
Bertie Vidgen retweetledi

Does training on APEX-Agents dev set generalize beyond the benchmark?
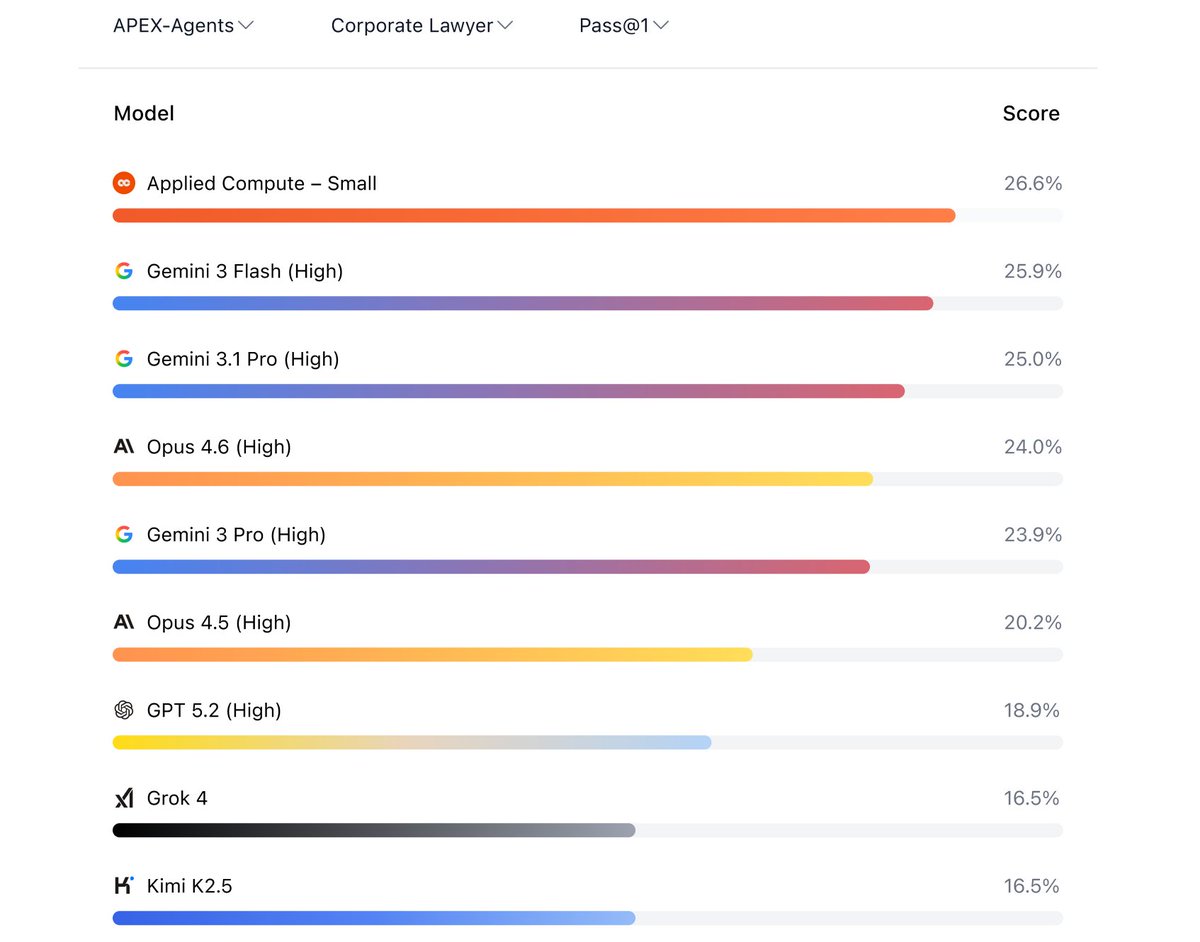
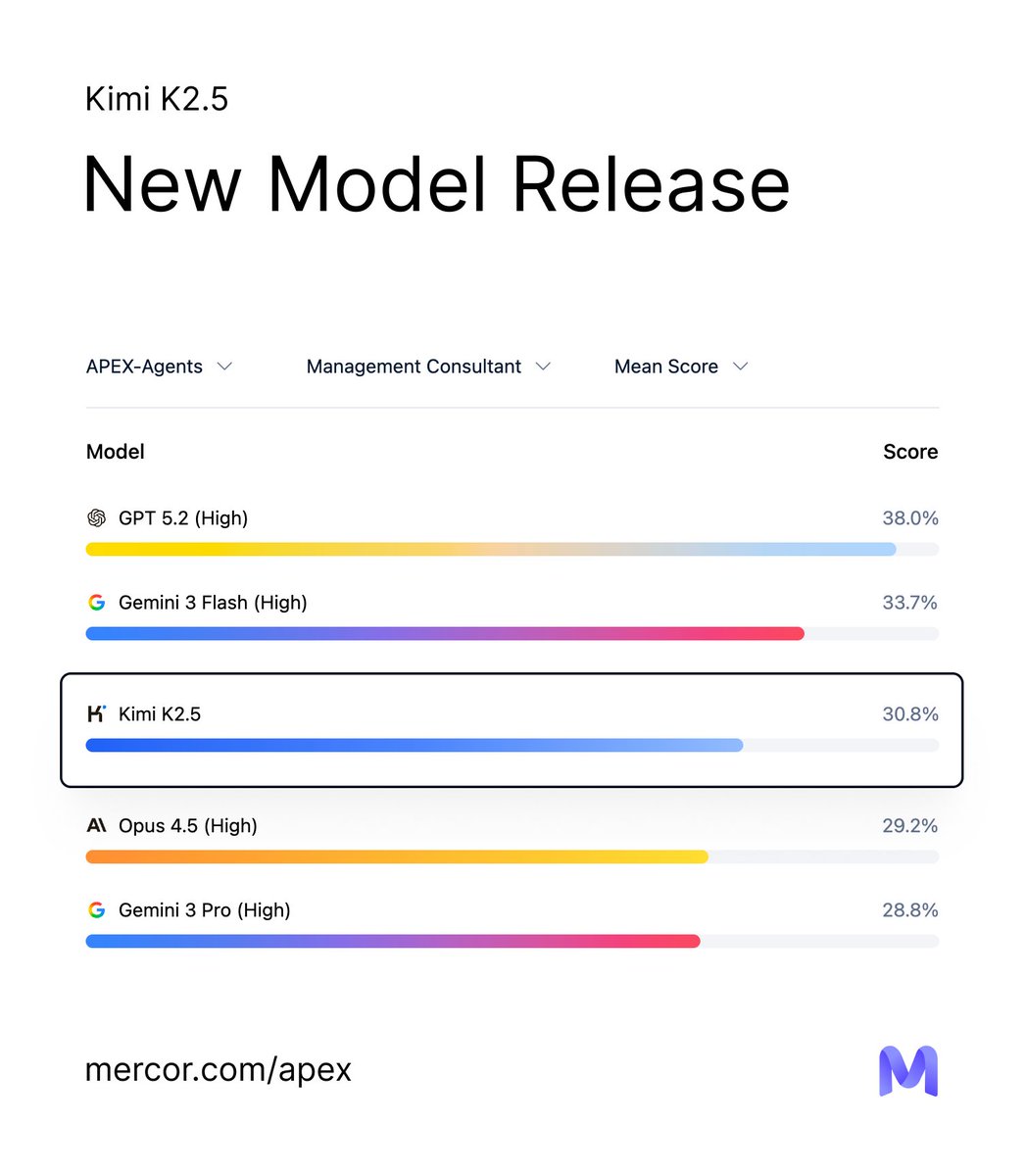
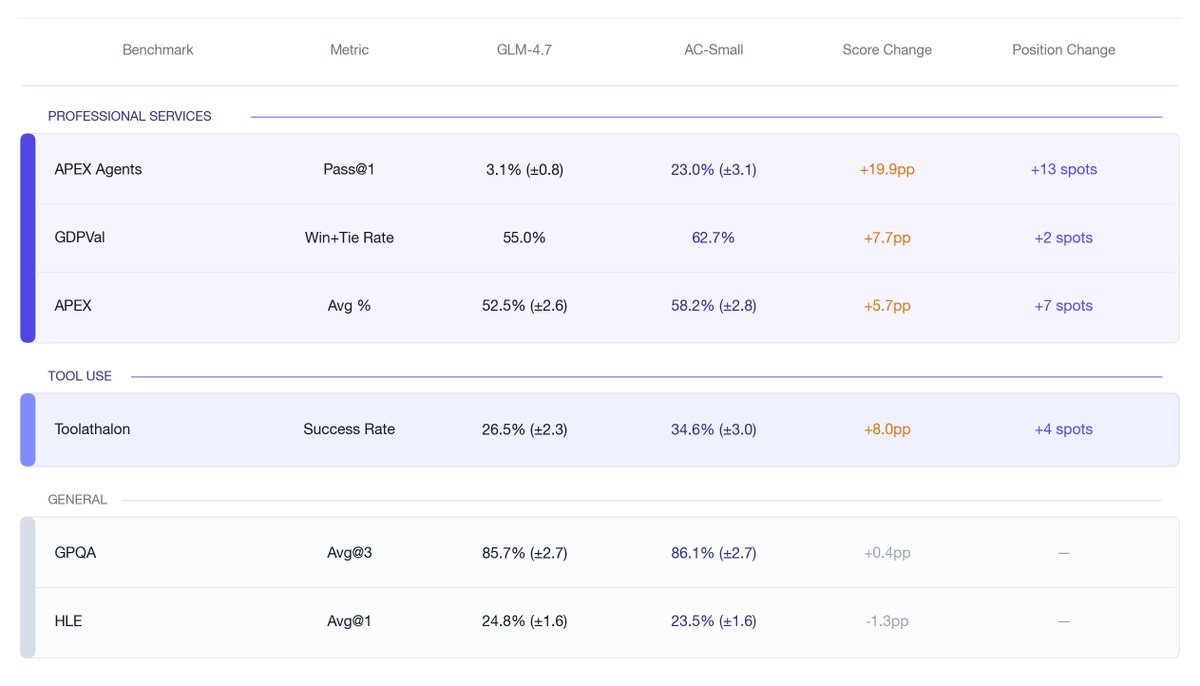
@appliedcompute post-trained GLM-4.7 on ~2,000 expert Mercor tasks and achieved state-of-the-art legal performance on APEX Agents.
We then evaluated the model on other enterprise benchmarks. On GDPVal, AC-Small’s win+tie rate rose from 55.0% to 62.7% (+7.7pp), ranking 5th overall and ahead of Opus 4.5.
English