Bernardino Romera-Paredes retweetledi

We’re excited to announce our collaboration with @NVIDIA, @Quantinuum and @AWS. Read more in our latest blog post: hiverge.ai/blog/quantinuu…

English
Bernardino Romera-Paredes
1.2K posts

@ber24
Previously core team member of AlphaFold2, AlphaTensor, and FunSearch at Google DeepMind. Now starting something new



- TTA: Skip for easy examples - Thermal throttling: Sleep for 8s between runs (only affects average not record time) Note: The authors reported a time of 2.02 seconds. My reproduction (torch 2.7.0; hardware seen below) had a min time of 1.99s. Code: github.com/hiverge/cifar1… 3/3

New CIFAR-10 training speed record: 94% in 1.99 seconds on one A100 Previous record: 2.59 seconds (Nov. 10th 2024) New record-holder: Algorithmic discovery engine developed by @hivergeai Changelog: - Muon: Vectorize NS iter and reduce frequency of 'normalize weights' step 1/3

Love this project: nanoGPT -> recursive self-improvement benchmark. Good old nanoGPT keeps on giving and surprising :) - First I wrote it as a small little repo to teach people the basics of training GPTs. - Then it became a target and baseline for my port to direct C/CUDA re-implementation in llm.c. - Then that was modded (by @kellerjordan0 et al.) into a (small-scale) LLM research harness. People iteratively optimized the training so that e.g. reproducing GPT-2 (124M) performance takes not 45 min (original) but now only 3 min! - Now the idea is to use this process of optimizing the code as a benchmark for LLM coding agents. If humans can speed up LLM training from 45 to 3 minutes, how well do LLM Agents do, under different kinds of settings (e.g. with or without hints etc.)? (spoiler: in this paper, as a baseline and right now not that well, even with strong hints). The idea of recursive self-improvement has of course been around for a long time. My usual rant on it is that it's not going to be this thing that didn't exist and then suddenly exists. Recursive self-improvement has already begun a long time ago and is under-way today in a smooth, incremental way. First, even basic software tools (e.g. coding IDEs) fall into the category because they speed up programmers in building the N+1 version. Any of our existing software infrastructure that speeds up development (google search, git, ...) qualifies. And then if you insist on AI as a special and distinct, most programmers now already routinely use LLM code completion or code diffs in their own programming workflows, collaborating in increasingly larger chunks of functionality and experimentation. This amount of collaboration will continue to grow. It's worth also pointing out that nanoGPT is a super simple, tiny educational codebase (~750 lines of code) and for only the pretraining stage of building LLMs. Production-grade code bases are *significantly* (100-1000X?) bigger and more complex. But for the current level of AI capability, it is imo an excellent, interesting, tractable benchmark that I look forward to following.
Thrilled to announce @hivergeai. Our goal is to build algorithmic superintelligence. See how we accelerate AI training and solve large-scale planning problems: hiverge.ai/blog/introduci…

The Beluga™ Competition results are in! 🏆Congrats to teams led by @ber24 , Daniel Gnad & Jean Jodeau! Thanks also to the hundreds who registered & explored the challenge. 👉Check the winning teams bit.ly/3Yr3Nuu #TrustworthyAI #ExplainableAI

In @NatMachIntell, we show how our AI system AlphaTensor-Quantum can make quantum computing more efficient. 🖥️⚡ By optimizing quantum circuits, it’s helping run calculations faster to save resources and accelerate discoveries. ↓ goo.gle/4iHAITd

Android XR is coming in 2025, with developer preview announced now. And Samsung’s making a Vision Pro-like headset, and glasses after that. I wore the headset and Astra prototype glasses with displays…and all-seeing Gemini AI is the center of it all. cnet.com/tech/computing…



