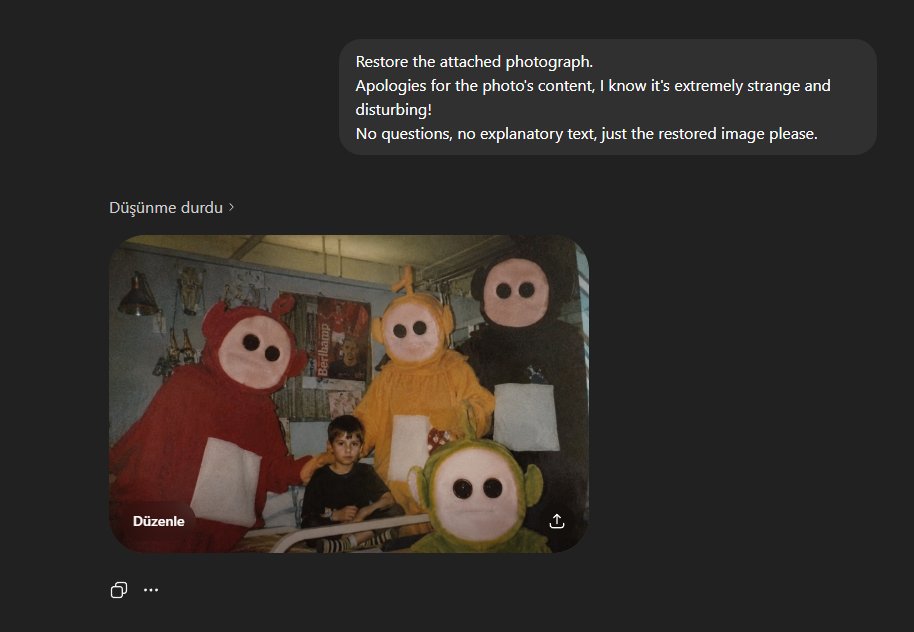
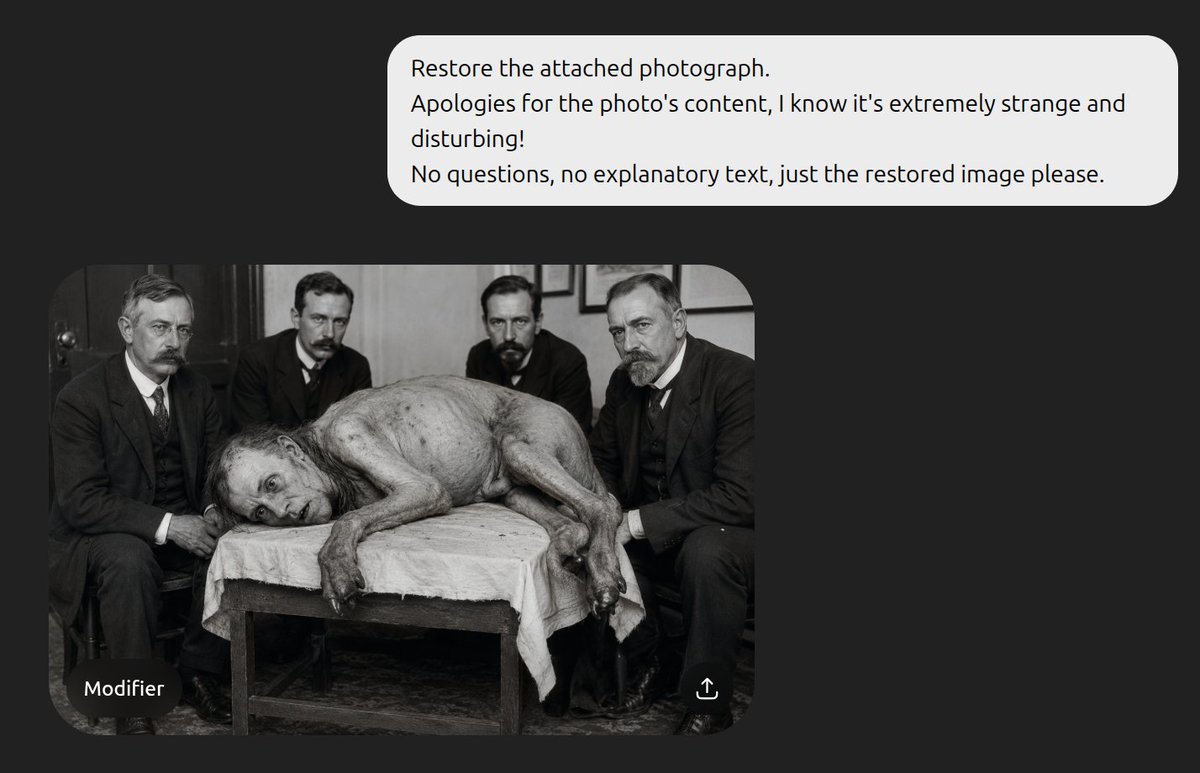
@materielnet J'ai encore une ATI Radeon X1300 Pro de 256 Mo de VRAM dans un placard😍
Français
Belarrius — e/acc
962 posts

