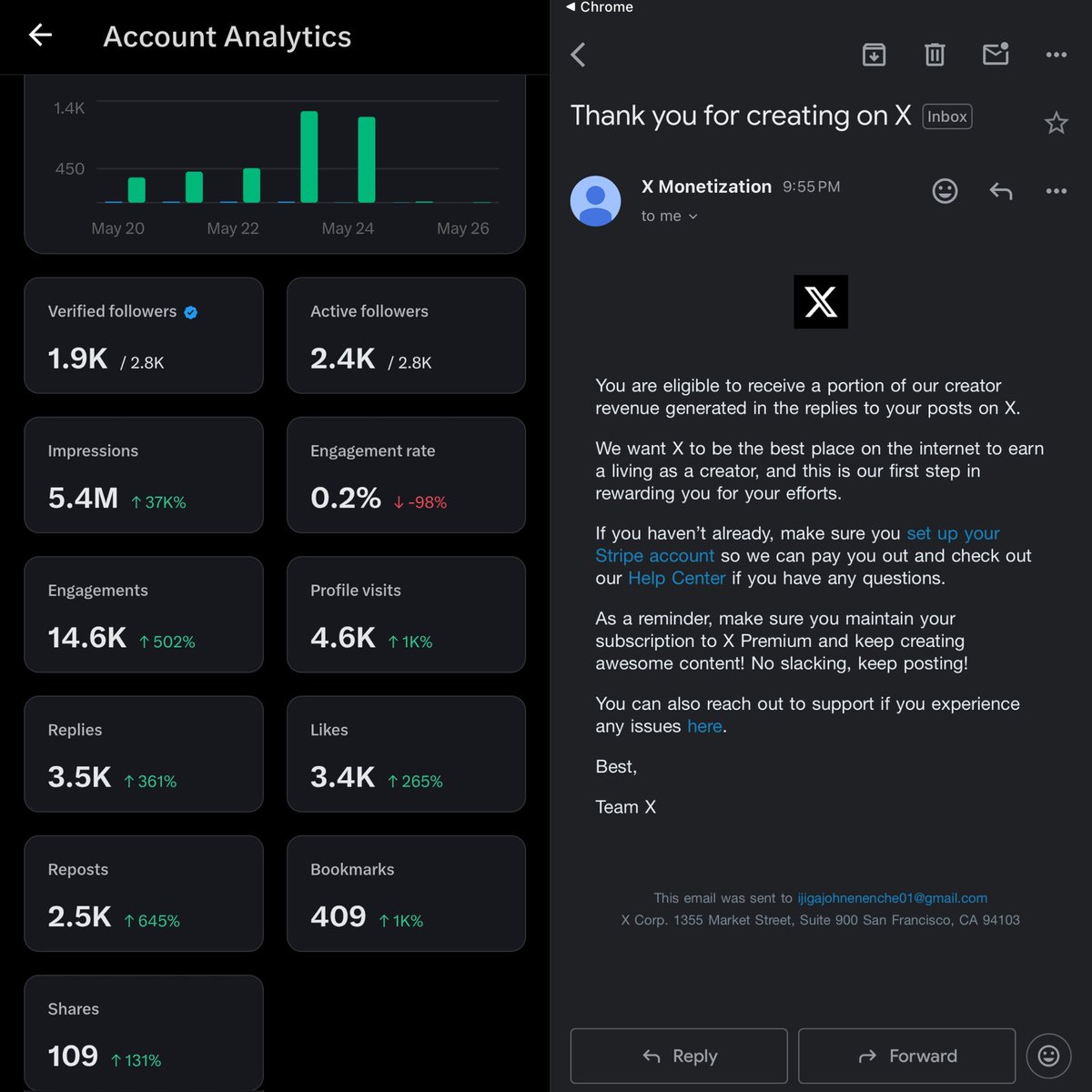
Sabitlenmiş Tweet

I spent weeks building a free AI resume builder that actually beats ATS systems.
Anyone can get an API to return text. The real engineering is everything that happens before and after.
Here is the full architecture stack and the tradeoffs I made building س synapse. 🧵 (1/7)
English