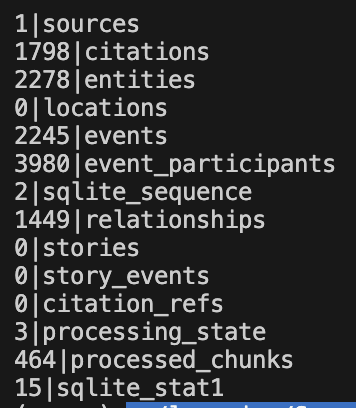
Sabitlenmiş Tweet

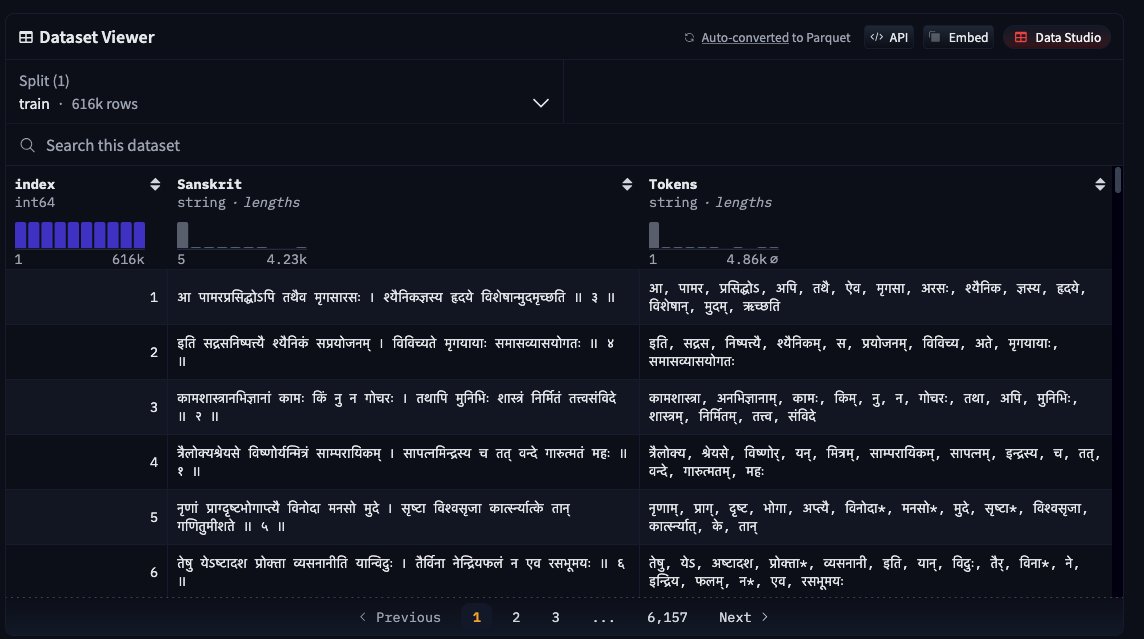
this is the sanskrit dataset which has 600K+ shlokas along their morpheme-based tokens, on this dataset, we can train a decent tokenizer which will be morphologically accurate.
thinking about using Morfessor, if you peeps have any suggestion please tell me
huggingface.co/datasets/snskr…
English