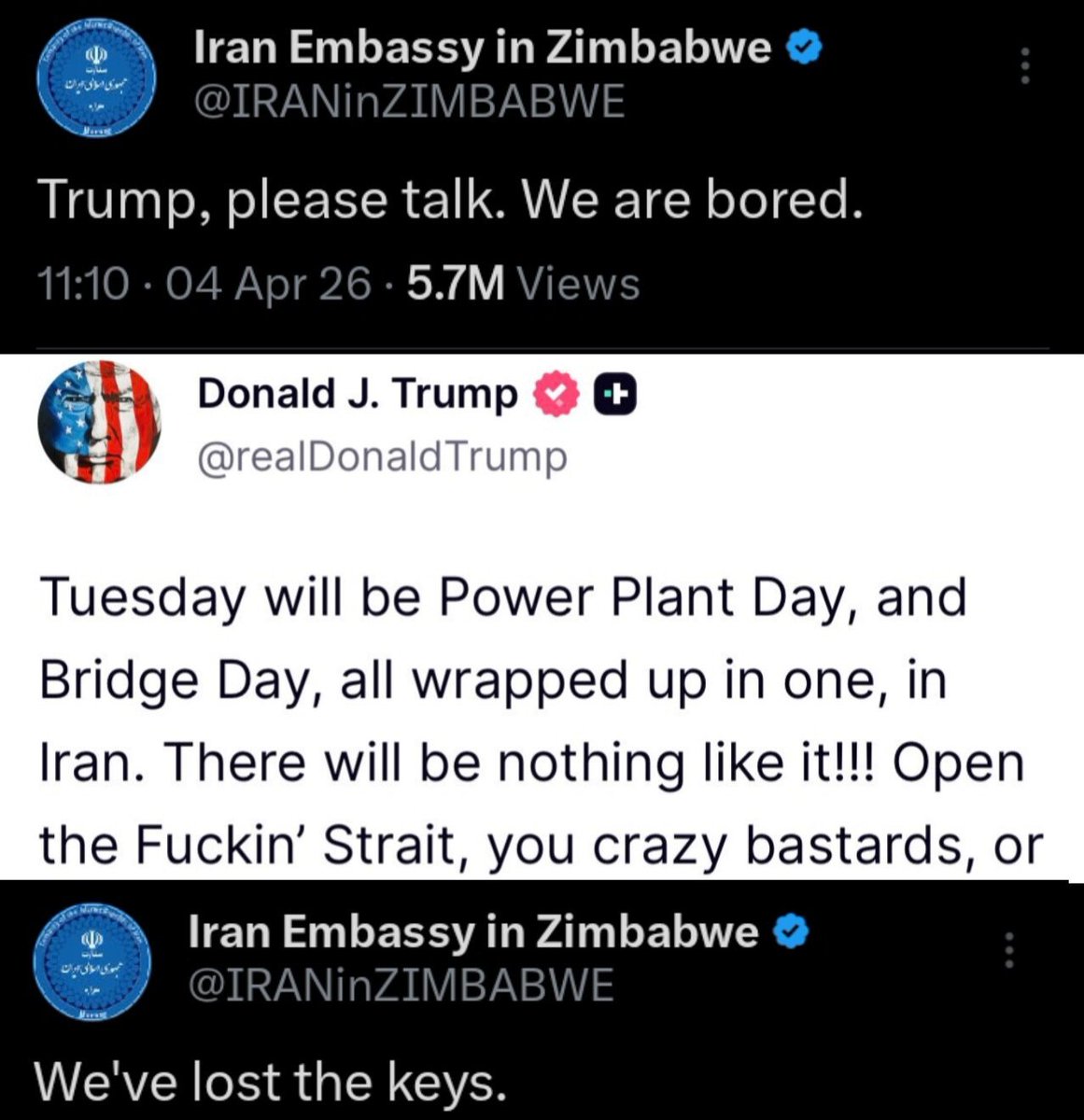
Sabitlenmiş Tweet

Have you ever felt captivated inside yourself? Captivated inside the cage of wrong habits, indiscipline, failure. Trying hard to come out like a bee trapped in spiderweb, but failing to do so. I am in the same position rn.
English
Ashmit JaiSarita Gupta
2K posts

@ashmitjsg
Post on Software Development, Quantum Computing and College Experience. | GSoC 24 @AsyncAPISpec | Ex-Quantum Computing Intern at @Creed_Bear Dubai | NITH'25




Chose to write custom Kafka serializers instead of using Spring's built-in JsonSerializer. Spring Boot 4 uses Jackson 3 (tools.jackson.*), which has API differences from Jackson 2. Custom serializers are explicit, predictable, and debuggable. No magic. No version conflicts.
Setting up the Kafka producer today. Key config decisions: - acks=all: wait for leader + replicas to confirm write - enable.idempotence=true: no duplicate messages on retry - retries=3: transient failures handled automatically This is the minimum config for a reliable producer.
Used Lombok @Builder + final fields for the Kafka event DTO. Builder pattern avoids constructor explosion as the schema evolves. Immutability prevents accidental field mutation between creation and publishing. For request DTOs (user input), I keep them mutable for Jackson.

Designing the RawLogEvent DTO that gets published to Kafka. Fields: eventId (UUID), tenantId, serviceName, environment, receivedAt (server time), logTimestamp (client time), level, message, trace. Two timestamps on purpose. The discrepancy tells you how delayed a log was.
Built a RequestHeaderExtractor utility today. Instead of reading X-TENANT-ID in every controller method, a single utility extracts all required headers into an immutable RequestContext object. One place to add new required headers. One place to fix validation. Clean. #java

One thing I was deliberate about: the ingestion endpoint returns 202, not 200. 202 means "accepted for processing" — the log is in Kafka, but downstream processing hasn't happened yet. Semantically honest. Don't tell the client something is done when it isn't. #api
Designed the ingestion API contract today. POST /api/v1/logs Required headers: X-TENANT-ID, X-SERVICE-NAME, X-ENVIRONMENT, X-API-KEY Body: timestamp, level, message, trace (optional) Response: 202 Accepted (async — we don't wait for Kafka confirmation) #api #backend
Starting the first service: ingestion-gateway. Responsibility: accept logs from client services via HTTP, validate them, and publish to Kafka. That's it. Single responsibility. No business logic, no storage, no auth complexity — just reliable ingestion. #microservices #java
One of the first design decisions: what should the Kafka partition key be? Options: eventId (random), serviceName, or tenantId. Chose tenantId. This guarantees all logs from one customer are processed in order. Critical for time-window clustering later. #kafka #systemdesign
Set up the local Kafka stack today using Docker Compose. Confluent's cp-kafka + Zookeeper. Single broker, 1 replication factor for local dev. The first topic I created: raw-logs. Every log from every service on the platform will flow through this topic first. #kafka #backend
Naming the project: log0 - An intelligent incident copilot that turns raw logs into actionable incidents. It ingests high-volume logs from distributed services, normalises and clusters similar errors, and automatically creates incidents when recurring failures are detected.