SUPSUP
186 posts



Where could we improve Composer 2.5?
We're working on the next model and would love your feedback.
Lots of work to do (our CursorBench evals below) in the coming weeks!

English

Gemini 3.5 Flash is quite useless for any kind of security task.

Google@Google
We asked our agents to build a working operating system from scratch using @Antigravity 2.0 and Gemini 3.5 Flash. It took: ⏱️ 12 hours 🤖 93 parallel sub-agents 🔄 15k+ model requests 🧠 2.6B tokens processed 💸 Less than $1K in API credits To build a functioning OS from scratch. #GoogleIO
English

Gemini 3.5 Flash reminds me of GPT 3.5 Turbo.
Insanely fast. Complete garbage output.
I asked it to build a Flappy Bird clone.
Look at the result.
This is pure slop.
Then you actually use it and the output looks like a 2022 model wrote it.
Google benchmaxed this one.
Optimized for benchmarks, not for real work.
Speed means nothing if everything it ships needs to be rewritten.
Claude Opus 4.7 and GPT 5.5 are slower and it doesn't matter because the output actually works.
English

@OfficialLoganK @GoogleDeepMind it sucks, it's not even close to other models preformence 😡
English

Welcome to Gemini 3.5 Flash, our most powerful model to date. It pushes the frontier of intelligence, speed, and cost putting 3.5 Flash in a class of its own.
We spent the last 6 months making sure Flash is great for real world use cases. It's available everywhere now!
English
SUPSUP retweetledi
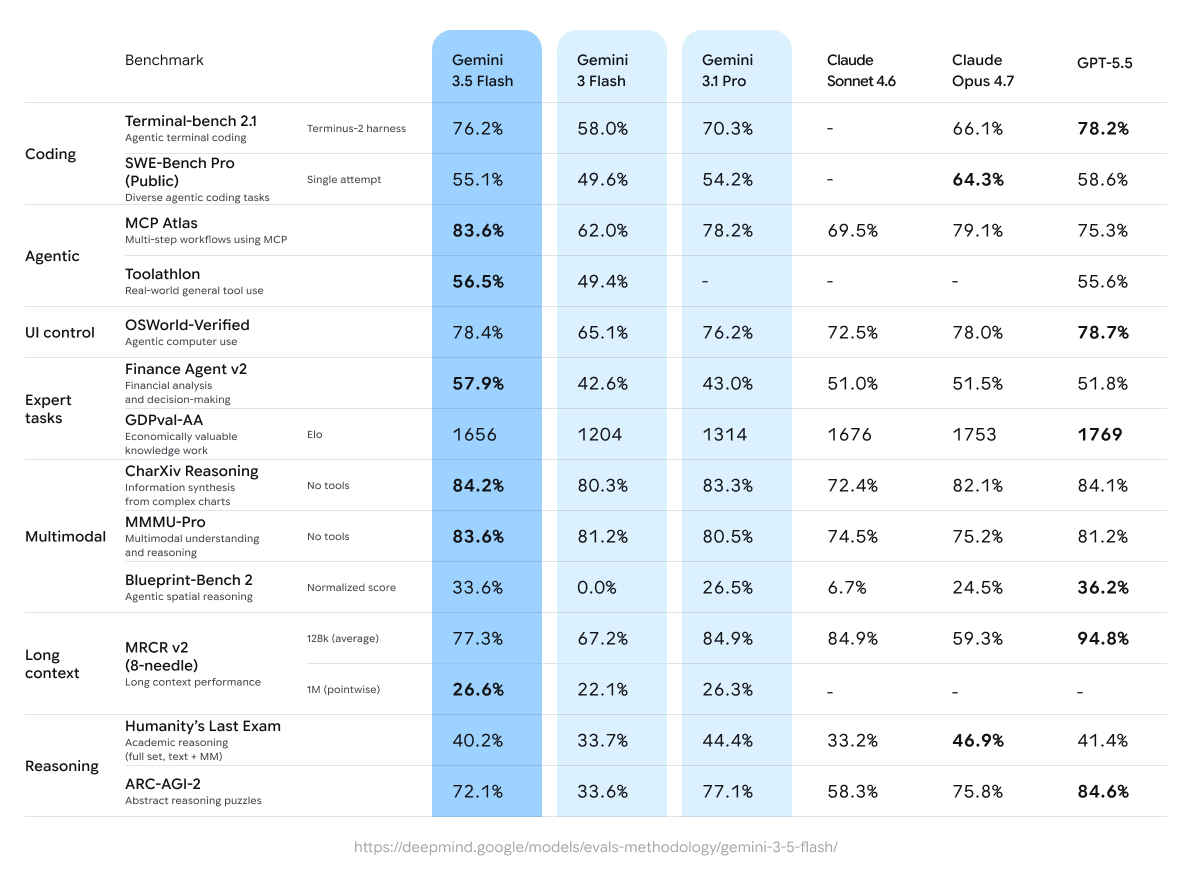
Gemini 3.5 Flash scores 55.1% on SWE-Bench Pro.
Claude Opus 4.7 scores 64.3%.
Not even close.
Google just made a Flash model that beats their own Pro in tool use and agentic tasks.
But on real world coding?
Still 9 points behind Opus 4.7.
GPT 5.5 beats it too at 58.6%.
If this is the model Google needed to make a comeback with, it's not there yet on coding.
Waiting on Gemini 3.5 Pro.
That's where the real test is.