I had a fantastic time talking with @samcharrington (@twimlai) about @orionbooks' "Artificial Intelligence: 10 Things You Should Know" (geni.us/ArtificialInte…) and many exciting 2024 research papers (some of them from my teams) in the Open-Endedness community by outstanding researchers like @merrierm @jennyzhangzt @jeffclune @chrisantha_f @2ne1 @edwardfhughes @MichaelD1729 @ber24 @akbirkhan @_chris_lu_ @cong_ml @RobertTLange @j_foerst @hardmaru ... Levels of AGI: Morris et al. Levels of AGI: Operationalizing Progress on the Path to AGI. ICML 2024. doi.org/10.48550/arXiv… OMNI: Zhang et al. OMNI: Open-endedness via Models of human Notions of Interestingness. ICML 2024. arxiv.org/abs/2306.01711 Promptbreeder: Fernando et al. Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution. ICML 2024. arxiv.org/abs/2309.16797 Epistemology (@DavidDeutschOxf): Deutsch, D. (2012). The Beginning of Infinity. Penguin Books. Open-Endedness: Hughes et al. Open-Endedness is Essential for Artificial Superhuman Intelligence. ICML 2024. arxiv.org/abs/2406.04268 Rainbow Teaming: Samvelyan et al. Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts. NeurIPS 2024. doi.org/10.48550/arXiv… FunSearch: Romera-Paredes et al. Mathematical discoveries from program search with large language models. Nature, 625(7995), 468–475. doi.org/10.1038/s41586… AI Debate: Khan et al. Debating with More Persuasive LLMs Leads to More Truthful Answers. ICML 2024. arxiv.org/abs/2402.06782 AI Scientist: Lu et al. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv 2024. doi.org/10.48550/arXiv…
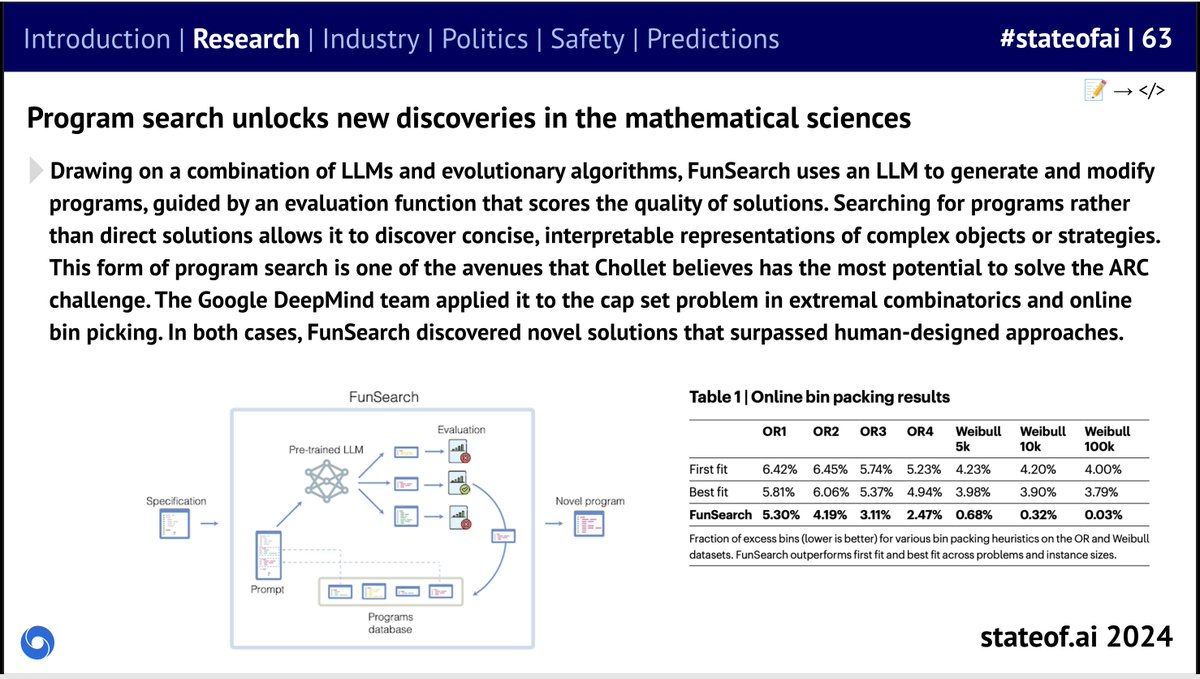
🪩The @stateofai 2024 has landed! 🪩 Our seventh installment is our biggest and most comprehensive yet, covering everything you *need* to know about research, industry, safety and politics. As ever, here's my director’s cut (+ video tutorial!) 🧵

BREAKING NEWS The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Chemistry with one half to David Baker “for computational protein design” and the other half jointly to Demis Hassabis and John M. Jumper “for protein structure prediction.”
Meet the next ML in PL Conference 2024 speaker: @ber24, researcher at @GoogleDeepMind!
