@Dorialexander Hit who? People in the field already know and I‘m yet to see a politician who seems even close to understanding what is going on
English
Johannes Messner
398 posts
@atomicflndr
🇪🇺

You will see a lot more european turbo cope in the next couple years


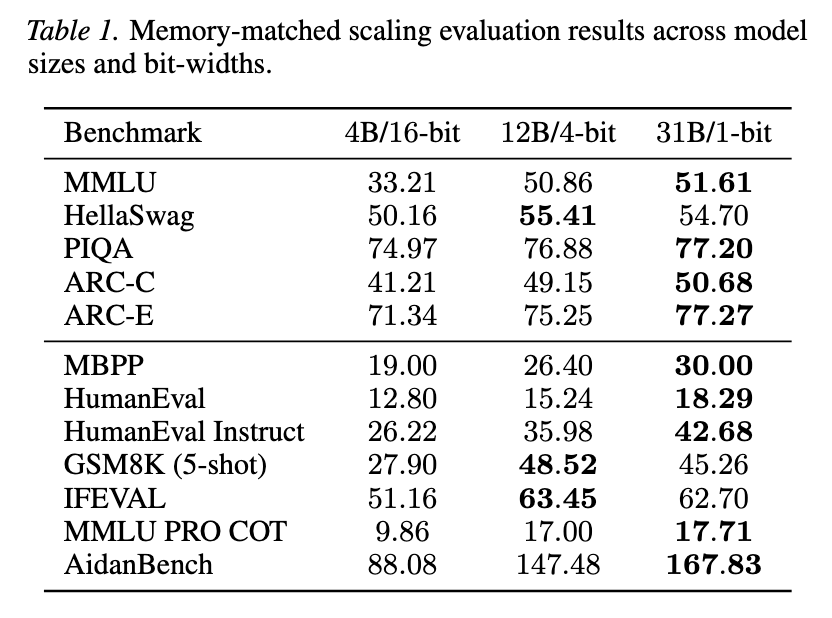
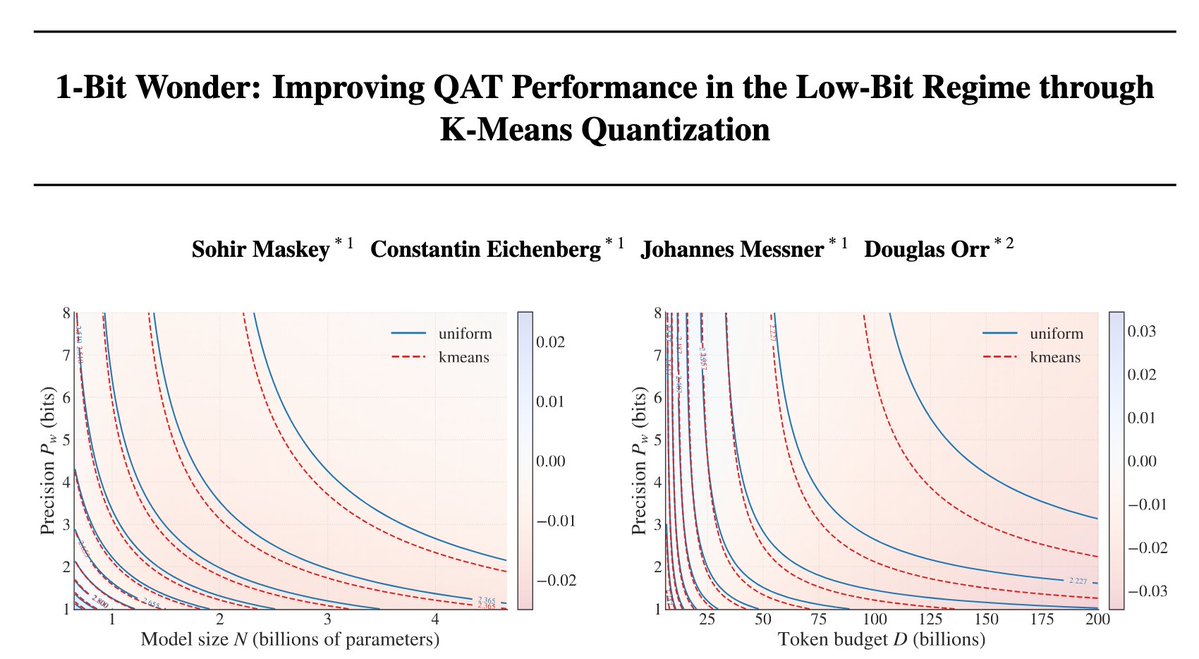
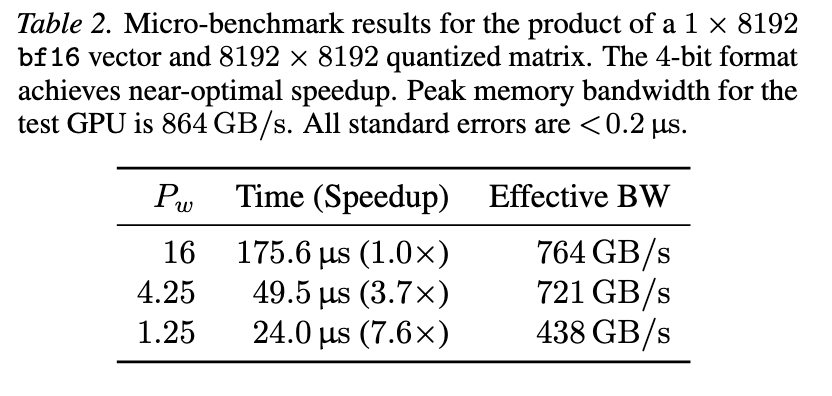
Would you rather use 1 million × 16-bit weights, 4 million × 4-bit weights, or even 16 million × 1-bit weights? In joint work between Aleph Alpha Research and Graphcore, we asked this question of LLMs — the answer encouraged us to embrace the wonder ✨ of 1-bit weights, which can outperform 4-bit and 16-bit weights on a fixed weight memory budget. In our work - ⚖️ A scaling laws evaluation prompts us to consider very low-bit formats - 📈 Scaled-up tests show the power of memory-matched models with 1-bit weights - ⚡ Kernel benchmarking demonstrates their feasibility for autoregressive inference Read all about it in our blog and paper (link below! ⬇️) Massive thanks to our collaborators at Aleph Alpha Research! Authors: @SohirMaskey, Constantin Eichenberg, @atomicflndr and @douglasahorr