English
@GeminiApp if the new gemini model isnt better then Mythos it's garbage
English

It’s #GoogleIO Day One. Who’s ready to see what’s coming to Gemini?
Livestream starts here at 10am PT: x.com/i/events/20532…
English


@RedPacketSec @CodexReleases Why don’t they just make it to accept Ctf?
English

@berrroo000 @CodexReleases Register for security approval. Simple. It can easily smash CTFs .
English

Codex CLI 0.131.0 is out.
Highlights:
- Python SDK moved to openai-codex / openai_codex, with pinned runtime-generated types, concurrent turn routing, and approval modes
- codex doctor added for support-ready diagnostics across runtime, auth, terminal, network, config, and local state
- TUI now shows blended token usage, permissions/approval mode, and effective workspace roots; responsive Markdown tables added
- @ mentions now search files, directories, plugins, and skills in a unified picker
Complete details in thread ↓

English
@Google @GeminiApp @antigravity @GoogleAIStudio @GoogleDeepMind The new model most be better then gpt 5.5 xhigh model and even mythos
English

Ready, set, #GoogleIO. 🏁
Tune in tomorrow to hear our latest company-wide product updates and AI breakthroughs across Search, @GeminiApp, @Antigravity, @GoogleAIStudio, @GoogleDeepMind and more.
English
SUPSUP retweetledi
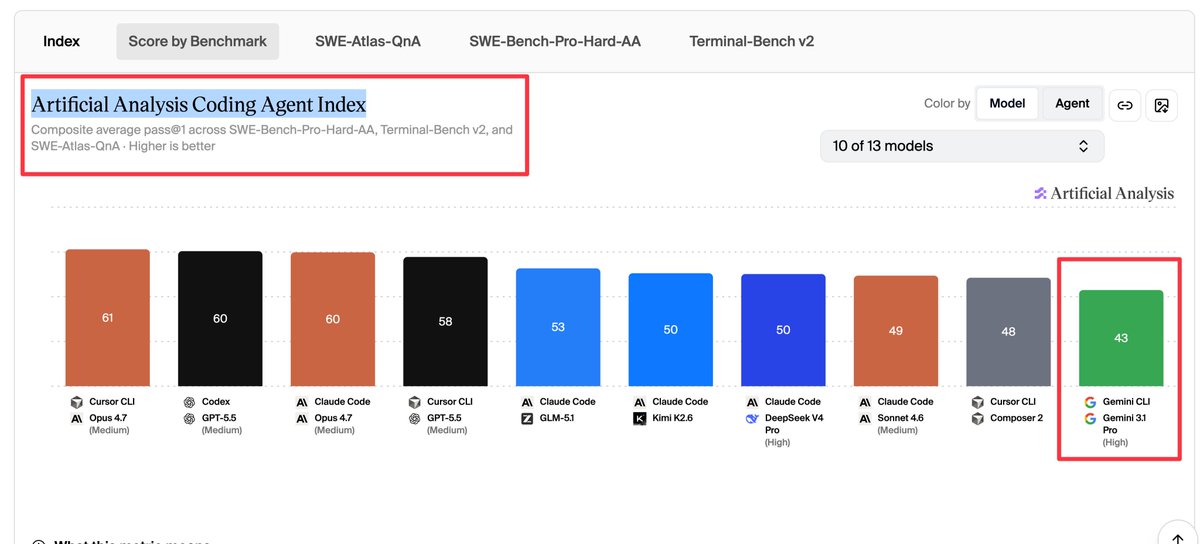
Gemini CLI with Gemini 3.1 Pro scores 43 on the Coding Agent Index.
Dead last. 18 points behind the leader.
Google I/O is tomorrow.
Gemini 3.2 and Gemini 3.5 are both expected to drop.
These models need to be significantly better.
Google has the intelligence.
The model benchmarks prove it.
But the tooling and harness are killing them.
Every other lab has a working coding CLI.
Google's is last place by a mile.
Tomorrow is make or break.
I'm testing both models the second they drop.
English
@Xbow @nicowaisman @moderna_tx Let me let something y’all are playing around. You should make your own AI. You’re just commenting on other AI getting better than you. You’re literally falling every week because because of AI is getting better better you should make your own AI
English