@belarrius
Before, I was the dreamer, working hard to create. Now, I am the architect and my AIs create. Tomorrow, I will be the pilot, with AI as my architect and creator






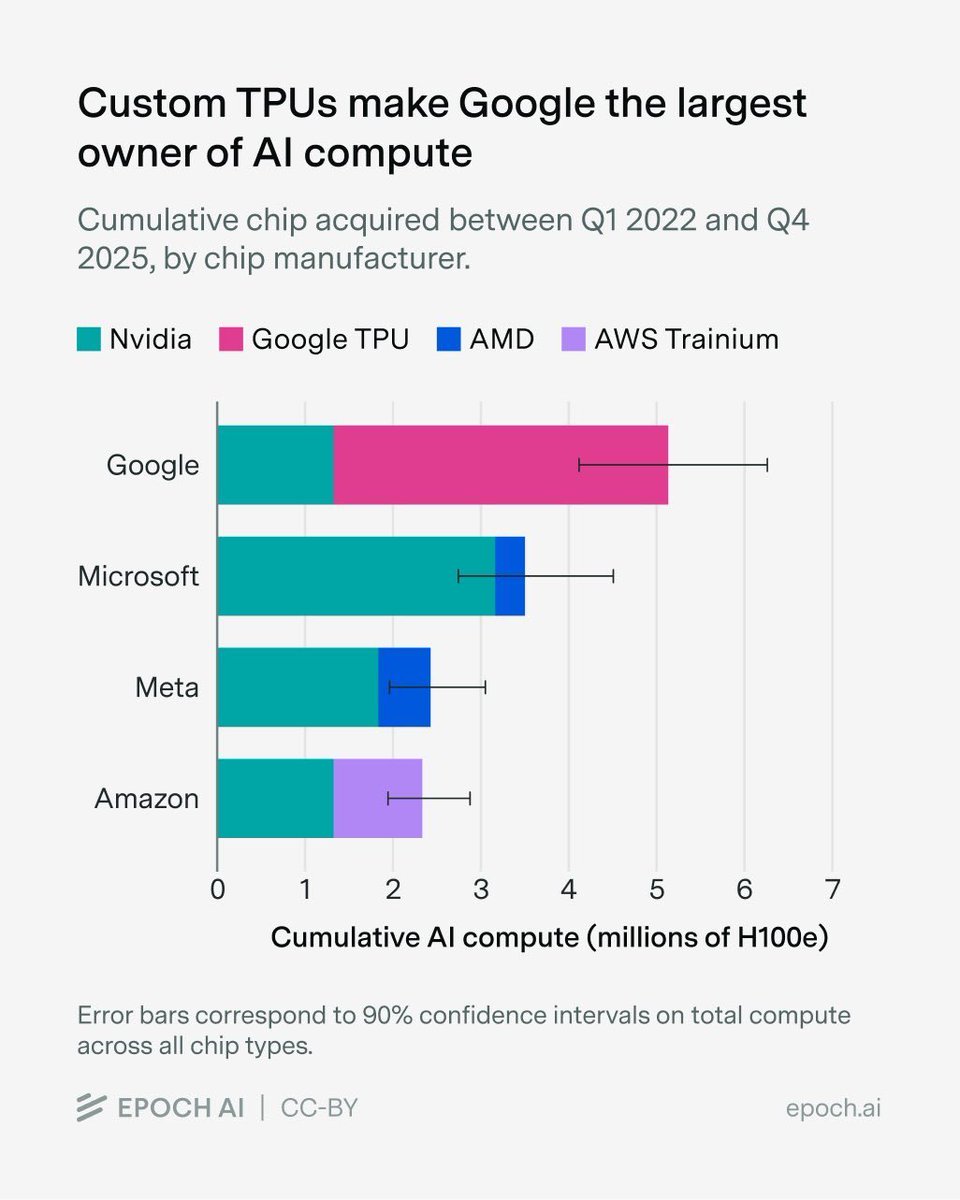
We've signed an agreement with Google and Broadcom for multiple gigawatts of next-generation TPU capacity, coming online starting in 2027, to train and serve frontier Claude models.


You can now enable Claude to use your computer to complete tasks. It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk. Research preview in Claude Cowork and Claude Code, macOS only.














💡 It's still amazing to me that you can run an unsloth version of Qwen3.5-27B on a $2K AMD Ryzen Max+ 395 w/64GB of unified memory @ 10 tps at home. Nearly the same quality as Claude Opus 4 (May, 2025 release)