Mr Barry
609 posts


Mr Barry retweetledi

You can now fine-tune Gemma 4 (and 500 other open source models) in a free Google Colab 🔥
1. Open the Colab notebook below
2. Run the blocks to launch Unsloth Studio
3. Choose a model and dataset
4. Hit 'Start Training'
And you're done!
English
@LeninUGReal @DinoLeadingNews Thay vì telegram thì build WEB UI luôn để dễ tùy chỉnh. trực quan hơn.
cảm ơn sếp LêNin
Tiếng Việt

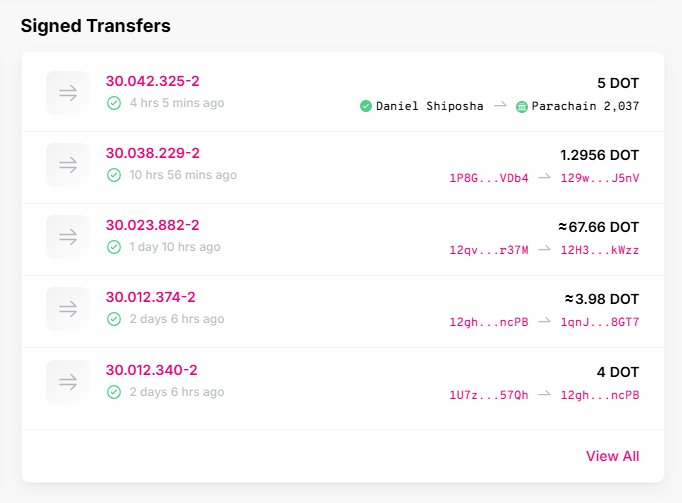
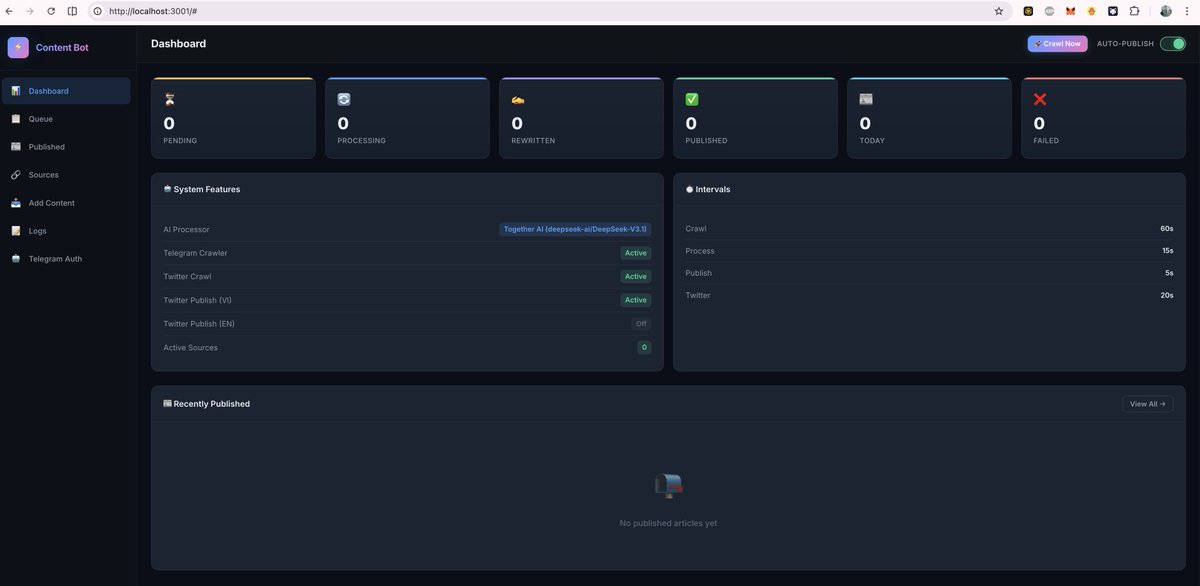
Tổng kết bot hôm trước share cho anh em . chạy 2 tuần Follow tăng từ 76k lên 83K @DinoLeadingNews
