepa_ai's optimize_anything library — we split the Snorkel Finance Benchmark into train/val/test, gave optimize_anything the 100 train examples, and it boosted test set performance by 8 points 👀👀
We gave it the system prompt to optimize, and found it added helpful tool usage rules, numerical extraction & formatting additions & best practices.
English