The era of the annual pentest is officially over.
Offense is now autonomous. The lag time between vulnerability discovery and exploit has collapsed.
How should security leaders adapt in the post-Mythos era?
Join XBOW CISO @nicowaisman and @moderna_tx Deputy CISO Farzan Karimi on June 10 for a virtual coffee and chocolate tasting.
We’ll discuss what risk-based security looks like when offensive capability operates at machine speed.
RSVP to claim your spot and your coffee & chocolate kit: bit.ly/42zUvxV
English



@elonmusk @doganuraldesign You should improve the algorithm, I’m getting the same content all the time
English


@NewsFromGoogle @vercel @BusinessInsider If Gemini 3.2 is not better then gpt 5.5 model I would be frustrerad
English

New stat from @vercel's AI Gateway in @BusinessInsider: Gemini 3 Flash is leading across AI models in token usage as of April. 🚀 See more stats on how developers are using our models → goo.gle/4dlBiol
📊via @BusinessInsider
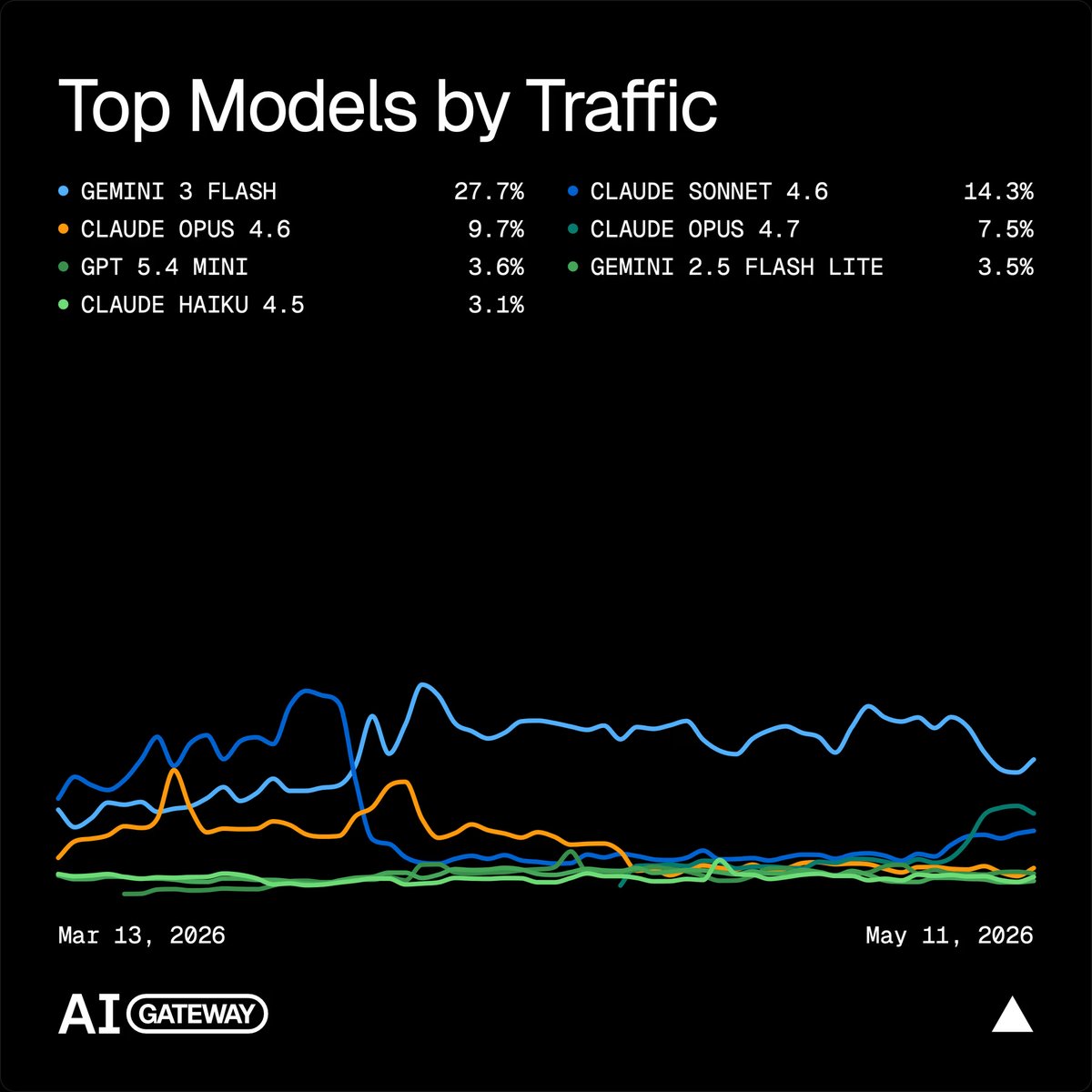
English