Blair Bilodeau retweetledi

You can’t take our country — and you can’t take our game.
English
Blair Bilodeau
4.1K posts


@blairbilodeau
quant





interesting, and I’ll bookmark the John Hughes paper (link below) for later reading But maximum ignorance probability isn’t always the way. What’s the probability it’ll rain tomorrow? You’ve observed tomorrow 0 times, so frequentism is useless. You need a model. That’s my go-to



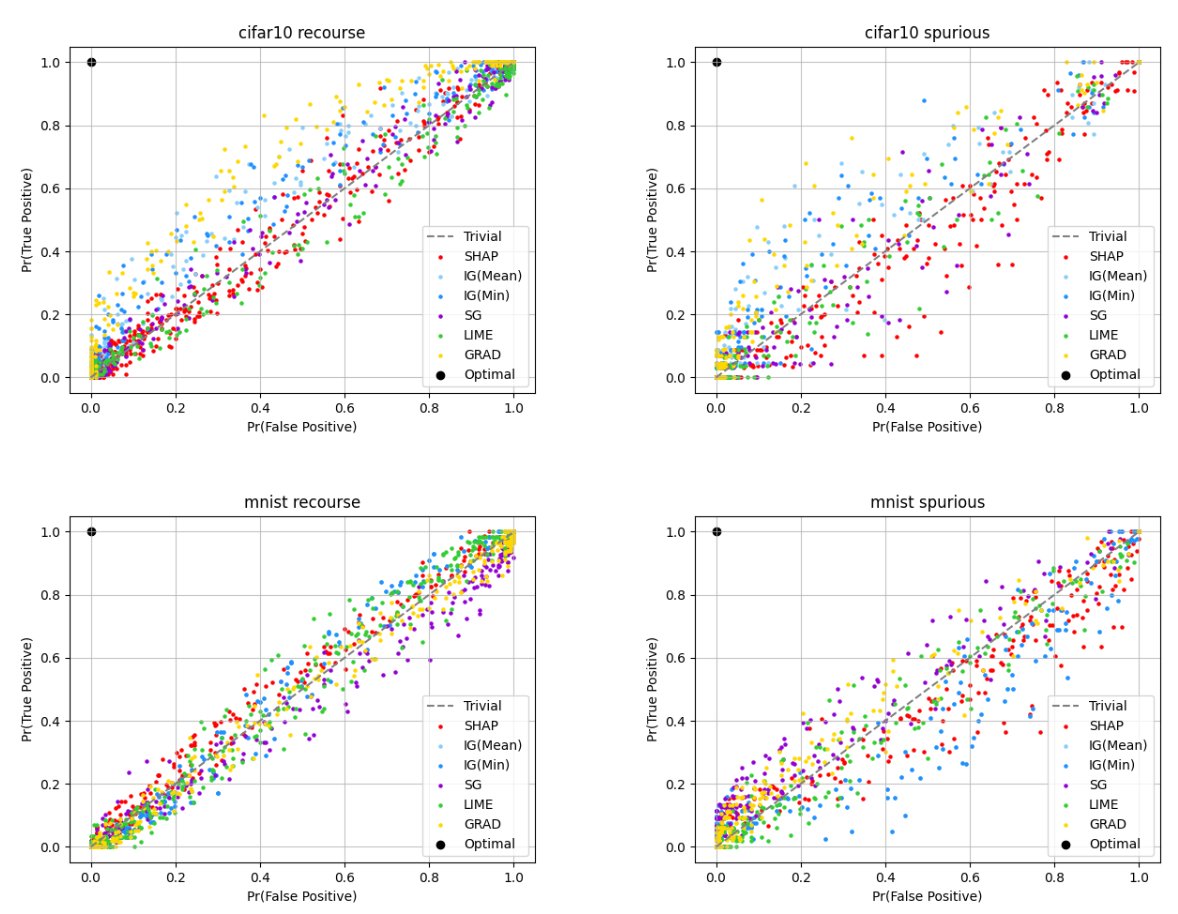
Excited to finally share that "Impossibility Theorems for Feature Attribution" is published in PNAS. TL;DR Methods like SHAP and IG can provably fail to beat random guessing. w/ @natashajaques @PangWeiKoh @_beenkim PNAS: pnas.org/doi/10.1073/pn… arXiv: arxiv.org/abs/2212.11870


Excited to finally share that "Impossibility Theorems for Feature Attribution" is published in PNAS. TL;DR Methods like SHAP and IG can provably fail to beat random guessing. w/ @natashajaques @PangWeiKoh @_beenkim PNAS: pnas.org/doi/10.1073/pn… arXiv: arxiv.org/abs/2212.11870