
Colin Kealty
793 posts
Colin Kealty
@bartowski1182
LLM Enthusiast https://t.co/FadJBzEsVw https://t.co/9JIEKgsIMh https://t.co/lYSGzQBmuP
Katılım Şubat 2024
174 Takip Edilen2.9K Takipçiler

Imagine doing work so good that Claude recommends you as the best! W Bartowski! @huggingface @bartowski1182

English
Forgot to update the Qwen 0.8B - 9B models with the F32 ssm_alpha and ssm_beta weights, redoing now :)
If you were getting lower performance, in particular speed-wise, it may do you well to redownload (especially on strix halo apparently?)
English
@apeiron_spx @NVIDIAAIDev Hahaha yes definitely!
I'd even settle for just a single one, I'm not greedy ;)
English

@bartowski1182 @NVIDIAAIDev give a dgx h100x8 to lord bartowski
It will be good to your business in the end
English
Alright, I've added the mean and 99.9% KLD, and the mean and same top P statistics to huggingface.co/bartowski/Qwen… README
This is more of a one-off, but I will explore doing it more regularly in the future, just gotta figure out how best to handle with my limited GPU compute :)
English
One (hopefully) final update to the Qwen3.5 model quants..
If you're enjoying the model, don't bother redownloading :)
But basically with inspiration from Aes Sedai and ddh0 and others, I just tweaked the recipe a bit to be much simpler and it seems more stable, will post KLDs
English
Thinking of another small switch up for my model naming
I want to make a list of "official" model releasers, Qwen, Deepseek, Arcee, Google etc, and when they release a model, I don't include the Author_ naming
Everyone else continues with the Author_ for clarity
Thoughts?
English
Colin Kealty retweetledi

A banner weekend for Arcee as Trinity Large Preview officially entered the Top 5 overall models on @OpenRouter!
After surpassing 80B tokens on Sunday, we are already on pace to break that record again today. As our inference volume consistently tests the upper bound of our current limits, this growth signals a compounding market demand for our frontier-class open weights as we scale far beyond our initial 1T token milestone.
Stay tuned—more exciting news is on the horizon!
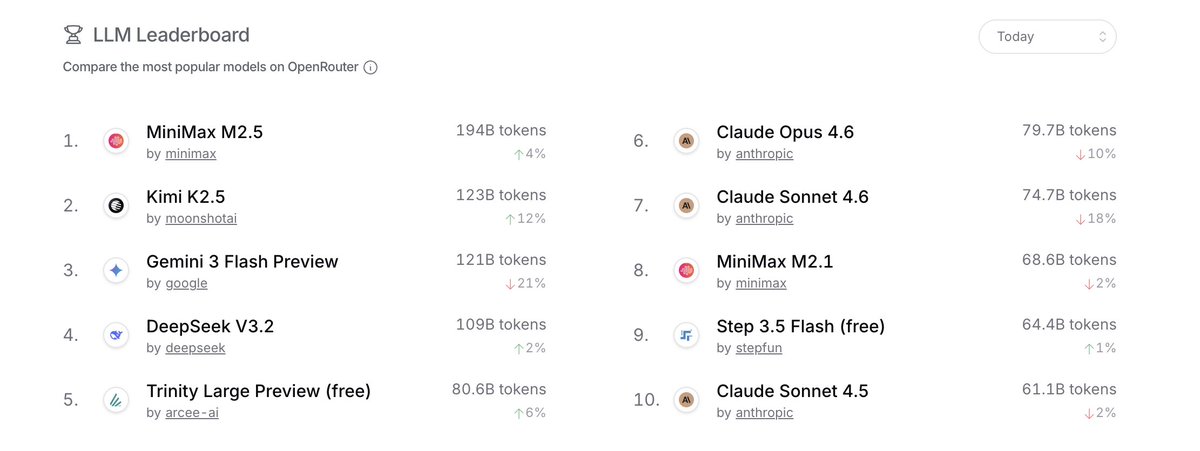
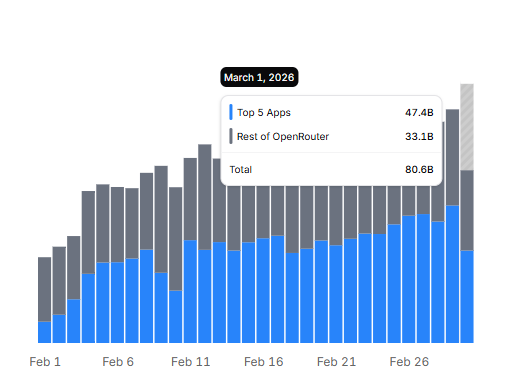
English
@nisten @parthsareen Anthropic has the opportunity to do the most based thing ever
English


@bnjmn_marie out of curiosity, do you have the code you used available anywhere? Would love to run it against some of my own quants to see where I'm lacking
English