Thu nhập 121$ x + 22 Ton ~ 30$ ( ảnh dưới cmt )
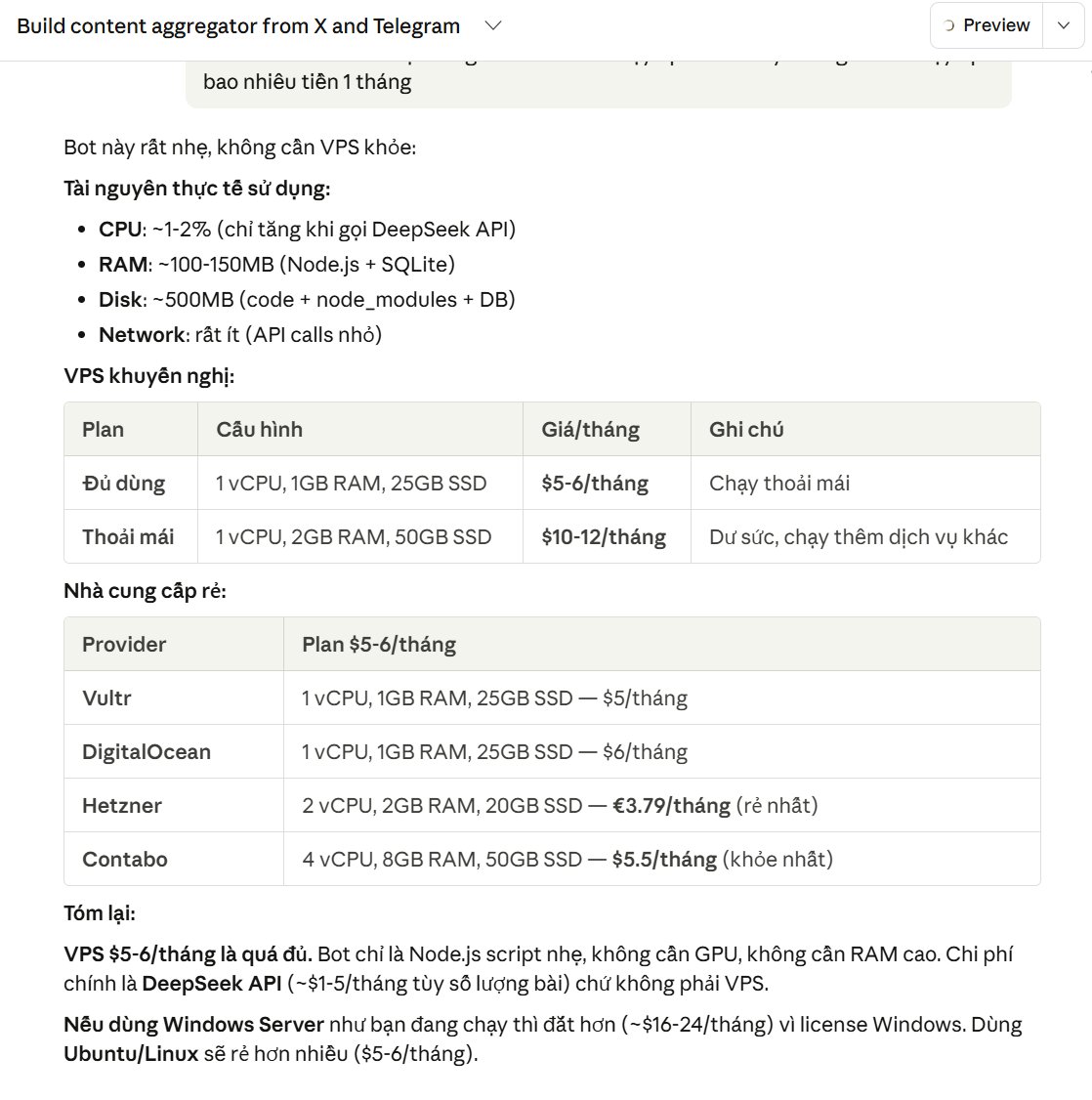
Chi Phí :
1 - Deepseek dùng để viết lại bài + chuyển đổi ngôn ngữ đang chạy 6 bot đủ kiểu từ 1 account nên chi phí riêng cho bài trên twt ước tính tầm 0.5$
2- API cào bài từ twt và đăng ngược ( nếu các bạn lấy bài từ nguồn telegram hoặc các nguồn khác thì chi phí /2 ) vì cào bài + đăng 3 chỗ ( VNI - ENG - JAV =)) ) nên chi phí thực tế /4 ~ 3$
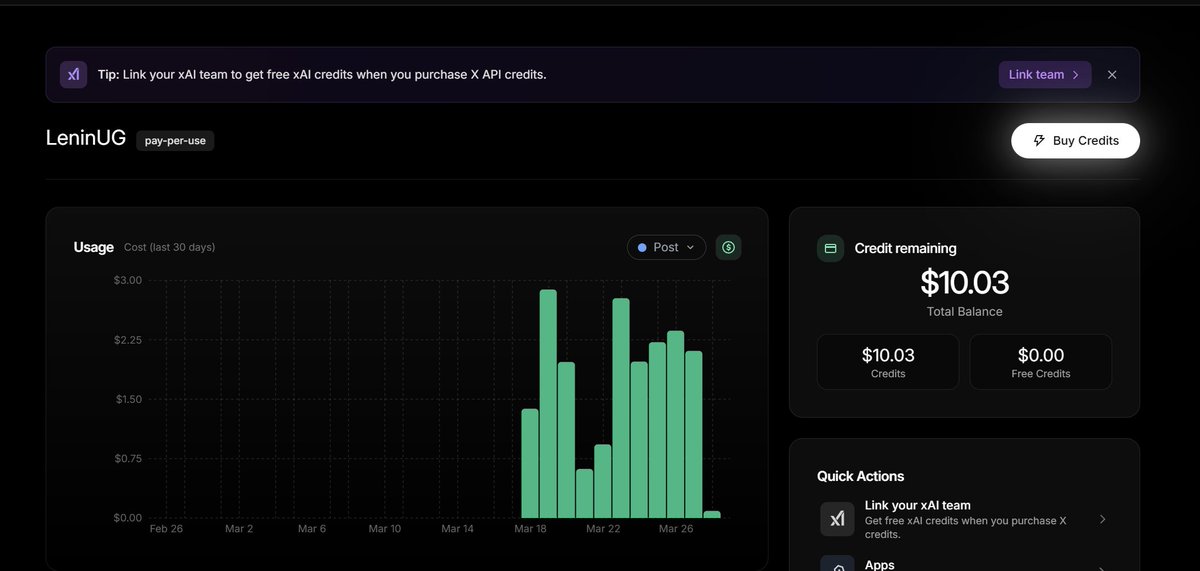
2- VPS thực tế thì đang chạy vult vps 50$/ tháng do chạy rất rất nhiều bot + ứng dụng và dùng windows os . ảnh 1 cung cấp giá vps /thang cho bot trên anh em ước lượng tầm 5$ có thể chạy vài bot rồi
Tổng thu 150$ - chi phí ~9$ . Nói chung là ROI ok anh em có thể Scale được , thu sẽ tăng dần còn chi phí gần như là cố định nên đường biên lợi nhuận làm dần sẽ tăng dần .
Nay mới dám Post - hướng dẫn có luôn sau 30' nữa . Hôm trc không dám post vì ko biết thu bn mà chi ra sợ PNL - thì đéo ăn thua mất công anh em làm .
PS : Mình chỉ chia sẽ những gì mình biết và có , đôi khi đúng và có những điều không đúng , xin đừng nặng lời.


