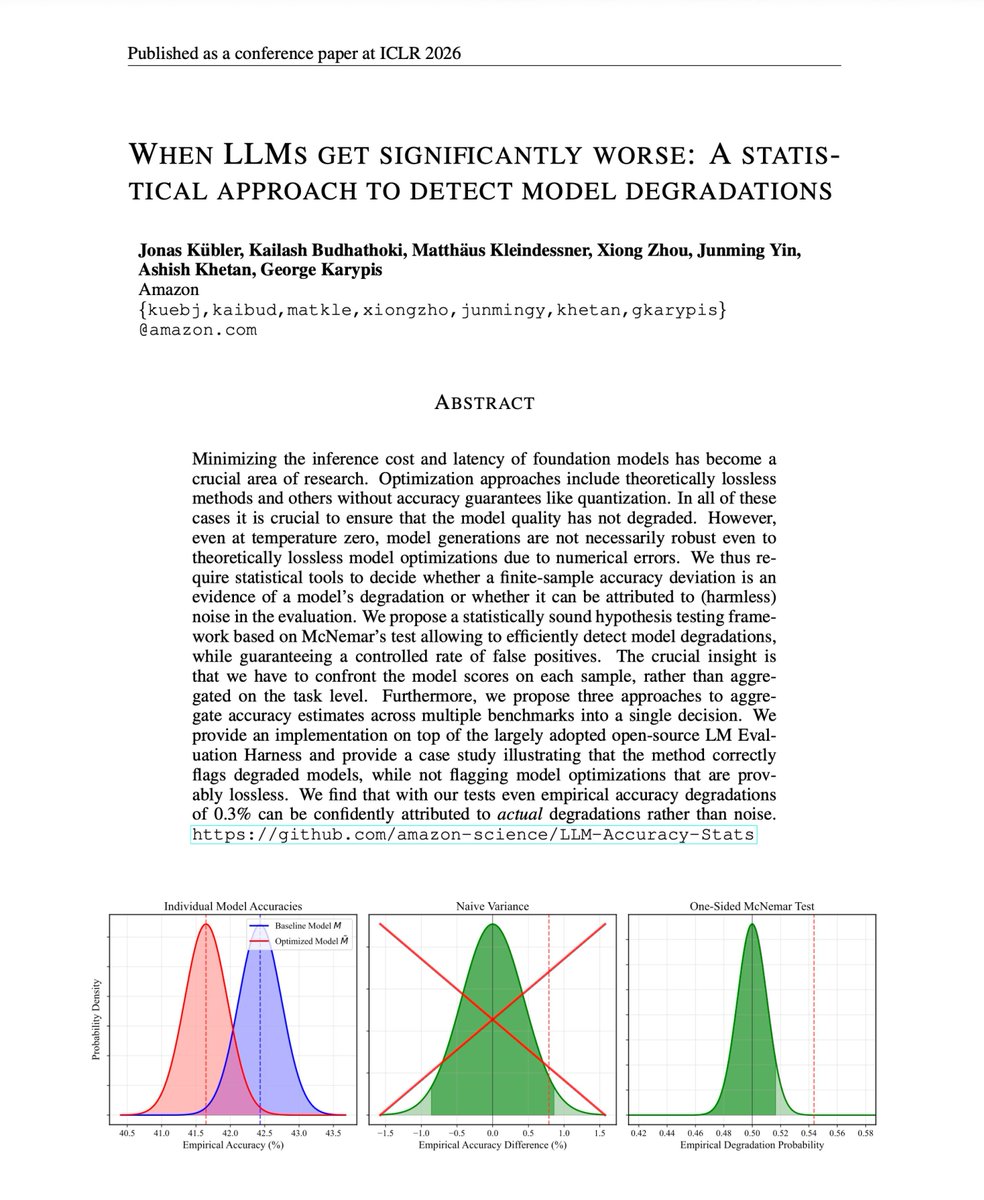
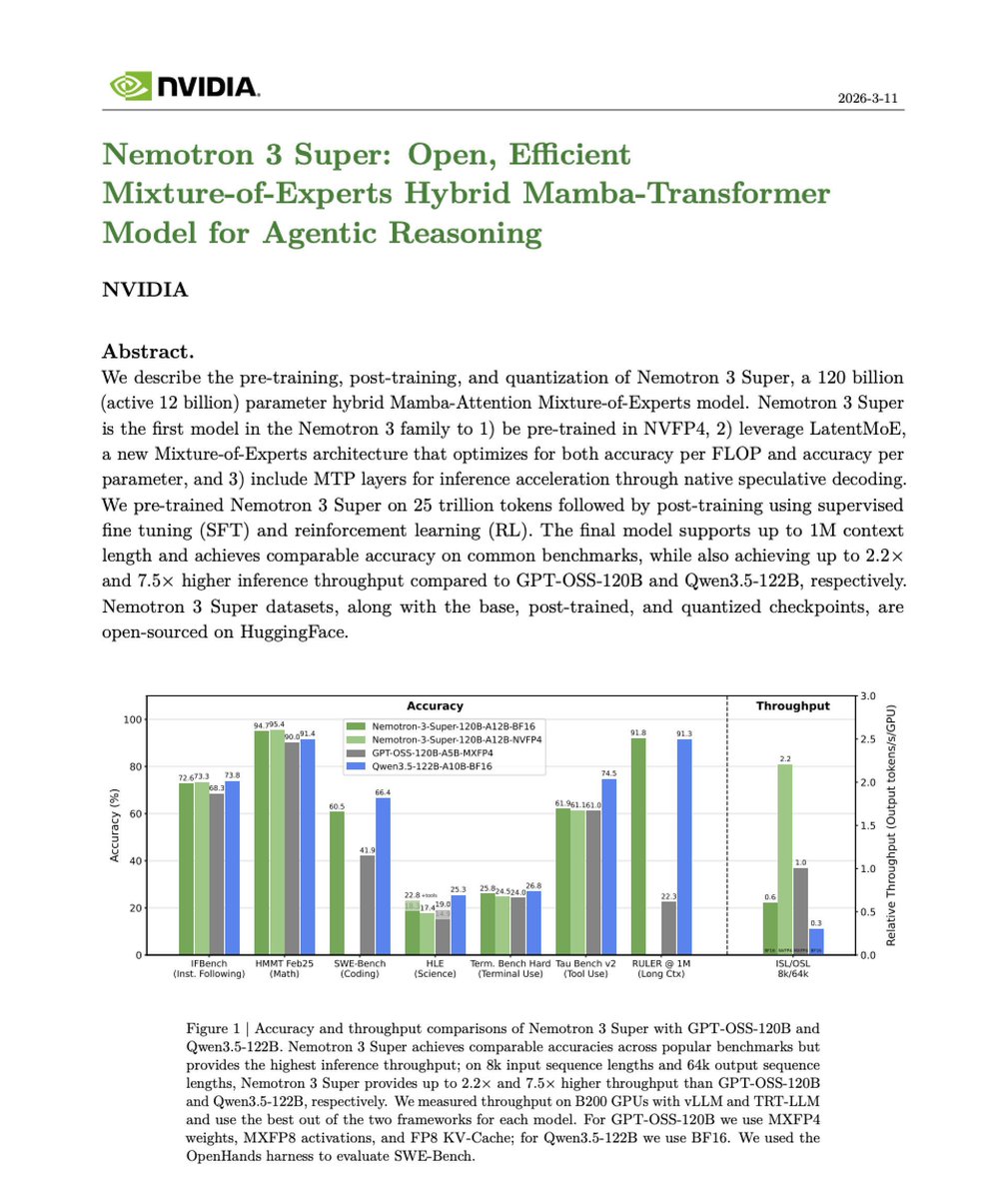
Choosing the right fine-tuning method can save weeks and thousands in compute.
3 main approaches:
Full Fine-Tuning: Retrains everything. High cost, max performance. Only worth it for mission-critical apps.
LoRA: Trains adapters, freezes base model. Moderate cost. Great for multiple tasks.
QLoRA: Compressed LoRA. Low cost, runs on consumer GPUs. Perfect for prototyping but risky for production.
Best workflow: Start QLoRA → validate → scale with LoRA → reserve full fine-tuning only if accuracy demands it.

English