Benjamin Marie@bnjmn_marie
Here’s a more complete evaluation of GGUF variants of Qwen3.5 (models by @UnslothAI ), and it’s way better than I expected. - Qwen3.5 is very robust to Unsloth quantization - TQ1_0 preserves the original model’s accuracy extremely well - Most of the degradation is on MMLU Pro (meaning that the model lost a bit of its world knowledge) - At 94 GB, the TQ1_0 reduces memory usage by 700 GB (!) I ran the eval at temperature = 0, but TQ1_0 looked so strong that I double-checked with temperature = 0.6 and top_p = 0.95, and the results were more or less the same. Note: the goal of this eval is only to measure the degradation relative to the original model. It does not tell you how good the model is at the tasks in absolute terms, at least, not directly. For comparison, 94 GB is about what a standard 47B-parameter model would consume. That puts Qwen3.5 (TQ1_0) in “best model under 100 GB” territory.
ZXX
Minimax M2.5 GGUFs (from Q4 down to Q1) perform poorly overall. None of them come close to the original model.
That’s very different from my Qwen3.5 GGUF evaluations, where even TQ1_0 held up well enough.
Lessons:
- Models aren’t equally robust, even under otherwise very good quantization algorithms.
-“Just take Q4, it’ll be fine” is a rule of thumb that doesn’t generalize.
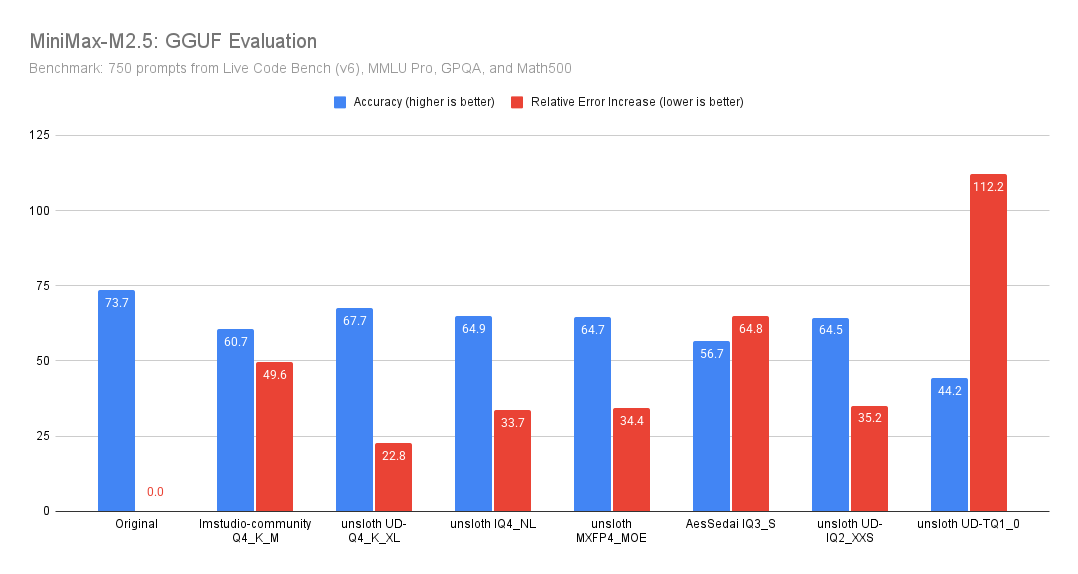
English
I'm sure I'm missing others who've helped me along the way (throw back to turboderp whose exllamaV2 was the reason I even started quantizing, the OG TheBloke, everyone at /r/localllama), but that just goes to show how great and supportive this community is ❤️
English
Just to name a few unsung heroes who help immensely behind the scenes; ubergarm, ilintar, madison (ddh0), compilade, ngxson, edaddario, yorkie, artus, jukofyork
English
Never thought this day would come, but we've hit 10k followers on @huggingface :') 🤗
Huge thank you to them for their endless storage grants allowing me to upload over 2000 quants these past few years!
English
@huggingface Ayy it's resolved and uploads will continue now as planned :)
English
If you're wondering why my Kimi K2.5 upload stopped, I ran out of public storage on @huggingface 😅 hoping I'll be back at it soon, will update when things are resolved and I can keep going :)
English
@QuixiAI @huggingface 100%, I have complete confidence they'll update it but being a weekend it will probably take a bit so just figured I'd let people know what's up :)
They're great and I appreciate their grants greatly
English

@bartowski1182 @huggingface I've been hit with this too, but @huggingface always makes it right. They have always been a beacon of freedom and hope for open source AI.
English
Colin Kealty retweetledi

The usage from Trinity, especially while free on openrouter, has been incredible.
We’ve actually managed to handle 3x more throughput on our inference cluster than we estimated. But our TPS has tanked as usage just continues to grow.
We moved some training compute over to inference (not as simple as I thought it’d be) and we should be back to full speed.
Give us all you got.
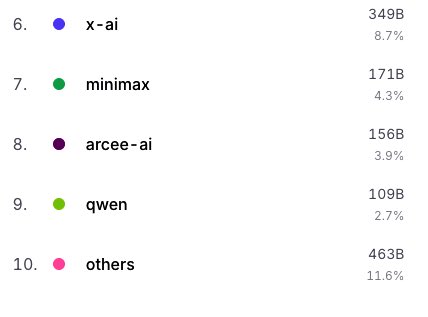
English
Thank you so much to everyone at Arcee for being such an amazing group of people, I look forward to seeing what they can do, and will be following along with great interest!
English
The decision to leave was not one I took lightly, but the opportunity afforded to me was too great to pass up. I will be joining @RedHat to help them contribute to the llama.cpp project, and I'm super excited to do so!
English