Tiếng Việt

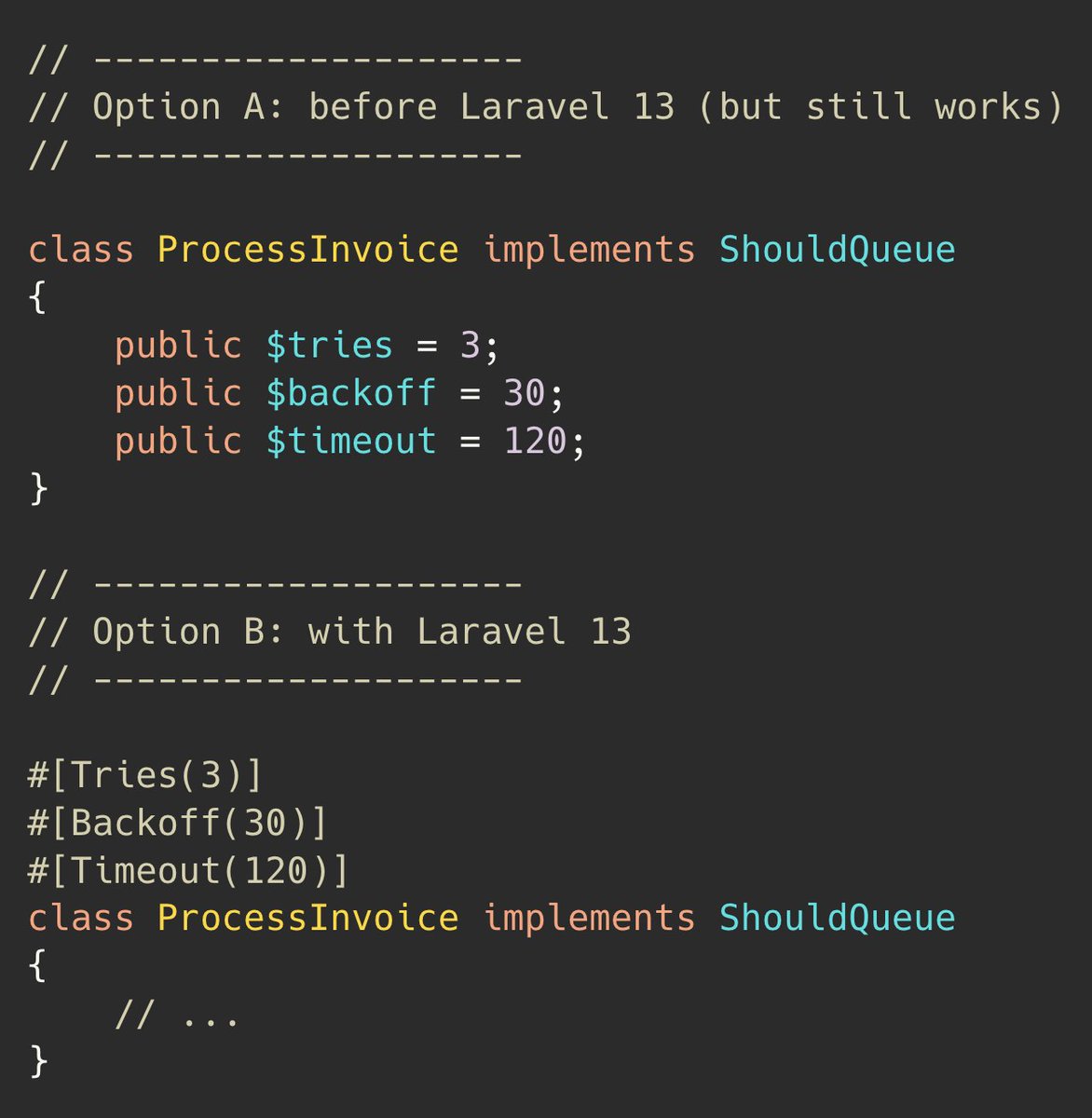
What do you prefer in Laravel 13: A or B?
(poll in the tweet reply)
English