We're excited to introduce @arcee_ai's Trinity Large model. An open 400B parameter Mixture of Experts model, delivering frontier-level performance with only 13B active parameters. Trained in collaboration between Arcee, Datology and Prime Intellect.


Introducing INTELLECT-3: Scaling RL to a 100B+ MoE model on our end-to-end stack Achieving state-of-the-art performance for its size across math, code and reasoning Built using the same tools we put in your hands, from environments & evals, RL frameworks, sandboxes & more

We’re excited to announce that we have joined forces with @JinaAI_, a leader in frontier models for multimodal and multilingual search. This acquisition deepens Elastic’s capabilities in retrieval, embeddings, and context engineering to power agentic AI: go.es.io/48QeYCM

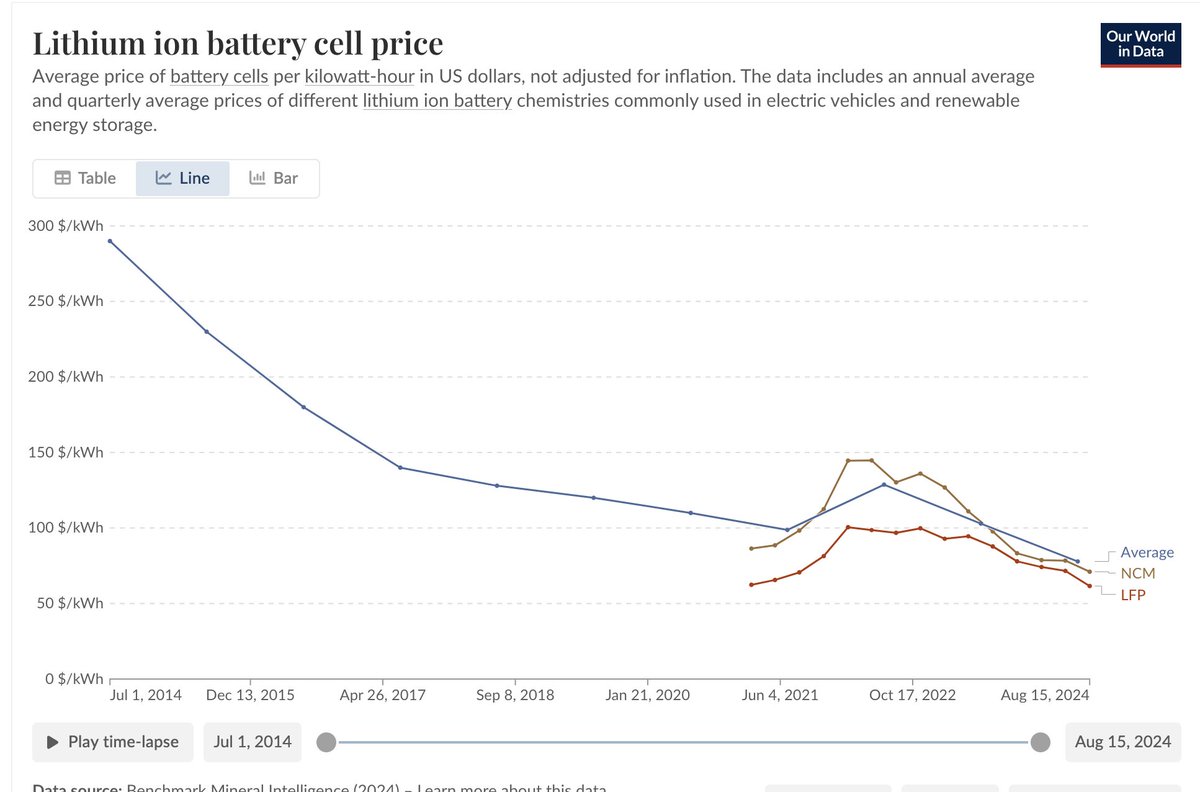
Chinese electric vehicles now account for more than half of global sales, priced thousands of dollars below US & European models, per WSJ





First high-performance inference for hierarchical byte models. @LukasBluebaum and I developed batched inference for tokenizer-free HAT (Hierarchical Autoregressive Transformers) models, developed by @Aleph__Alpha Research. In some settings, we outcompete the baseline Llama.🧵


Introducing two new tokenizer-free LLM checkpoints from our research lab: TFree-HAT 7B Built on our Hierarchical Autoregressive Transformer (HAT) architecture, these models achieve top-tier German and English performance while processing text on a UTF-8 byte level.

I wouldn't really consider these to be tokenizer-free tbh. Unlike Hnets, these models are word level. The sequence is turned into words (this is literally called tokenization). Then, the bytes of these words are turned into embeddings, which are then processed by a model.