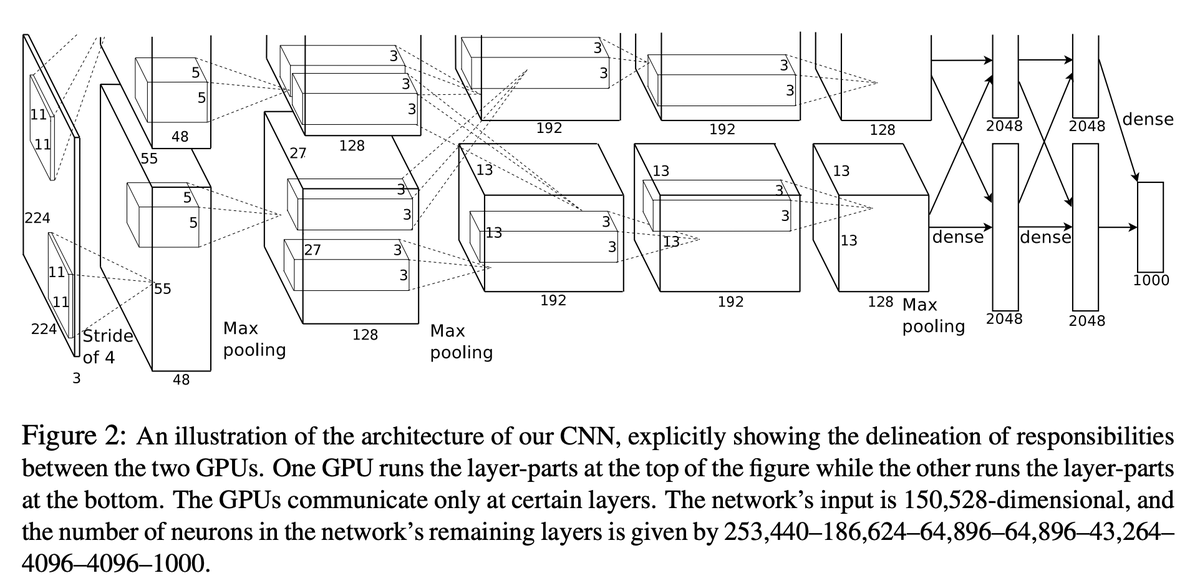
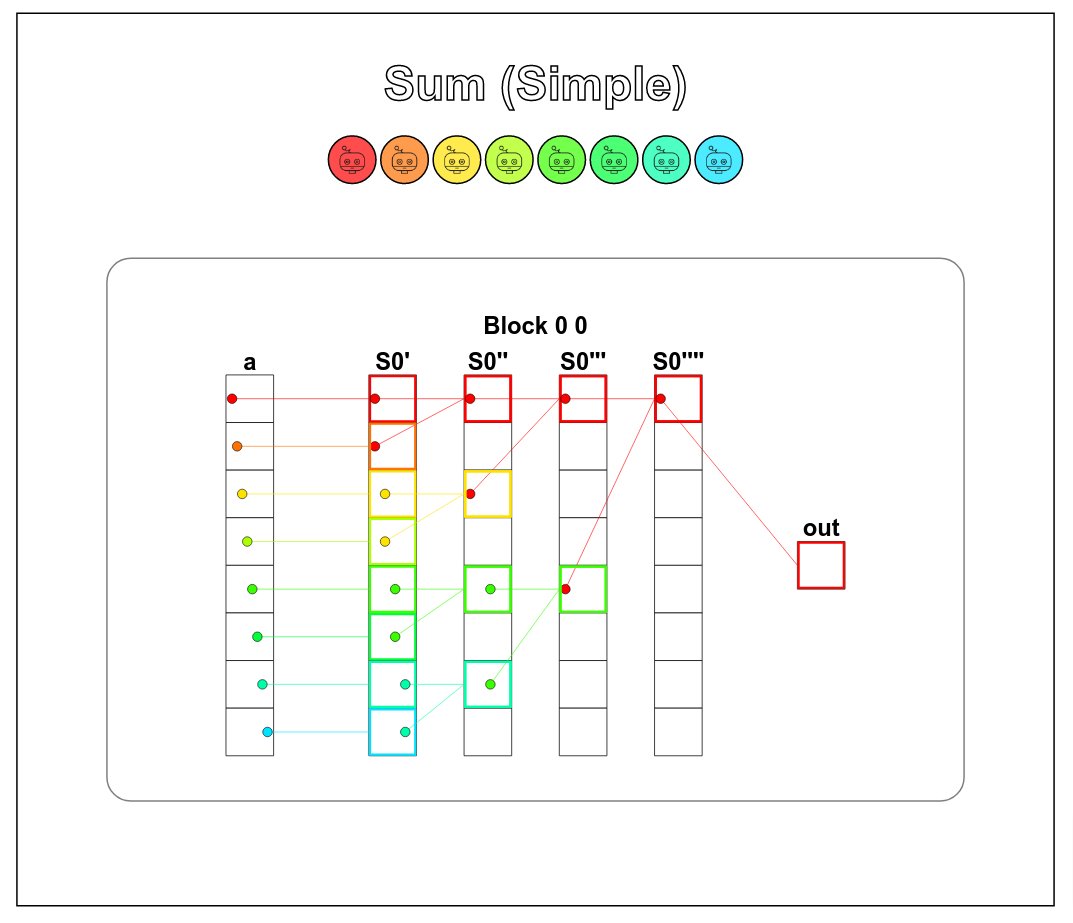
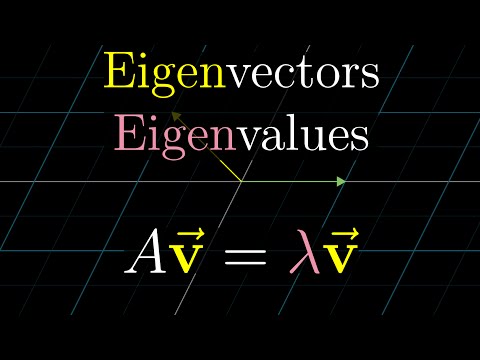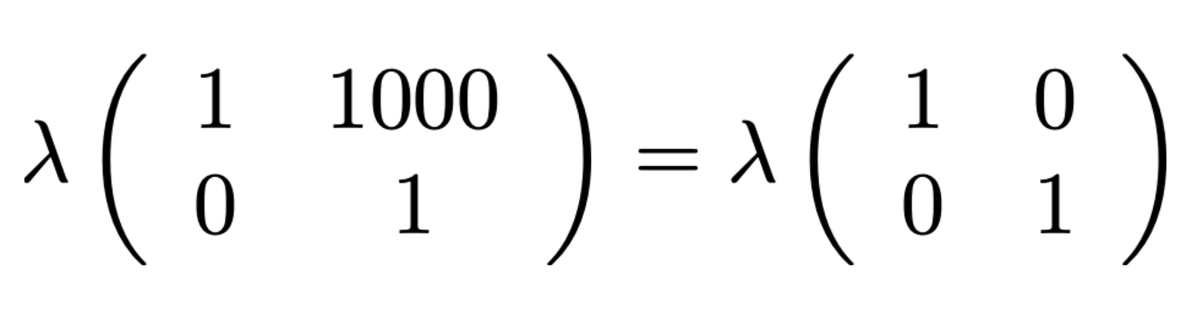@rdesh26 That makes sense. Feels similar to recent RL work on full-duplex spoken dialogue models, where RL is learning an interaction policy (when to speak, wait, yield, repair) rather than just minimizing latency. Reward design here seems really tricky.
Ref: openreview.net/forum?id=QbLbX…
English