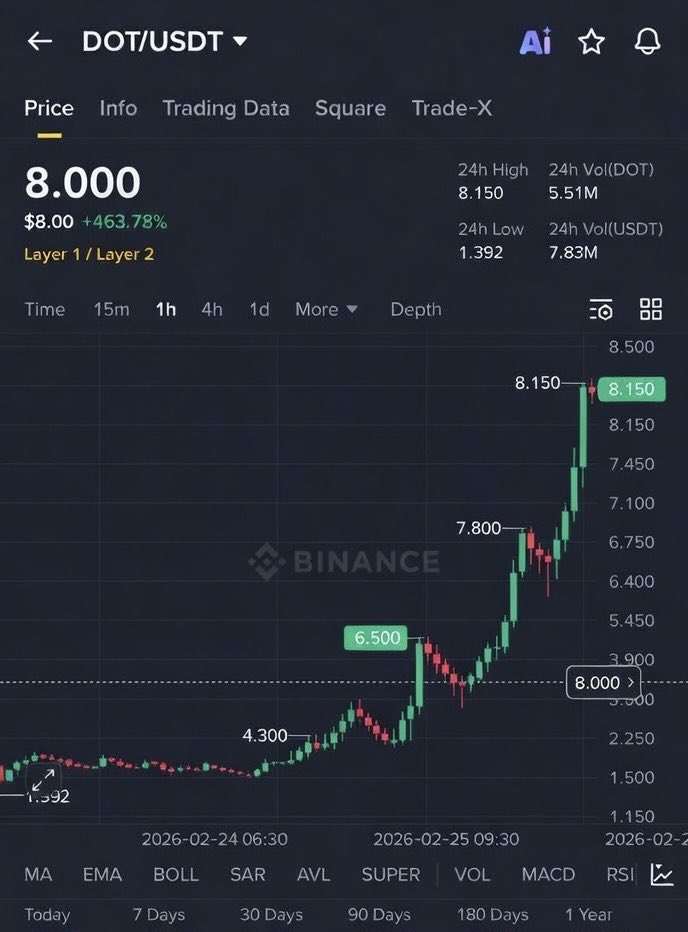
There is roughly 450-500 million $DOT left in the world after supply capping to 2.1B
secure the bags before it was too late 🚀🚀
less supply - high demand, this is what the chart will look like soon 📈🔥
English

Name a red flag that immediately makes you NOT want to buy a coin.
English






🇺🇸BULLISH #Polkadot ETF listed on nasdaq and become first crypto company to get listed on nasdaq 300$ per $Dot 🔥🔥🚀


English


@akshay_pachaar Does it work for scanned pdf? Or mixed one( text, chart, table, image in pdf )?
English

Researchers built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
And it hit 98.7% accuracy on a financial benchmark (SOTA).
Here's the core problem with RAG that this new approach solves:
Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity.
But similarity ≠ relevance.
When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar.
But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query.
Traditional RAG would likely never find it.
PageIndex (open-source) solves this.
Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents.
Then it uses reasoning to traverse that tree.
For instance, the model doesn't ask: "What text looks similar to this query?"
Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?"
That's a fundamentally different approach with:
- No arbitrary chunking that breaks context.
- No vector DB infrastructure to maintain.
- Traceable retrieval to see exactly why it chose a specific section.
- The ability to see in-document references ("see Table 5.3") the way a human would.
But here's the deeper issue that it solves.
Vector search treats every query as independent.
But documents have structure and logic, like sections that reference other sections and context that builds across pages.
PageIndex respects that structure instead of flattening it into embeddings.
Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications.
But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines.
For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis.
Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself.
I have shared the GitHub repo in the replies!
English



@T_BALLER6 Only spent two days there but I can see why it’s popular. It seems a lot more people speak English down there than in Hà Nội. Definitely a party scene.
English
Just spent the last two weeks in Vietnam with my Vietnamese in-laws.
Holy shit, what a country.
English